Department of Plant Systems Biology, VIB, B-9052 Ghent, Belgium.
BMC Evol Biol. 2010 Aug 10;10:244. doi: 10.1186/1471-2148-10-244.
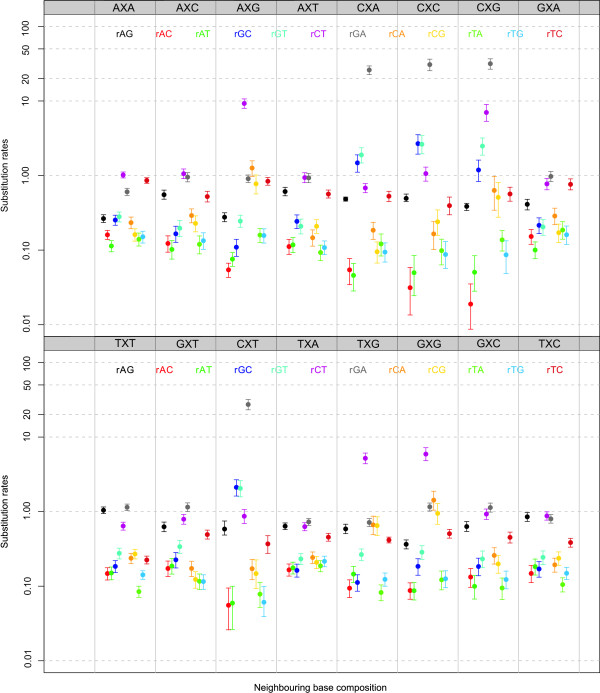
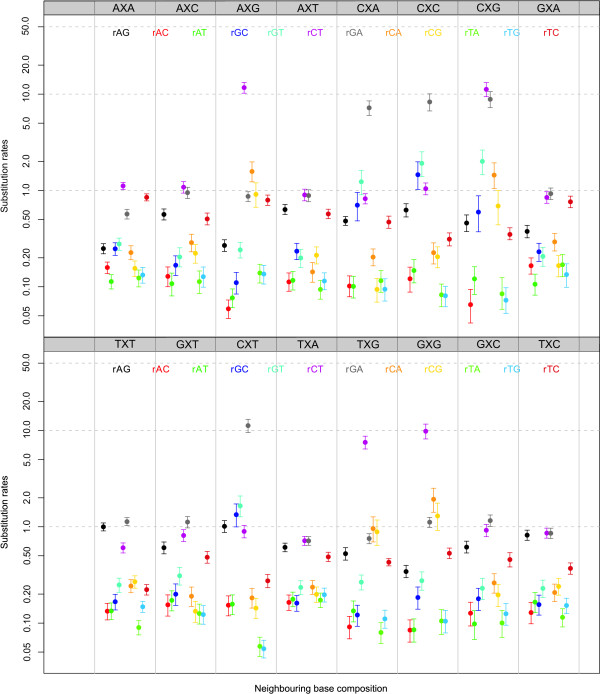
Recent approaches for context-dependent evolutionary modelling assume that the evolution of a given site depends upon its ancestor and that ancestor's immediate flanking sites. Because such dependency pattern cannot be imposed on the root sequence, we consider the use of different orders of Markov chains to model dependence at the ancestral root sequence. Root distributions which are coupled to the context-dependent model across the underlying phylogenetic tree are deemed more realistic than decoupled Markov chains models, as the evolutionary process is responsible for shaping the composition of the ancestral root sequence.
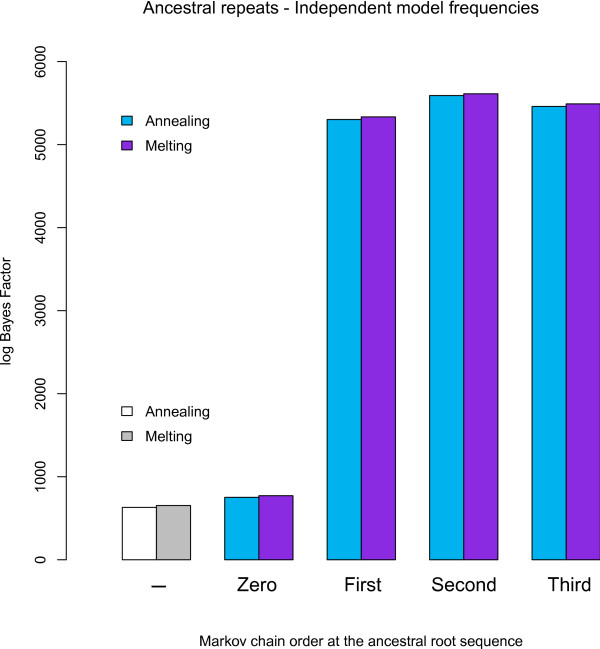
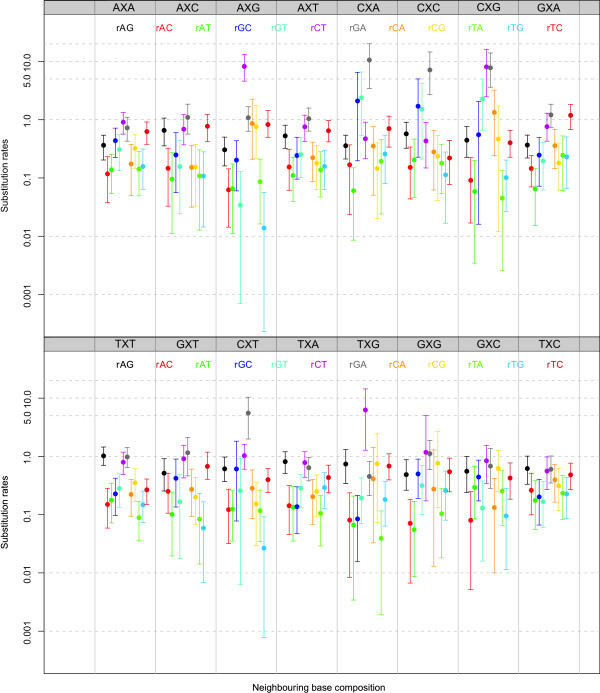
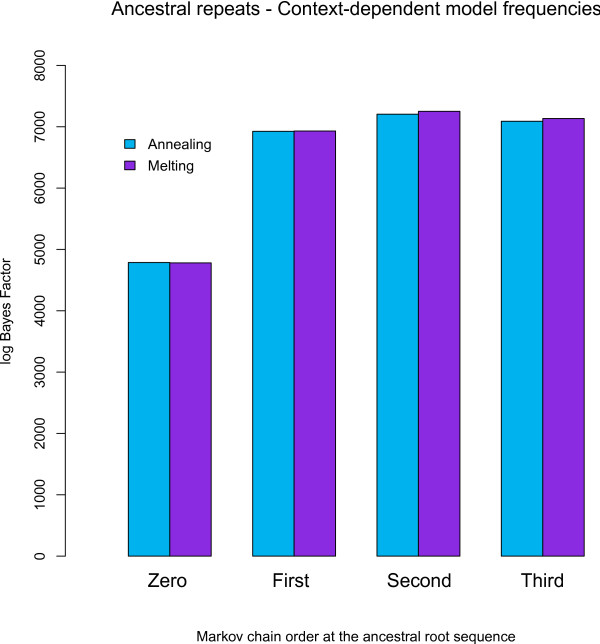
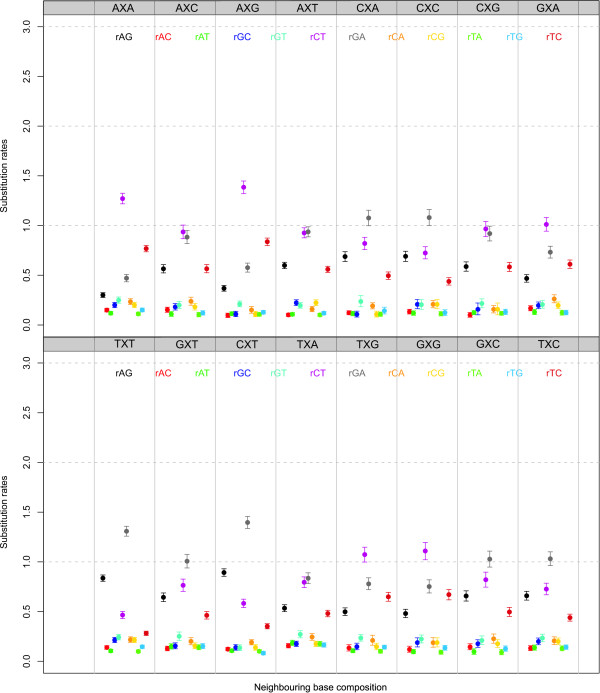
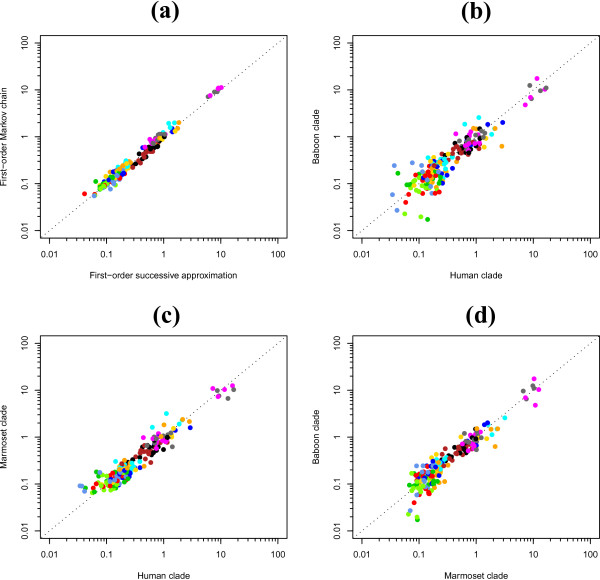
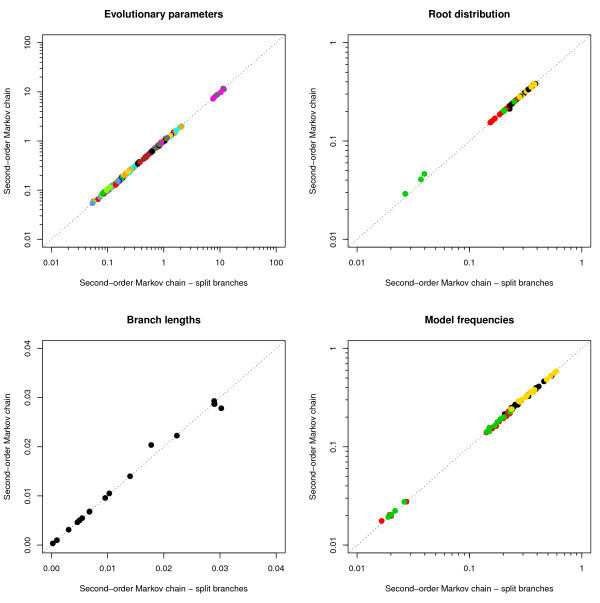
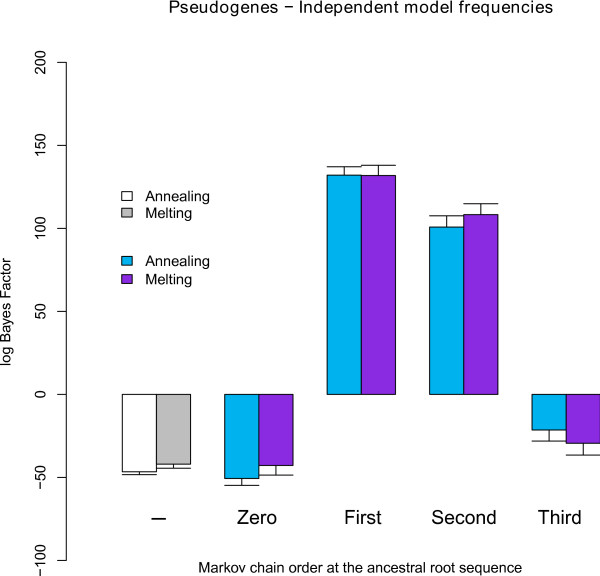
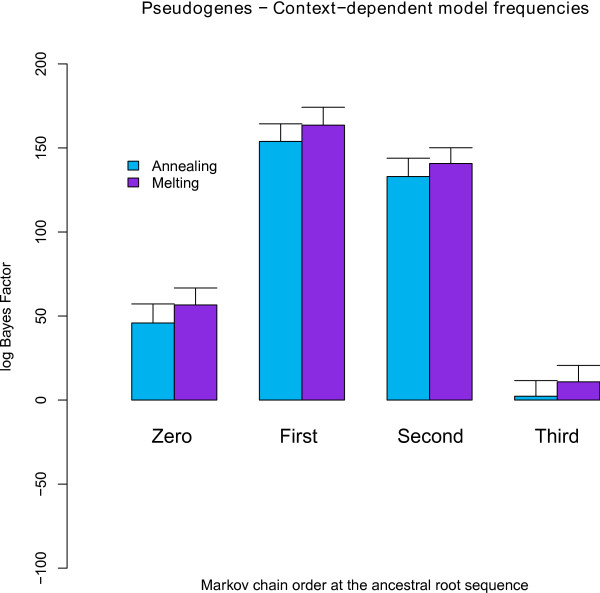
We find strong support, in terms of Bayes Factors, for using a second-order Markov chain at the ancestral root sequence along with a context-dependent model throughout the remainder of the phylogenetic tree in an ancestral repeats dataset, and for using a first-order Markov chain at the ancestral root sequence in a pseudogene dataset. Relaxing the assumption of a single context-independent set of independent model frequencies as presented in previous work, yields a further drastic increase in model fit. We show that the substitution rates associated with the CpG-methylation-deamination process can be modelled through context-dependent model frequencies and that their accuracy depends on the (order of the) Markov chain imposed at the ancestral root sequence. In addition, we provide evidence that this approach (which assumes that root distribution and evolutionary model are decoupled) outperforms an approach inspired by the work of Arndt et al., where the root distribution is coupled to the evolutionary model. We show that the continuous-time approximation of Hwang and Green has stronger support in terms of Bayes Factors, but the parameter estimates show minimal differences.
We show that the combination of a dependency scheme at the ancestral root sequence and a context-dependent evolutionary model across the remainder of the tree allows for accurate estimation of the model's parameters. The different assumptions tested in this manuscript clearly show that designing accurate context-dependent models is a complex process, with many different assumptions that require validation. Further, these assumptions are shown to change across different datasets, making the search for an adequate model for a given dataset quite challenging.
最近的语境相关进化模型方法假设给定位置的进化取决于其祖先及其祖先的直接侧翼位置。由于这种依赖模式不能强加于根序列,因此我们考虑使用不同阶的马尔可夫链来对祖先根序列的依赖关系进行建模。在基础系统发育树中与语境相关模型耦合的根分布被认为比解耦的马尔可夫链模型更现实,因为进化过程负责塑造祖先根序列的组成。
在祖先重复数据集的根序列中使用二阶马尔可夫链和语境相关模型,在假基因数据集的根序列中使用一阶马尔可夫链,我们发现了很强的支持,这是基于贝叶斯因子的。放宽之前工作中提出的单个独立模型频率的语境独立集的假设,会导致模型拟合度的进一步大幅提高。我们表明,与 CpG-甲基化脱氨酶过程相关的取代率可以通过语境相关模型频率来建模,并且其准确性取决于在祖先根序列上施加的(阶数的)马尔可夫链。此外,我们提供了证据表明,这种方法(假设根分布和进化模型是解耦的)优于受 Arndt 等人工作启发的方法,其中根分布与进化模型耦合。我们表明,Hwang 和 Green 的连续时间逼近在贝叶斯因子方面具有更强的支持,但参数估计显示出最小的差异。
我们表明,在祖先根序列上的依赖方案和在树的其余部分的语境相关进化模型的组合允许对模型参数进行准确估计。本文测试的不同假设清楚地表明,设计准确的语境相关模型是一个复杂的过程,有许多不同的假设需要验证。此外,这些假设在不同的数据集之间发生变化,使得为给定数据集寻找合适的模型变得极具挑战性。