Sun Lin, Zhang Xiaoyu, Xu Jiucheng, Zhang Shiguang
College of Computer and Information Engineering, Henan Normal University, Xinxiang 453007, China.
Engineering Technology Research Center for Computing Intelligence and Data Mining, Henan 453007, China.
Entropy (Basel). 2019 Feb 7;21(2):155. doi: 10.3390/e21020155.
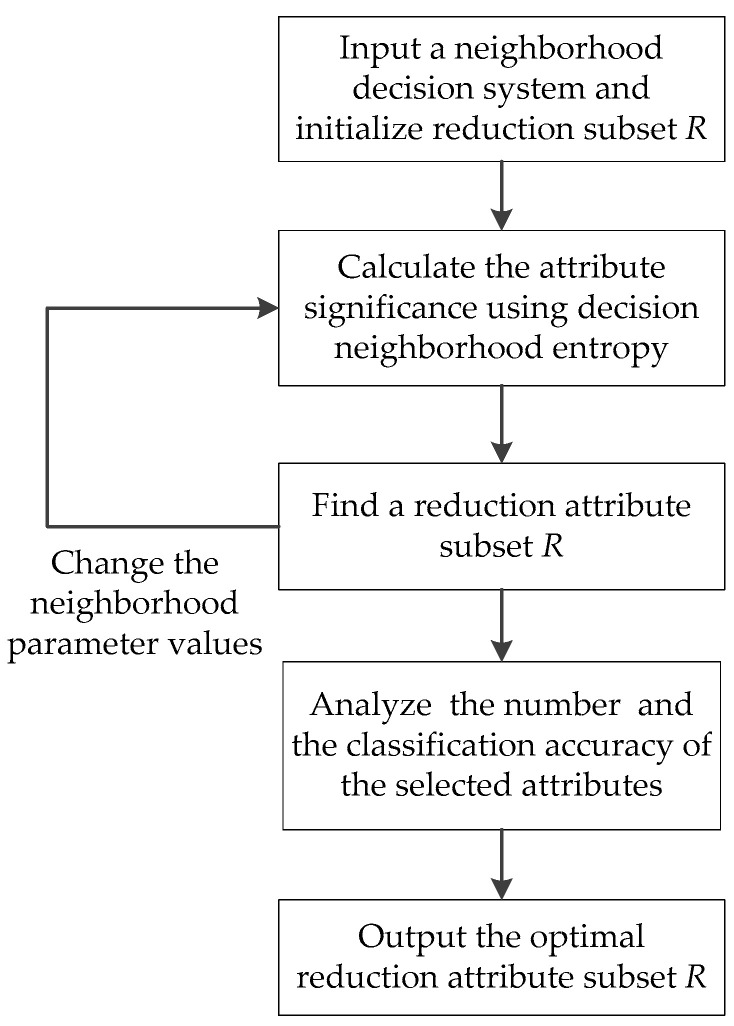
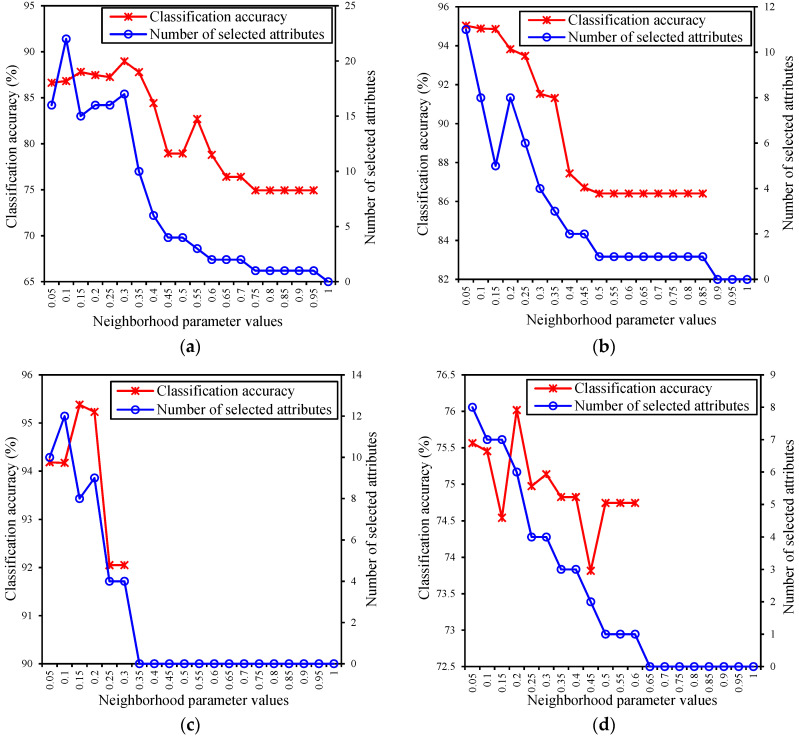
Attribute reduction as an important preprocessing step for data mining, and has become a hot research topic in rough set theory. Neighborhood rough set theory can overcome the shortcoming that classical rough set theory may lose some useful information in the process of discretization for continuous-valued data sets. In this paper, to improve the classification performance of complex data, a novel attribute reduction method using neighborhood entropy measures, combining algebra view with information view, in neighborhood rough sets is proposed, which has the ability of dealing with continuous data whilst maintaining the classification information of original attributes. First, to efficiently analyze the uncertainty of knowledge in neighborhood rough sets, by combining neighborhood approximate precision with neighborhood entropy, a new average neighborhood entropy, based on the strong complementarity between the algebra definition of attribute significance and the definition of information view, is presented. Then, a concept of decision neighborhood entropy is investigated for handling the uncertainty and noisiness of neighborhood decision systems, which integrates the credibility degree with the coverage degree of neighborhood decision systems to fully reflect the decision ability of attributes. Moreover, some of their properties are derived and the relationships among these measures are established, which helps to understand the essence of knowledge content and the uncertainty of neighborhood decision systems. Finally, a heuristic attribute reduction algorithm is proposed to improve the classification performance of complex data sets. The experimental results under an instance and several public data sets demonstrate that the proposed method is very effective for selecting the most relevant attributes with great classification performance.
属性约简作为数据挖掘的一个重要预处理步骤,已成为粗糙集理论中的一个热门研究课题。邻域粗糙集理论能够克服经典粗糙集理论在对连续值数据集进行离散化过程中可能丢失一些有用信息的缺点。本文针对邻域粗糙集,为提高复杂数据的分类性能,提出一种结合代数观点与信息观点的基于邻域熵测度的新型属性约简方法,该方法能够处理连续数据,同时保持原始属性的分类信息。首先,为有效分析邻域粗糙集中知识的不确定性,通过将邻域近似精度与邻域熵相结合,基于属性重要性的代数定义与信息观点定义之间的强互补性,提出一种新的平均邻域熵。然后,研究了决策邻域熵的概念以处理邻域决策系统的不确定性和噪声,它将邻域决策系统的可信度与覆盖度相结合,以充分反映属性的决策能力。此外,推导了它们的一些性质并建立了这些测度之间的关系,这有助于理解邻域决策系统知识内容的本质和不确定性。最后,提出一种启发式属性约简算法以提高复杂数据集的分类性能。在一个实例和几个公共数据集上的实验结果表明,所提方法在选择具有良好分类性能的最相关属性方面非常有效。