Department of Electrical and Computer Engineering, University of Alberta, Edmonton, Canada.
BMC Bioinformatics. 2009 Dec 13;10:414. doi: 10.1186/1471-2105-10-414.
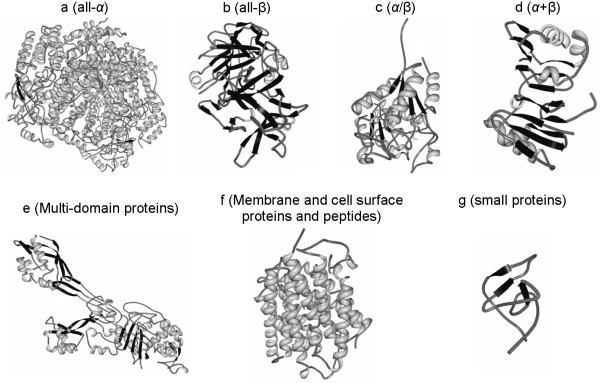
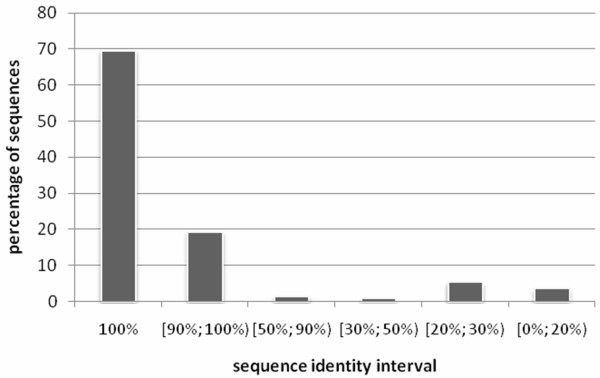
Knowledge of structural class is used by numerous methods for identification of structural/functional characteristics of proteins and could be used for the detection of remote homologues, particularly for chains that share twilight-zone similarity. In contrast to existing sequence-based structural class predictors, which target four major classes and which are designed for high identity sequences, we predict seven classes from sequences that share twilight-zone identity with the training sequences.
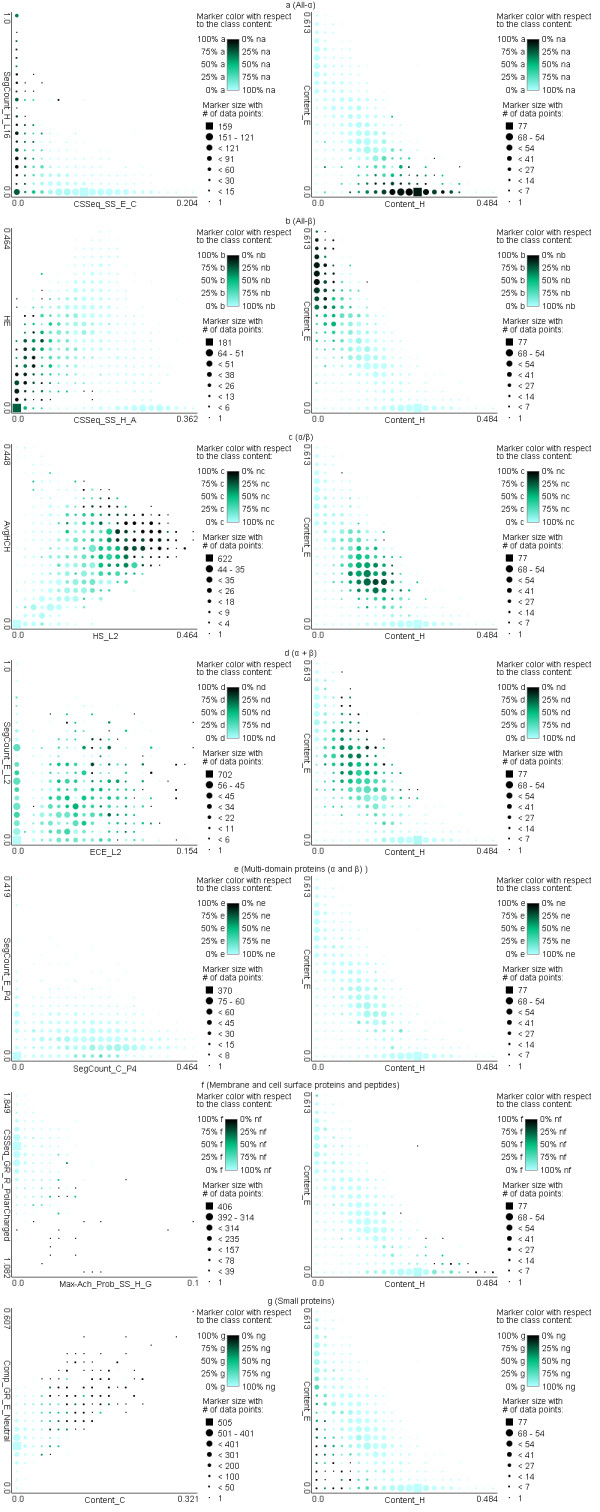
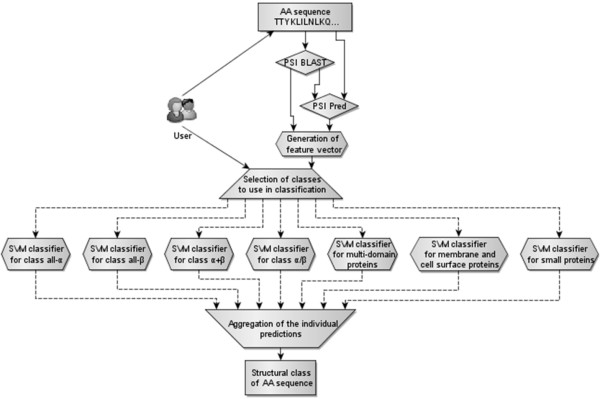
The proposed MODular Approach to Structural class prediction (MODAS) method is unique as it allows for selection of any subset of the classes. MODAS is also the first to utilize a novel, custom-built feature-based sequence representation that combines evolutionary profiles and predicted secondary structure. The features quantify information relevant to the definition of the classes including conservation of residues and arrangement and number of helix/strand segments. Our comprehensive design considers 8 feature selection methods and 4 classifiers to develop Support Vector Machine-based classifiers that are tailored for each of the seven classes. Tests on 5 twilight-zone and 1 high-similarity benchmark datasets and comparison with over two dozens of modern competing predictors show that MODAS provides the best overall accuracy that ranges between 80% and 96.7% (83.5% for the twilight-zone datasets), depending on the dataset. This translates into 19% and 8% error rate reduction when compared against the best performing competing method on two largest datasets. The proposed predictor provides accurate predictions at 58% accuracy for membrane proteins class, which is not considered by majority of existing methods, in spite that this class accounts for only 2% of the data. Our predictive model is analyzed to demonstrate how and why the input features are associated with the corresponding classes.
The improved predictions stem from the novel features that express collocation of the secondary structure segments in the protein sequence and that combine evolutionary and secondary structure information. Our work demonstrates that conservation and arrangement of the secondary structure segments predicted along the protein chain can successfully predict structural classes which are defined based on the spatial arrangement of the secondary structures. A web server is available at http://biomine.ece.ualberta.ca/MODAS/.
许多方法都利用结构类别知识来识别蛋白质的结构/功能特征,并且可以用于检测远程同源物,特别是对于共享黄昏区相似性的链。与现有的基于序列的结构类别预测器不同,后者针对四个主要类别,并且专为高相似度序列设计,我们从与训练序列具有黄昏区相似度的序列中预测七个类别。
所提出的 MODular Approach to Structural class prediction (MODAS) 方法是独一无二的,因为它允许选择任何类别的子集。MODAS 也是第一个利用新颖的、定制的基于特征的序列表示,该表示结合了进化轮廓和预测的二级结构。这些特征量化了与类别定义相关的信息,包括残基的保守性以及螺旋/链段的排列和数量。我们的综合设计考虑了 8 种特征选择方法和 4 种分类器,以开发针对每个七个类别的基于支持向量机的分类器。在 5 个黄昏区和 1 个高相似度基准数据集上进行测试,并与 20 多个现代竞争预测器进行比较,结果表明 MODAS 提供了最佳的整体准确性,范围在 80%到 96.7%之间(对于黄昏区数据集为 83.5%),具体取决于数据集。与两个最大数据集上表现最好的竞争方法相比,这分别转化为 19%和 8%的错误率降低。尽管该类别的数据仅占 2%,但所提出的预测器仍能以 58%的准确率准确预测膜蛋白类,这是大多数现有方法所不考虑的。我们对预测模型进行了分析,以展示输入特征如何以及为何与相应类别相关联。
改进的预测源于新颖的特征,这些特征表达了蛋白质序列中二级结构片段的排列,并结合了进化和二级结构信息。我们的工作表明,沿蛋白质链预测的二级结构片段的保守性和排列可以成功预测基于二级结构空间排列定义的结构类别。一个网络服务器可在 http://biomine.ece.ualberta.ca/MODAS/ 上获得。