Döring Kersten, Grüning Björn A, Telukunta Kiran K, Thomas Philippe, Günther Stefan
Pharmaceutical Bioinformatics, Institute of Pharmaceutical Sciences, Albert-Ludwigs University, 79104 Freiburg, Germany.
Bioinformatics, Institute of Computer Science, Albert-Ludwigs University, 79110 Freiburg, Germany.
PLoS One. 2016 Oct 5;11(10):e0163794. doi: 10.1371/journal.pone.0163794. eCollection 2016.
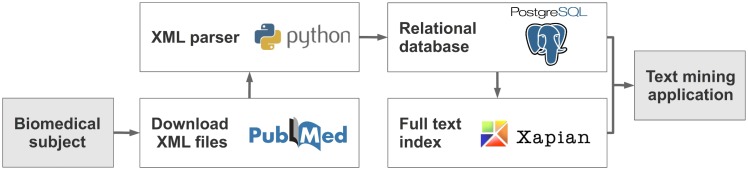
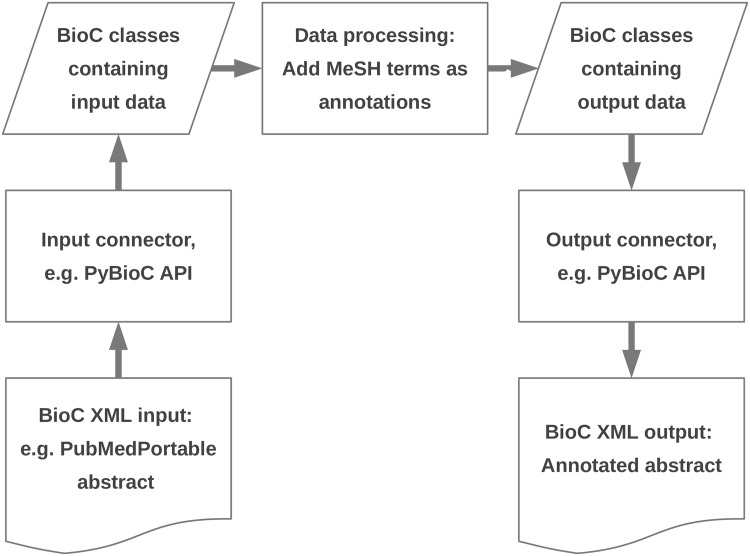
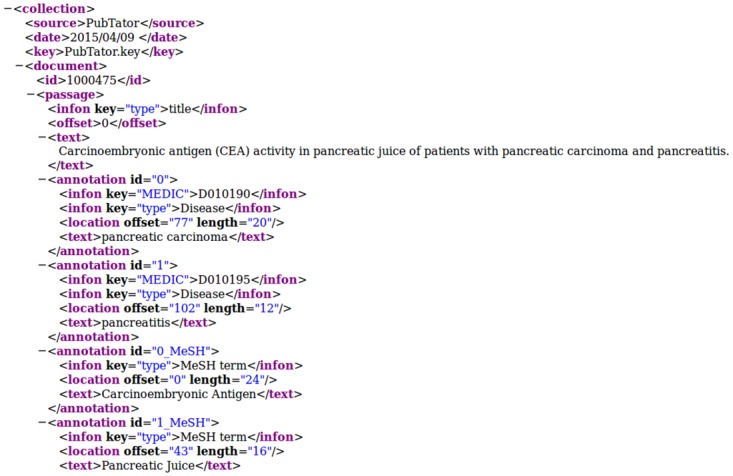
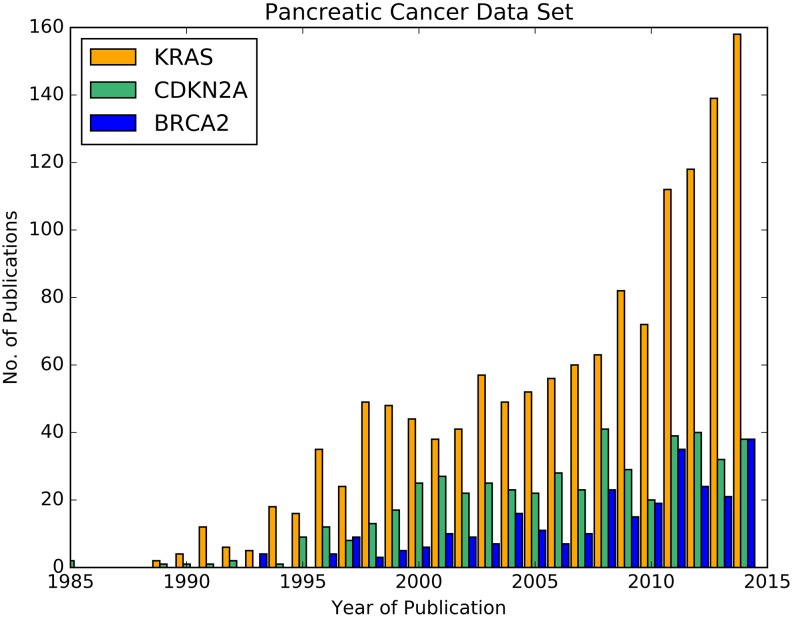
Information extraction from biomedical literature is continuously growing in scope and importance. Many tools exist that perform named entity recognition, e.g. of proteins, chemical compounds, and diseases. Furthermore, several approaches deal with the extraction of relations between identified entities. The BioCreative community supports these developments with yearly open challenges, which led to a standardised XML text annotation format called BioC. PubMed provides access to the largest open biomedical literature repository, but there is no unified way of connecting its data to natural language processing tools. Therefore, an appropriate data environment is needed as a basis to combine different software solutions and to develop customised text mining applications. PubMedPortable builds a relational database and a full text index on PubMed citations. It can be applied either to the complete PubMed data set or an arbitrary subset of downloaded PubMed XML files. The software provides the infrastructure to combine stand-alone applications by exporting different data formats, e.g. BioC. The presented workflows show how to use PubMedPortable to retrieve, store, and analyse a disease-specific data set. The provided use cases are well documented in the PubMedPortable wiki. The open-source software library is small, easy to use, and scalable to the user's system requirements. It is freely available for Linux on the web at https://github.com/KerstenDoering/PubMedPortable and for other operating systems as a virtual container. The approach was tested extensively and applied successfully in several projects.
从生物医学文献中提取信息的范围和重要性正在不断扩大。有许多工具可用于执行命名实体识别,例如蛋白质、化合物和疾病的识别。此外,还有几种方法可用于提取已识别实体之间的关系。生物创意社区通过每年举办的公开挑战赛来支持这些发展,这催生了一种名为BioC的标准化XML文本注释格式。PubMed提供了对最大的开放生物医学文献库的访问,但没有将其数据与自然语言处理工具相连接的统一方法。因此,需要一个合适的数据环境作为基础,以结合不同的软件解决方案并开发定制的文本挖掘应用程序。PubMedPortable在PubMed引文上构建了一个关系数据库和一个全文索引。它既可以应用于完整的PubMed数据集,也可以应用于下载的PubMed XML文件的任意子集。该软件通过导出不同的数据格式(例如BioC)提供了组合独立应用程序的基础设施。所展示的工作流程说明了如何使用PubMedPortable来检索、存储和分析特定疾病的数据集。提供的用例在PubMedPortable维基中有详细记录。这个开源软件库体积小、易于使用,并且可以根据用户的系统要求进行扩展。它可以在https://github.com/KerstenDoering/PubMedPortable网站上免费获取适用于Linux的版本,也可以作为虚拟容器获取适用于其他操作系统的版本。该方法经过了广泛测试,并在多个项目中成功应用。