Changchun Institute of Applied Chemistry, Chinese Academy of Sciences, Changchun, PR China.
BMC Genomics. 2010 May 10;11:289. doi: 10.1186/1471-2164-11-289.
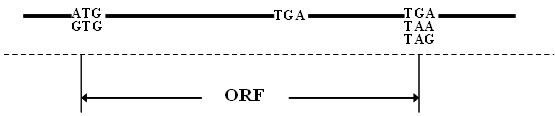
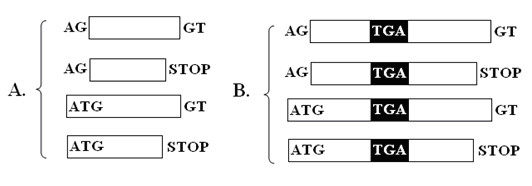
Computational methods for identifying selenoproteins have been developed rapidly in recent years. However, it is still difficult to identify the open reading frame (ORF) of eukaryotic selenoprotein gene, because the TGA codon for a selenocysteine (Sec) residue in the active centre of selenoprotein is traditionally a terminal signal of protein translation. Although the identification of selenoproteins from genomes through bioinformatics methods has been conducted in bacteria, unicellular eukaryotes, insects and several vertebrates, only a few results have been reported on the ancient chordate selenoproteins.
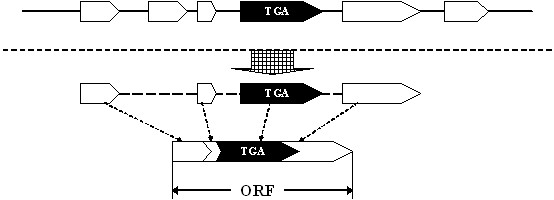
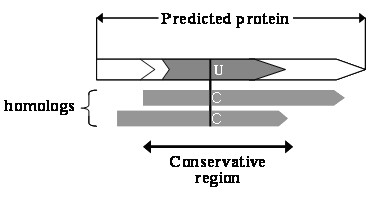
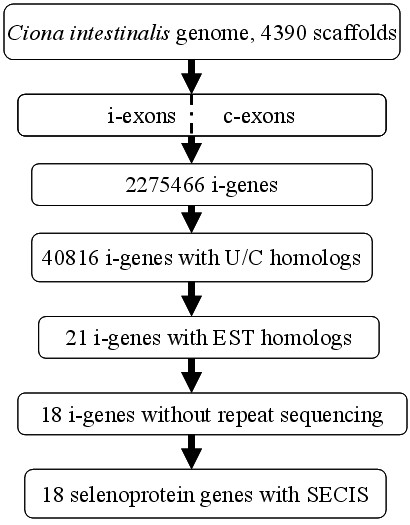
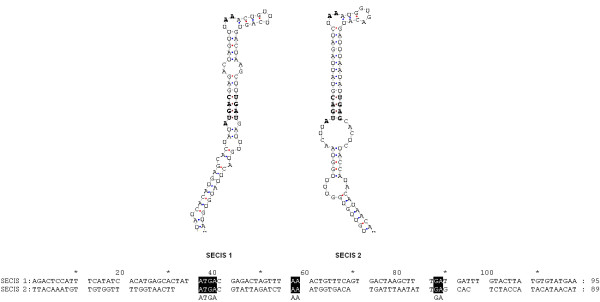
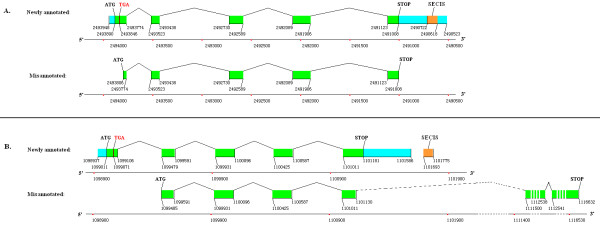
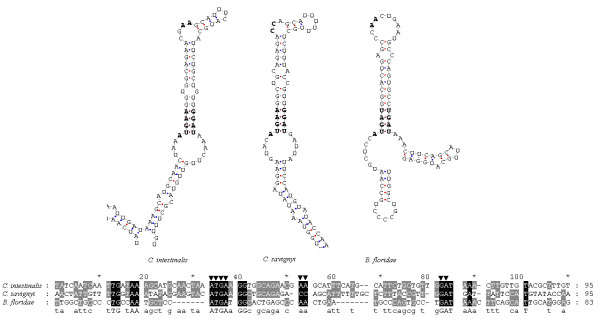
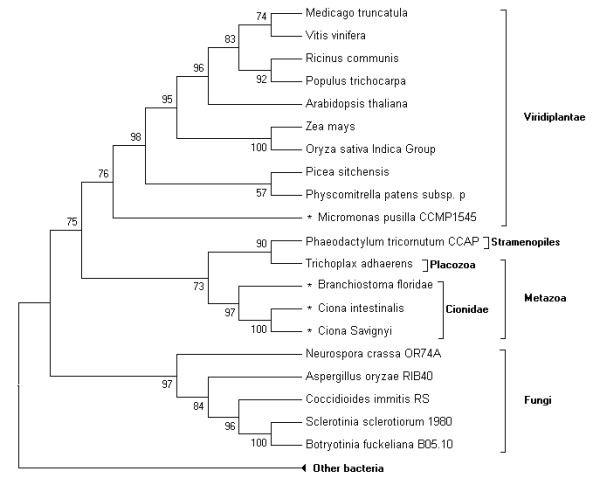
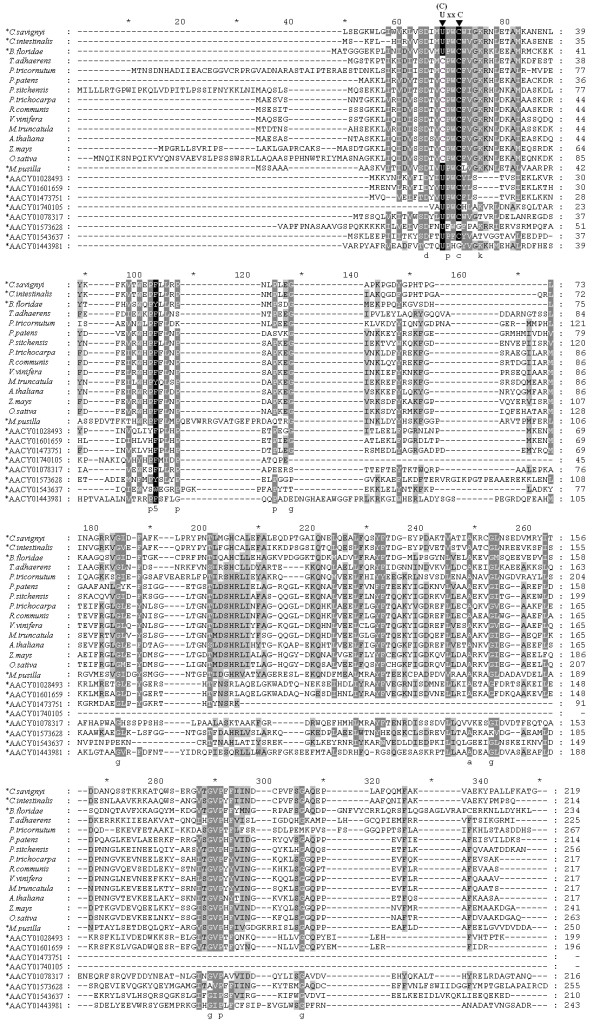
A gene assembly algorithm SelGenAmic has been constructed and presented in this study for identifying selenoprotein genes from eukaryotic genomes. A method based on this algorithm was developed to build an optimal TGA-containing-ORF for each TGA in a genome, followed by protein similarity analysis through conserved sequence alignments to screen out selenoprotein genes form these ORFs. This method improved the sensitivity of detecting selenoproteins from a genome due to the design that all TGAs in the genome were investigated for its possibility of decoding as a Sec residue. Using this method, eighteen selenoprotein genes were identified from the genome of Ciona intestinalis, leading to its member of selenoproteome up to 19. Among them a selenoprotein W gene was found to have two SECIS elements in the 3'-untranslated region. Additionally, the disulfide bond formation protein A (DsbA) was firstly identified as a selenoprotein in the ancient chordates of Ciona intestinalis, Ciona savignyi and Branchiostoma floridae, while selenoprotein DsbAs had only been found in bacteria and green algae before.
The method based on SelGenAmic algorithm is capable of identifying eukaryotic selenoprotein genes from their genomes. Application of this method to Ciona intestinalis proves its successes in finding Sec-decoding TGA from large-scale eukaryotic genome sequences, which fills the gap in our knowledge on the ancient chordate selenoproteins.
近年来,用于鉴定硒蛋白的计算方法发展迅速。然而,由于在硒蛋白活性中心的 TGA 密码子传统上是蛋白质翻译的终止信号,因此仍然难以鉴定真核生物硒蛋白基因的开放阅读框 (ORF)。尽管通过生物信息学方法从细菌、单细胞真核生物、昆虫和几种脊椎动物的基因组中鉴定了硒蛋白,但关于古老脊索动物硒蛋白的报道很少。
本研究构建并提出了一种基因组装算法 SelGenAmic,用于从真核基因组中鉴定硒蛋白基因。基于该算法的方法用于构建每个基因组中 TGA 的最佳含 TGA-ORF,然后通过保守序列比对进行蛋白质相似性分析,从这些 ORF 中筛选出硒蛋白基因。由于该设计考虑了基因组中所有 TGA 作为 Sec 残基解码的可能性,因此该方法提高了从基因组中检测硒蛋白的灵敏度。使用该方法,从 Ciona intestinalis 的基因组中鉴定出 18 个硒蛋白基因,使其硒蛋白组的成员增加到 19 个。其中一个硒蛋白 W 基因在 3'-非翻译区发现有两个 SECIS 元件。此外,首次在古老的脊索动物 Ciona intestinalis、Ciona savignyi 和 Branchiostoma floridae 中鉴定到 DsbA 作为一种硒蛋白,而 DsbA 硒蛋白之前仅在细菌和绿藻中发现过。
基于 SelGenAmic 算法的方法能够从基因组中鉴定出真核硒蛋白基因。该方法在 Ciona intestinalis 中的应用证明了它在从大规模真核基因组序列中寻找 Sec 解码 TGA 方面的成功,填补了我们对古老脊索动物硒蛋白认识的空白。