Abbas Asim, Lee Mark, Shanavas Niloofer, Kovatchev Venelin
School of Computer Science, University of Birmingham, Birmingham, UK.
School of Computer Science, University of Birmingham, Abu Dhabi, United Arab Emirates.
Digit Health. 2024 Dec 19;10:20552076241308987. doi: 10.1177/20552076241308987. eCollection 2024 Jan-Dec.
The study aims to present an active learning approach that automatically extracts clinical concepts from unstructured data and classifies them into explicit categories such as Problem, Treatment, and Test while preserving high precision and recall and demonstrating the approach through experiments using i2b2 public datasets.
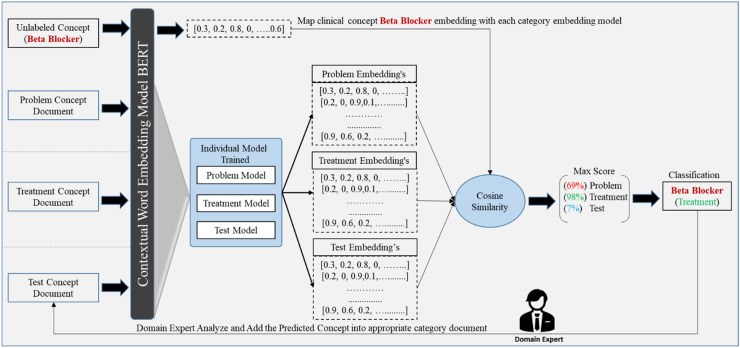
Initially labeled data are acquired from a lexical-based approach in sufficient amounts to perform an active learning process. A contextual word embedding similarity approach is adopted using BERT base variant models such as ClinicalBERT, DistilBERT, and SCIBERT to automatically classify the unlabeled clinical concept into explicit categories. Additionally, deep learning and large language model (LLM) are trained on acquiring label data through active learning.
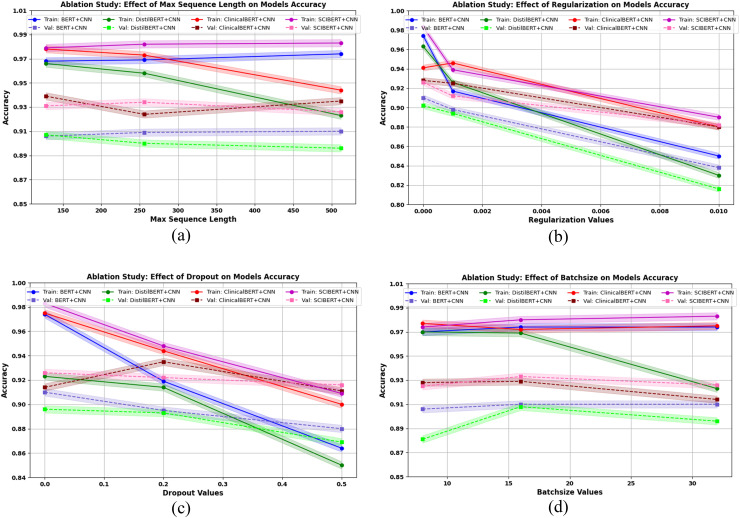
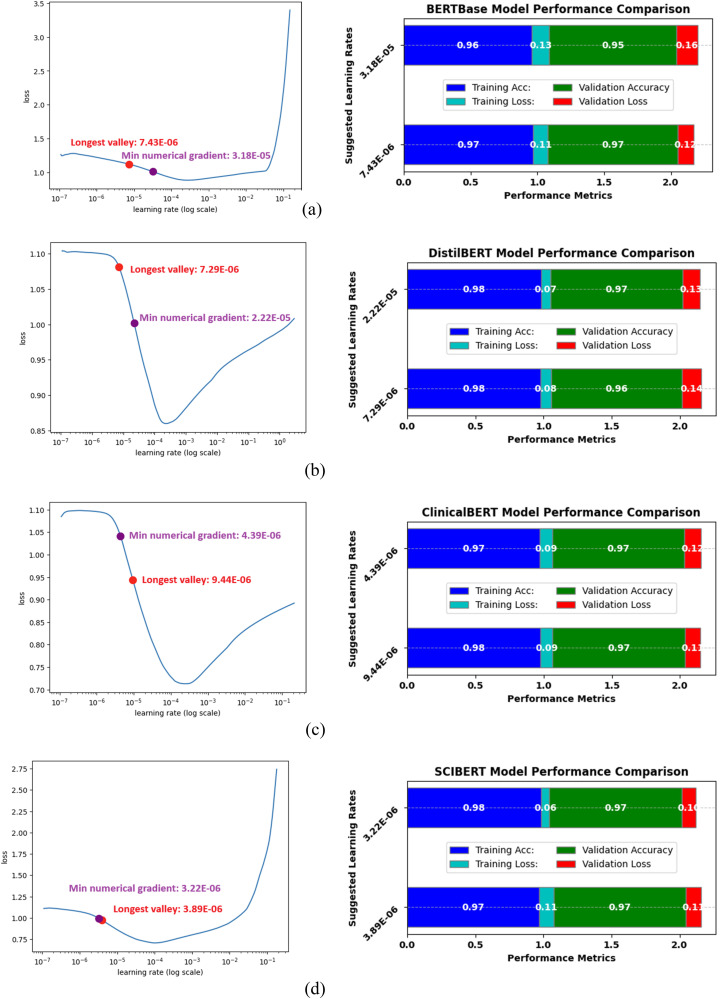
Using i2b2 datasets (426 clinical notes), the lexical-based method achieved precision, recall, and F1-scores of 76%, 70%, and 73%. SCIBERT excelled in active transfer learning, yielding precision of 70.84%, recall of 77.40%, F1-score of 73.97%, and accuracy of 69.30%, surpassing counterpart models. Among deep learning models, convolutional neural networks (CNNs) trained with embeddings (BERTBase, DistilBERT, SCIBERT, ClinicalBERT) achieved training accuracies of 92-95% and testing accuracies of 89-93%. These results were higher compared to other deep learning models. Additionally, we individually evaluated these LLMs; among them, ClinicalBERT achieved the highest performance, with a training accuracy of 98.4% and a testing accuracy of 96%, outperforming the others.
The proposed methodology enhances clinical concept extraction by integrating active learning and models like SCIBERT and CNN. It improves annotation efficiency while maintaining high accuracy, showcasing potential for clinical applications.
本研究旨在提出一种主动学习方法,该方法能从非结构化数据中自动提取临床概念,并将其分类到明确的类别中,如问题、治疗和检查,同时保持高精度和召回率,并通过使用i2b2公共数据集进行实验来展示该方法。
从基于词汇的方法中获取初始标记数据,数量要足以执行主动学习过程。采用上下文词嵌入相似性方法,使用诸如ClinicalBERT、DistilBERT和SCIBERT等BERT基础变体模型,将未标记的临床概念自动分类到明确的类别中。此外,通过主动学习训练深度学习和大语言模型(LLM)以获取标记数据。
使用i2b2数据集(426份临床记录),基于词汇的方法实现了76%的精确率、70%的召回率和73%的F1分数。SCIBERT在主动迁移学习方面表现出色,精确率为70.84%,召回率为77.40%,F1分数为73.97%,准确率为69.30%,超过了同类模型。在深度学习模型中,使用嵌入(BERTBase、DistilBERT、SCIBERT、ClinicalBERT)训练的卷积神经网络(CNN)实现了92 - 95%的训练准确率和89 - 93%的测试准确率。与其他深度学习模型相比,这些结果更高。此外,我们对这些LLM进行了单独评估;其中,ClinicalBERT表现最佳,训练准确率为98.4%,测试准确率为96%,优于其他模型。
所提出的方法通过整合主动学习以及SCIBERT和CNN等模型来增强临床概念提取。它提高了注释效率,同时保持了高精度,展示了临床应用的潜力。