Martin Stéphanie, Brunner Peter, Holdgraf Chris, Heinze Hans-Jochen, Crone Nathan E, Rieger Jochem, Schalk Gerwin, Knight Robert T, Pasley Brian N
Helen Wills Neuroscience Institute, University of California Berkeley, CA, USA ; Department of Bioengineering, École Polytechnique Fédérale de Lausanne Lausanne, Switzerland.
New York State Department of Health, Wadsworth Center Albany, NY, USA ; Department of Neurology, Albany Medical College Albany, NY, USA.
Front Neuroeng. 2014 May 27;7:14. doi: 10.3389/fneng.2014.00014. eCollection 2014.
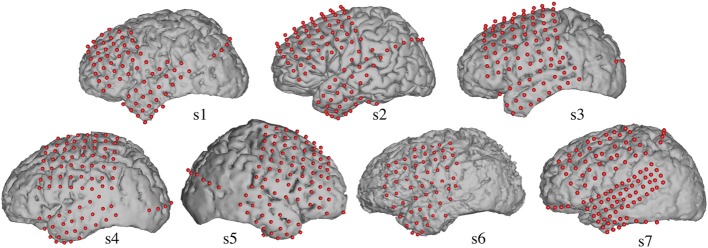
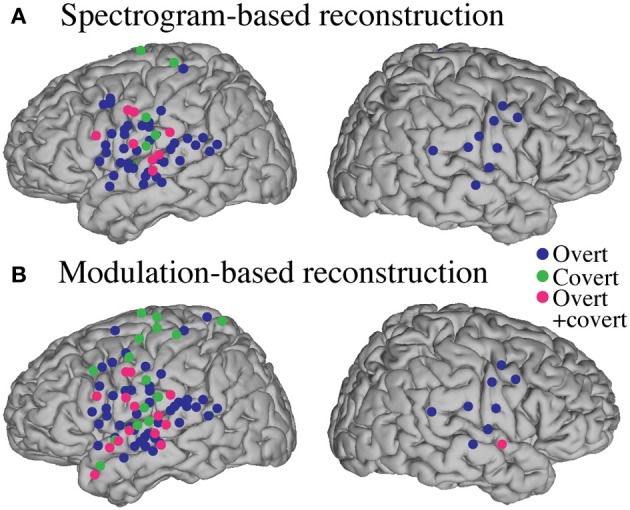
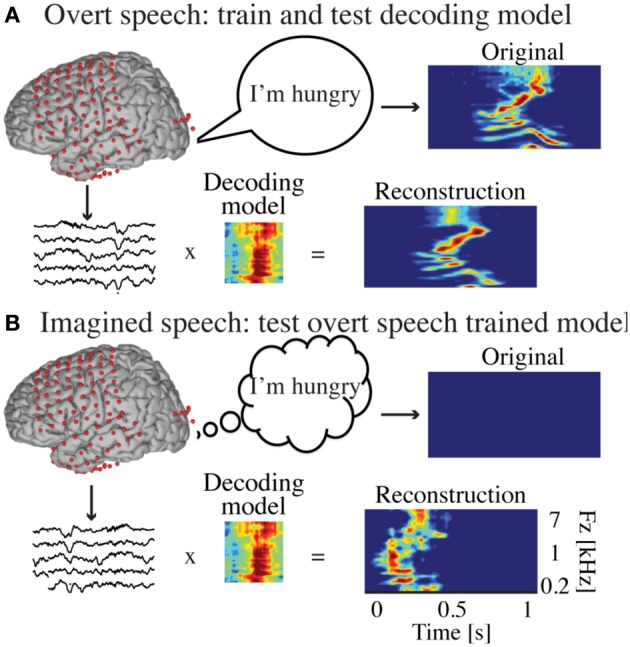
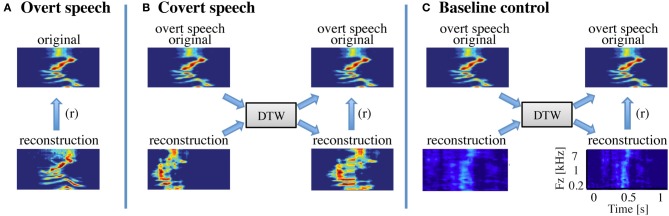
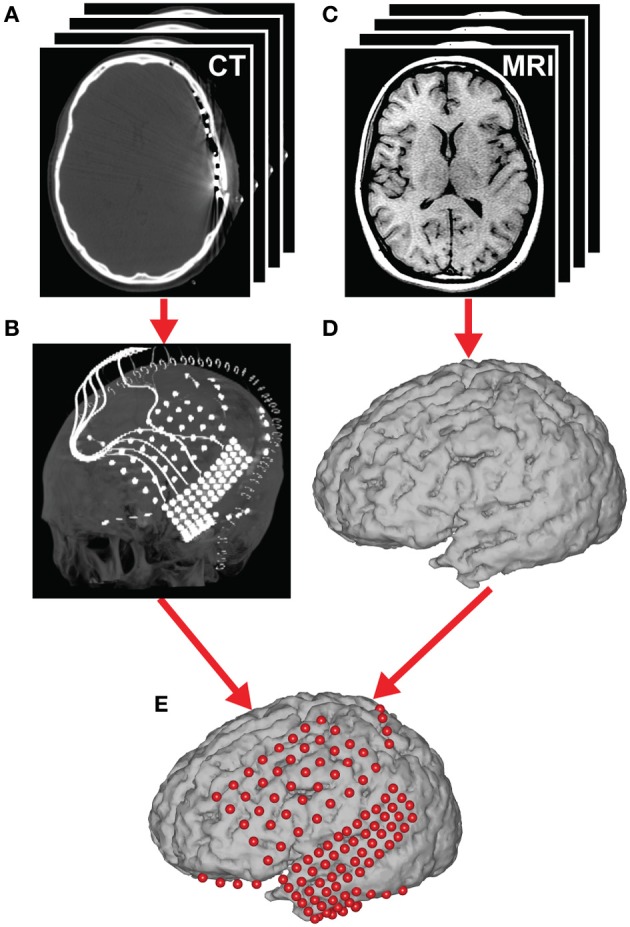
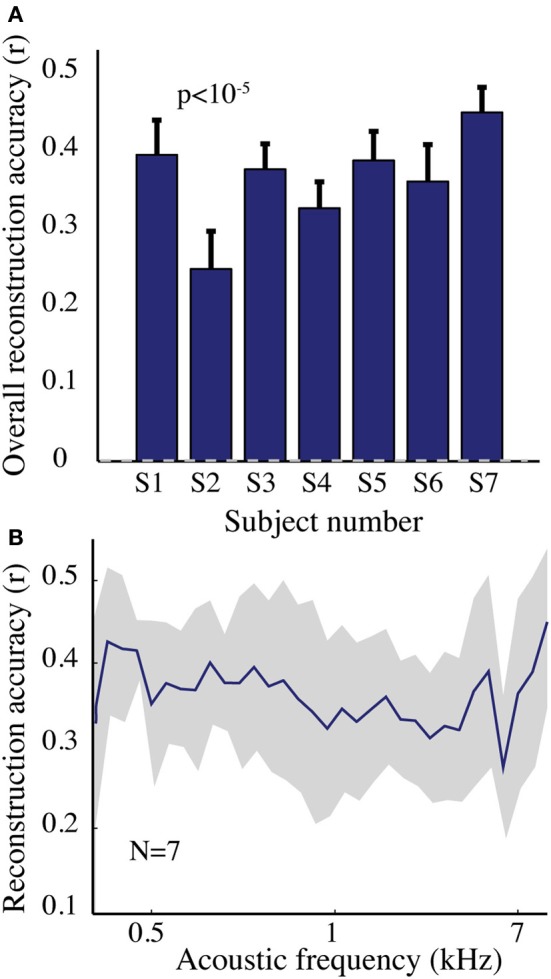
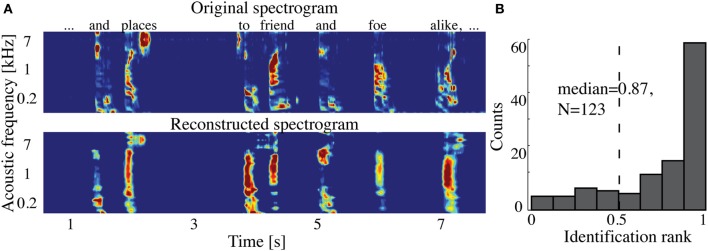
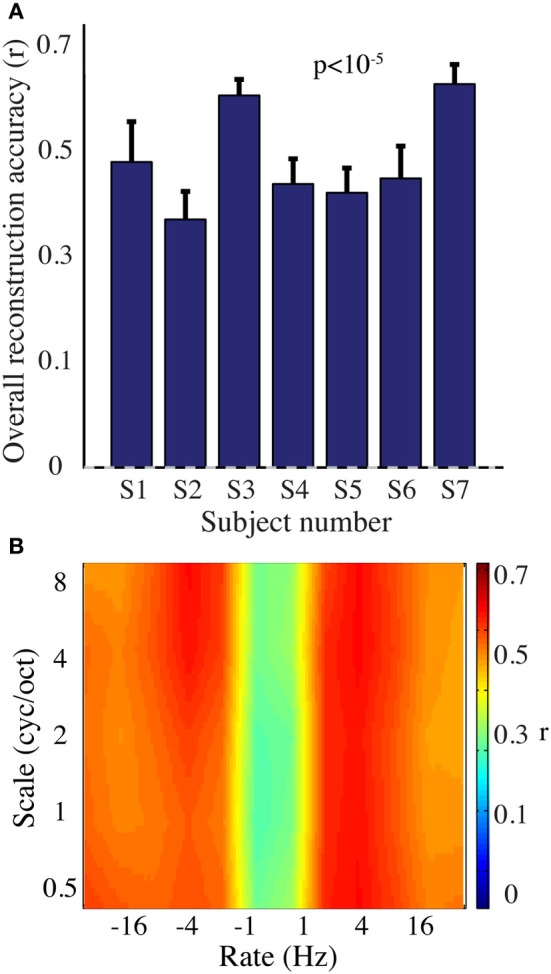
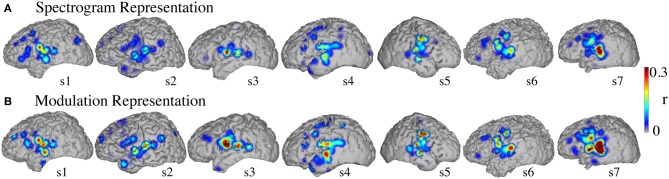
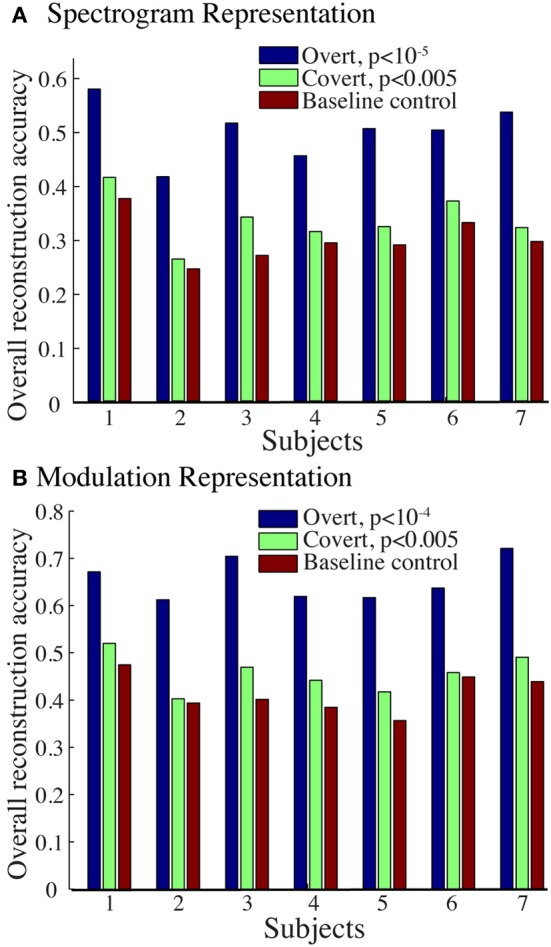
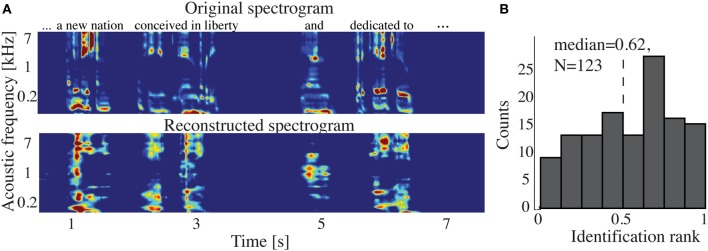
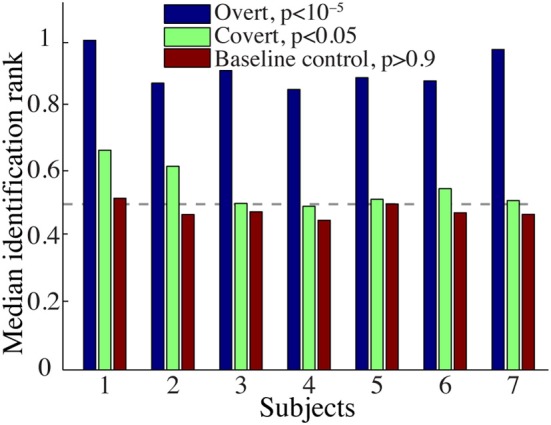
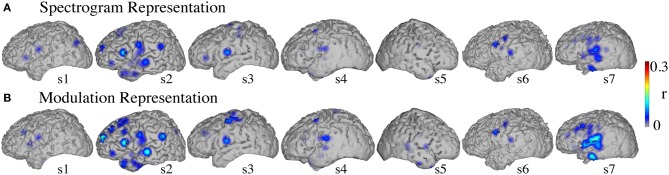
Auditory perception and auditory imagery have been shown to activate overlapping brain regions. We hypothesized that these phenomena also share a common underlying neural representation. To assess this, we used electrocorticography intracranial recordings from epileptic patients performing an out loud or a silent reading task. In these tasks, short stories scrolled across a video screen in two conditions: subjects read the same stories both aloud (overt) and silently (covert). In a control condition the subject remained in a resting state. We first built a high gamma (70-150 Hz) neural decoding model to reconstruct spectrotemporal auditory features of self-generated overt speech. We then evaluated whether this same model could reconstruct auditory speech features in the covert speech condition. Two speech models were tested: a spectrogram and a modulation-based feature space. For the overt condition, reconstruction accuracy was evaluated as the correlation between original and predicted speech features, and was significant in each subject (p < 10(-5); paired two-sample t-test). For the covert speech condition, dynamic time warping was first used to realign the covert speech reconstruction with the corresponding original speech from the overt condition. Reconstruction accuracy was then evaluated as the correlation between original and reconstructed speech features. Covert reconstruction accuracy was compared to the accuracy obtained from reconstructions in the baseline control condition. Reconstruction accuracy for the covert condition was significantly better than for the control condition (p < 0.005; paired two-sample t-test). The superior temporal gyrus, pre- and post-central gyrus provided the highest reconstruction information. The relationship between overt and covert speech reconstruction depended on anatomy. These results provide evidence that auditory representations of covert speech can be reconstructed from models that are built from an overt speech data set, supporting a partially shared neural substrate.
听觉感知和听觉意象已被证明会激活重叠的脑区。我们假设这些现象也共享一个共同的潜在神经表征。为了评估这一点,我们使用了癫痫患者的皮层脑电图颅内记录,这些患者执行大声或默读任务。在这些任务中,短篇故事在两种情况下在视频屏幕上滚动:受试者大声(公开)和默读(隐蔽)阅读相同的故事。在对照条件下,受试者保持静息状态。我们首先构建了一个高伽马(70 - 150赫兹)神经解码模型,以重建自我产生的公开言语的频谱时间听觉特征。然后我们评估这个相同的模型是否能在隐蔽言语条件下重建听觉言语特征。测试了两种言语模型:频谱图和基于调制的特征空间。对于公开条件,重建准确性通过原始言语特征与预测言语特征之间的相关性来评估,并且在每个受试者中都具有显著性(p < 10^(-5);配对双样本t检验)。对于隐蔽言语条件,首先使用动态时间规整将隐蔽言语重建与公开条件下相应的原始言语进行对齐。然后重建准确性通过原始言语特征与重建言语特征之间的相关性来评估。将隐蔽重建准确性与在基线对照条件下重建获得的准确性进行比较。隐蔽条件下的重建准确性显著优于对照条件(p < 0.005;配对双样本t检验)。颞上回、中央前回和中央后回提供了最高的重建信息。公开和隐蔽言语重建之间的关系取决于解剖结构。这些结果提供了证据,表明隐蔽言语的听觉表征可以从基于公开言语数据集构建的模型中重建,支持了部分共享的神经基质。