Database Center for Life Science (DBCLS), Research Organization of Information and Systems, Kashiwa, Chiba, Japan.
PLoS One. 2019 Jun 4;14(6):e0217852. doi: 10.1371/journal.pone.0217852. eCollection 2019.
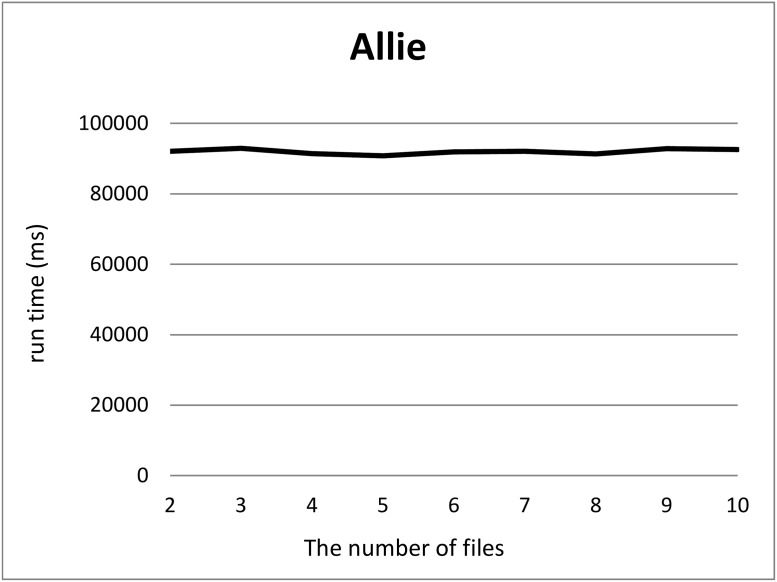
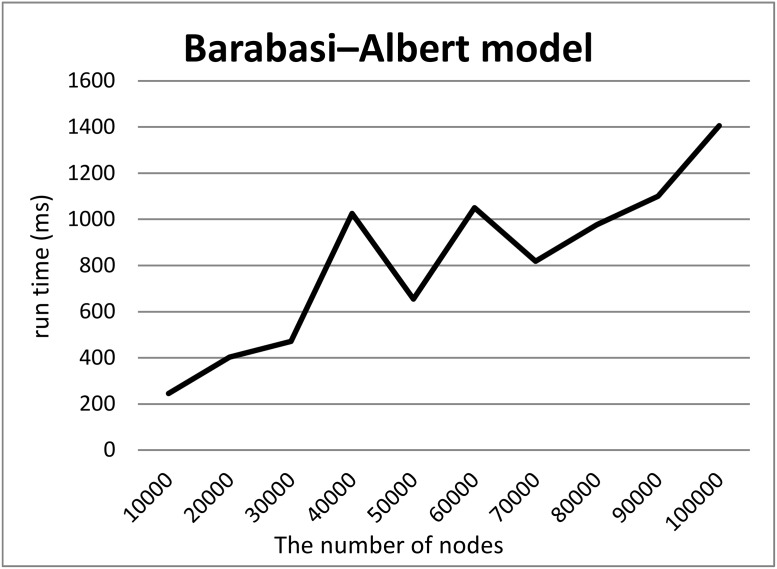
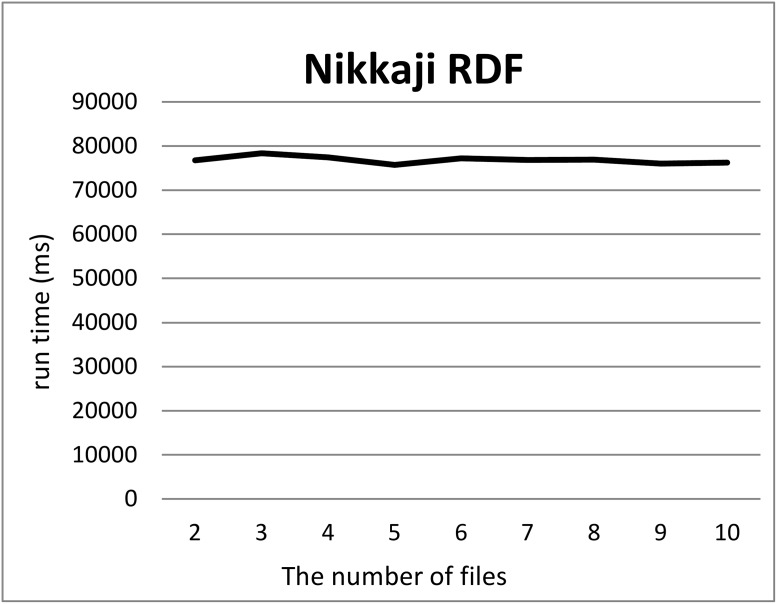
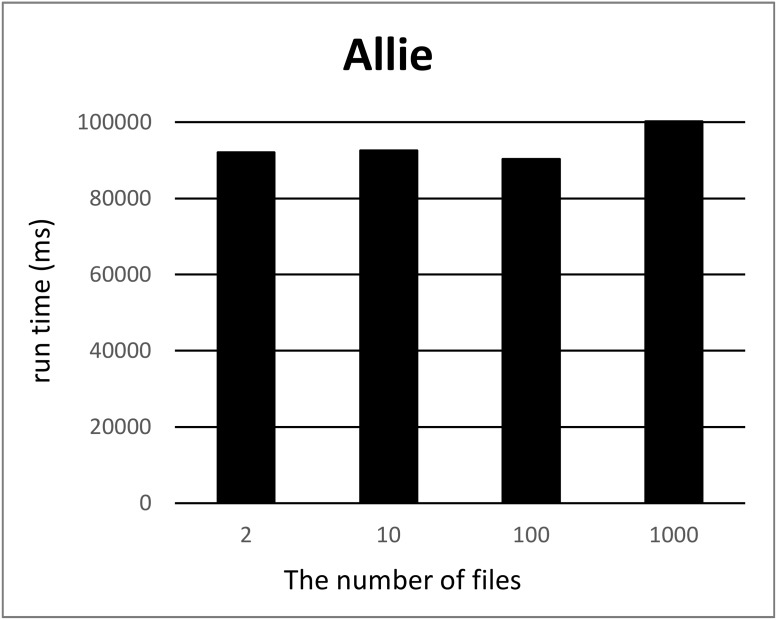
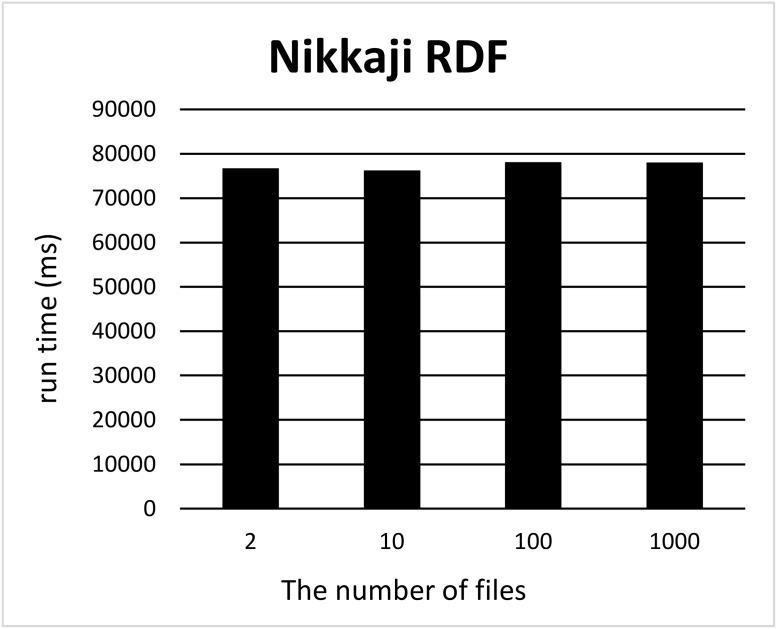
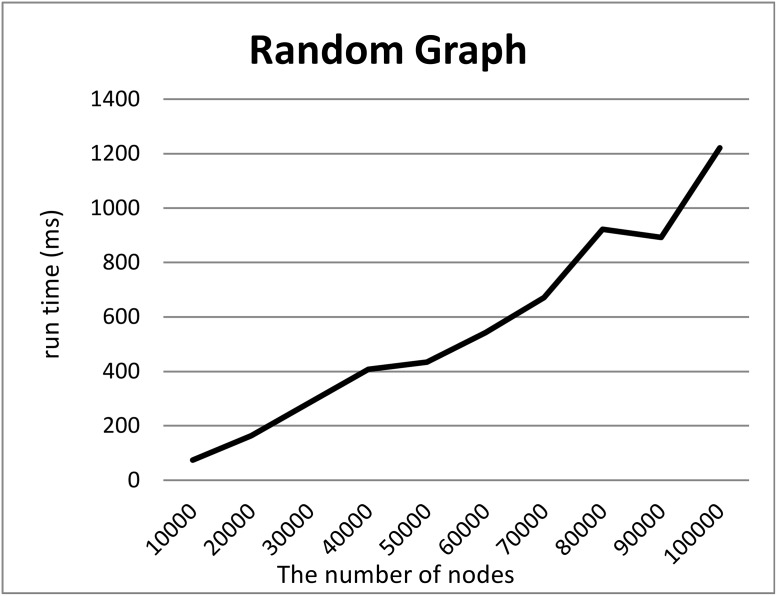
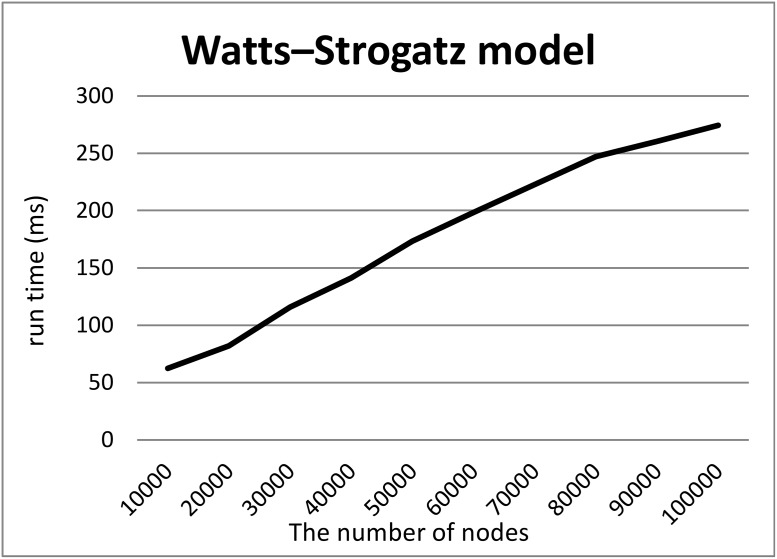
In life sciences, accompanied by the rapid growth of sequencing technology and the advancement of research, vast amounts of data are being generated. It is known that as the size of Resource Description Framework (RDF) datasets increases, the more efficient loading to triple stores is crucial. For example, UniProt's RDF version contains 44 billion triples as of December 2018. PubChem also has an RDF dataset with 137 billion triples. As data sizes become extremely large, loading them to a triple store consumes time. To improve the efficiency of this task, parallel loading has been recommended for several stores. However, with parallel loading, dataset consistency must be considered if the dataset contains blank nodes. By definition, blank nodes do not have global identifiers; thus, pairs of identical blank nodes in the original dataset are recognized as different if they reside in separate files after the dataset is split for parallel loading. To address this issue, we propose the Split4Blank tool, which splits a dataset into multiple files under the condition that identical blank nodes are not separated. The proposed tool uses connected component and multiprocessor scheduling algorithms and satisfies the above condition. Furthermore, to confirm the effectiveness of the proposed approach, we applied Split4Blank to two life sciences RDF datasets. In addition, we generated synthetic RDF datasets to evaluate scalability based on the properties of various graphs, such as a scale-free and random graph.
在生命科学领域,随着测序技术的飞速发展和研究的不断推进,产生了大量的数据。众所周知,随着 RDF 数据集规模的增长,将其高效地加载到三元存储库中变得至关重要。例如,截至 2018 年 12 月,UniProt 的 RDF 版本包含 440 亿个三元组。PubChem 也有一个包含 1370 亿个三元组的 RDF 数据集。随着数据规模变得非常庞大,将它们加载到三元存储库中需要花费时间。为了提高这项任务的效率,已经推荐了几种存储库的并行加载。然而,在使用并行加载时,如果数据集包含空白节点,则必须考虑数据集的一致性。根据定义,空白节点没有全局标识符;因此,如果在将数据集分割为并行加载的多个文件后,原始数据集中相同的空白节点位于不同的文件中,那么它们将被视为不同的节点。为了解决这个问题,我们提出了 Split4Blank 工具,该工具可以在不分离相同空白节点的情况下将数据集分割成多个文件。所提出的工具使用连通分量和多处理器调度算法,并满足上述条件。此外,为了确认所提出方法的有效性,我们将 Split4Blank 应用于两个生命科学 RDF 数据集。此外,我们还生成了基于各种图的属性(例如无标度图和随机图)的合成 RDF 数据集,以评估可扩展性。