Artificial Intelligence Research Laboratory, Department of Computer Science,Iowa State University, Ames, IA 50010, USA.
BMC Bioinformatics. 2010 Oct 26;11 Suppl 8(Suppl 8):S6. doi: 10.1186/1471-2105-11-S8-S6.
Determination of protein subcellular localization plays an important role in understanding protein function. Knowledge of the subcellular localization is also essential for genome annotation and drug discovery. Supervised machine learning methods for predicting the localization of a protein in a cell rely on the availability of large amounts of labeled data. However, because of the high cost and effort involved in labeling the data, the amount of labeled data is quite small compared to the amount of unlabeled data. Hence, there is a growing interest in developing semi-supervised methods for predicting protein subcellular localization from large amounts of unlabeled data together with small amounts of labeled data.
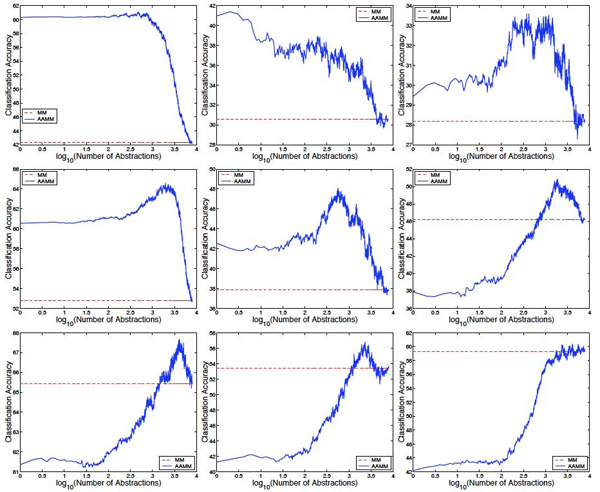
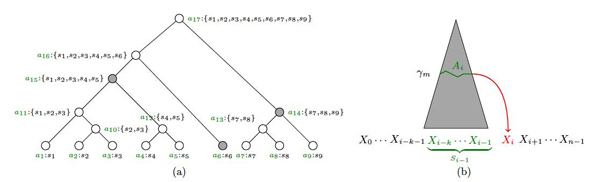
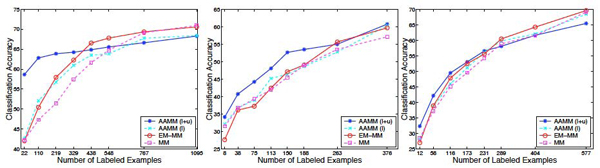
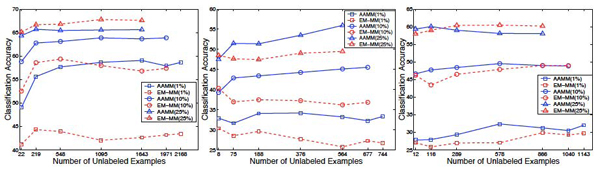
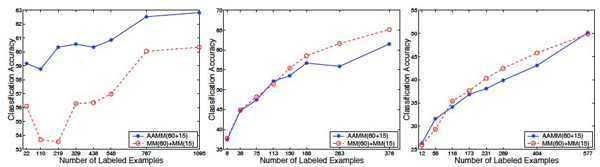
In this paper, we present an Abstraction Augmented Markov Model (AAMM) based approach to semi-supervised protein subcellular localization prediction problem. We investigate the effectiveness of AAMMs in exploiting unlabeled data. We compare semi-supervised AAMMs with: (i) Markov models (MMs) (which do not take advantage of unlabeled data); (ii) an expectation maximization (EM); and (iii) a co-training based approaches to semi-supervised training of MMs (that make use of unlabeled data).
The results of our experiments on three protein subcellular localization data sets show that semi-supervised AAMMs: (i) can effectively exploit unlabeled data; (ii) are more accurate than both the MMs and the EM based semi-supervised MMs; and (iii) are comparable in performance, and in some cases outperform, the co-training based semi-supervised MMs.
确定蛋白质的亚细胞定位在理解蛋白质功能方面起着重要作用。对亚细胞定位的了解对于基因组注释和药物发现也是必不可少的。用于预测蛋白质在细胞中定位的有监督机器学习方法依赖于大量标记数据的可用性。然而,由于标记数据的成本和工作量都很高,与未标记数据相比,标记数据的数量非常少。因此,人们越来越感兴趣的是开发从大量未标记数据和少量标记数据中预测蛋白质亚细胞定位的半监督方法。
本文提出了一种基于抽象增强马尔可夫模型(AAMM)的半监督蛋白质亚细胞定位预测方法。我们研究了 AAMM 在利用未标记数据方面的有效性。我们将半监督 AAMM 与以下方法进行了比较:(i)马尔可夫模型(MM)(不利用未标记数据);(ii)期望最大化(EM);以及(iii)基于协同训练的 MM 半监督训练方法(利用未标记数据)。
我们在三个蛋白质亚细胞定位数据集上的实验结果表明,半监督 AAMM:(i)可以有效地利用未标记数据;(ii)比 MM 和基于 EM 的半监督 MM 更准确;(iii)在性能上相当,在某些情况下优于基于协同训练的半监督 MM。