Tegmark Max, Wu Tailin
Department of Physics, MIT Kavli Institute & Center for Brains, Minds & Machines, Massachusetts Institute of Technology, Cambridge, MA 02139, USA.
Entropy (Basel). 2019 Dec 19;22(1):7. doi: 10.3390/e22010007.
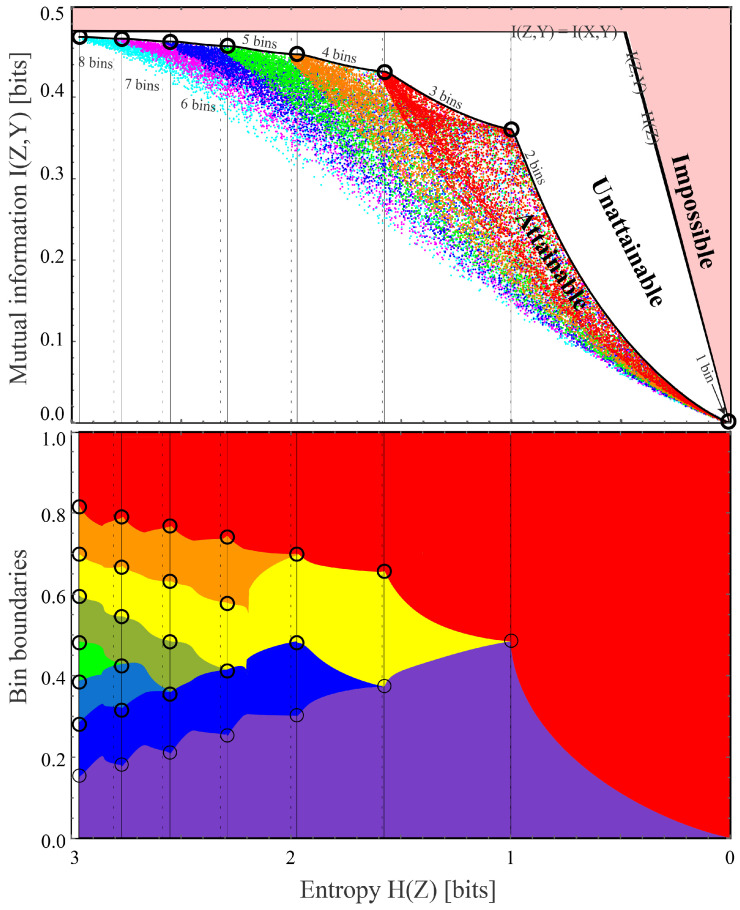
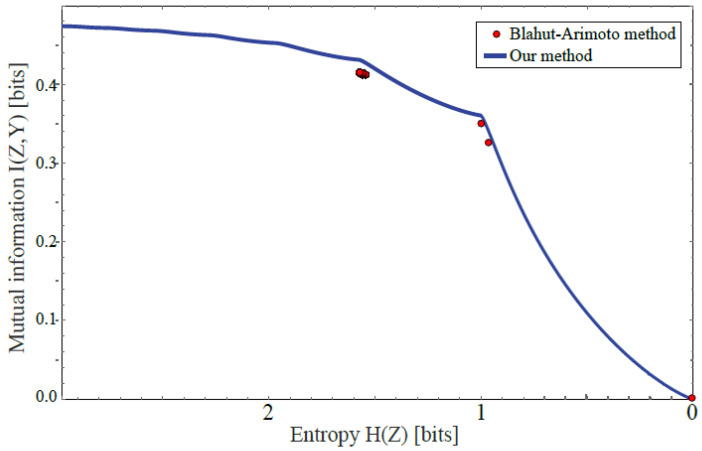
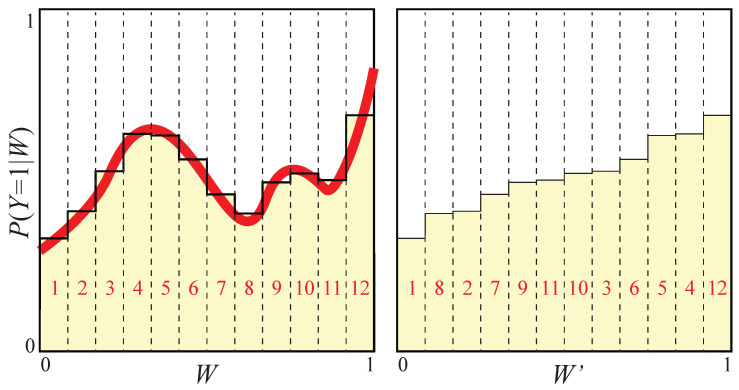
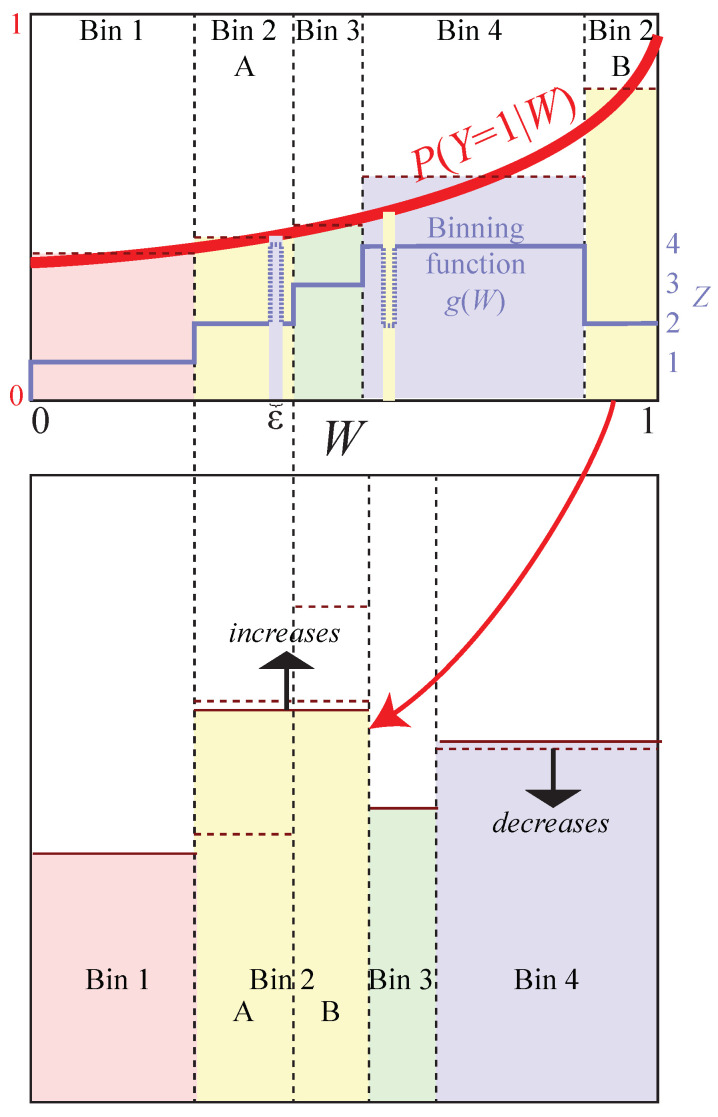
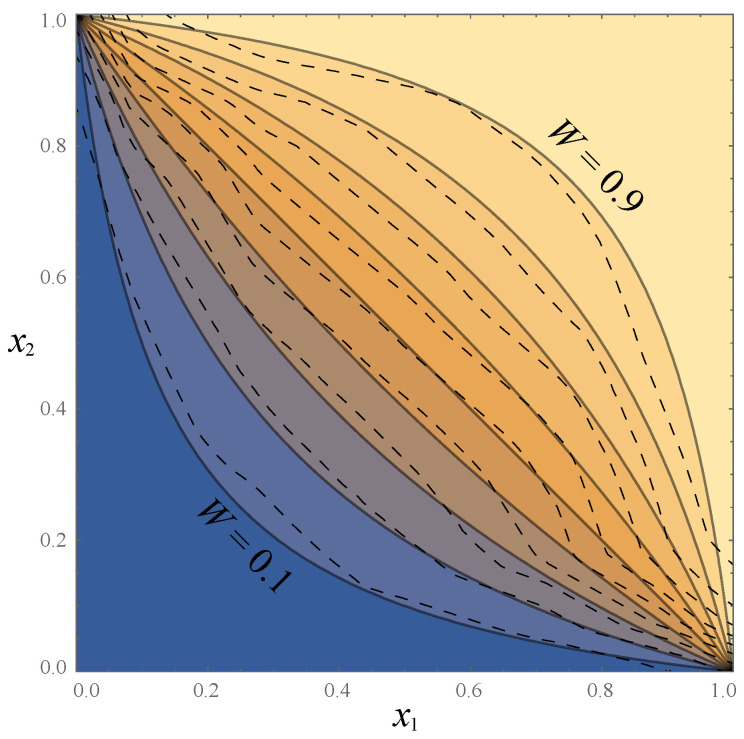
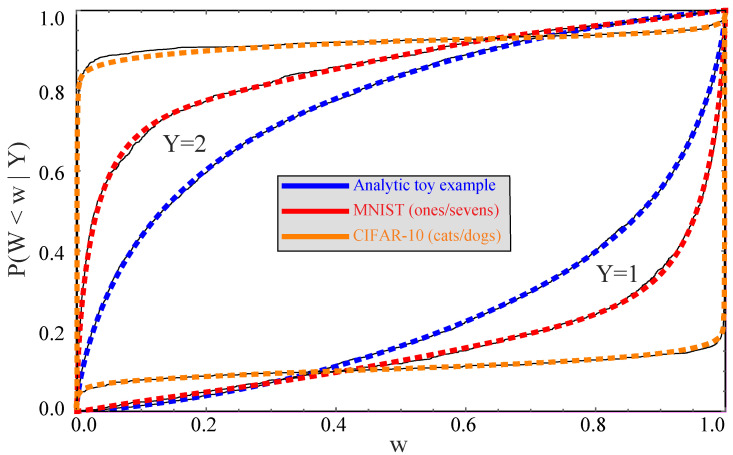
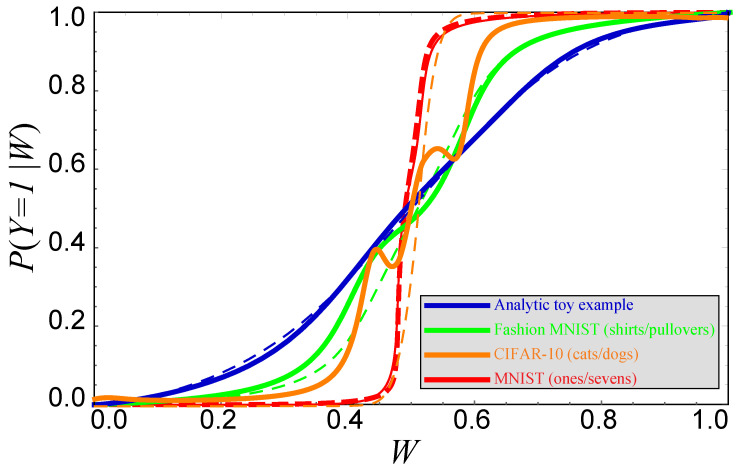
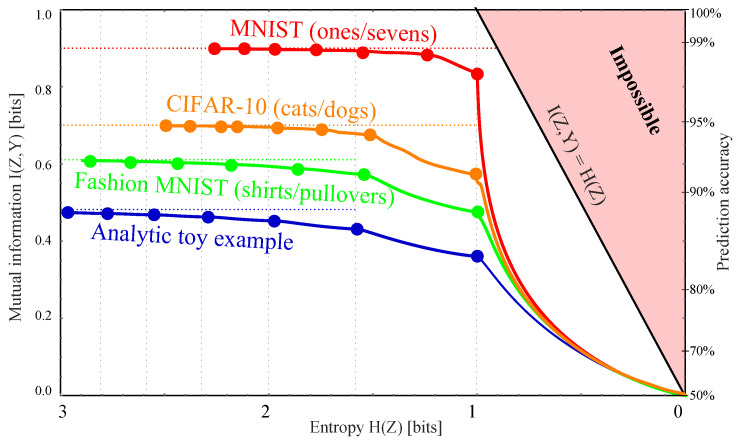
The goal of lossy data compression is to reduce the storage cost of a data set while retaining as much information as possible about something () that you care about. For example, what aspects of an image contain the most information about whether it depicts a cat? Mathematically, this corresponds to finding a mapping X → Z ≡ f ( X ) that maximizes the mutual information I ( Z , Y ) while the entropy H ( Z ) is kept below some fixed threshold. We present a new method for mapping out the Pareto frontier for classification tasks, reflecting the tradeoff between retained entropy and class information. We first show how a random variable (an image, say) drawn from a class Y ∈ { 1 , … , n } can be distilled into a vector W = f ( X ) ∈ R n - 1 losslessly, so that I ( W , Y ) = I ( X , Y ) ; for example, for a binary classification task of cats and dogs, each image is mapped into a single real number retaining all information that helps distinguish cats from dogs. For the n = 2 case of binary classification, we then show how can be further compressed into a discrete variable Z = g β ( W ) ∈ { 1 , … , m β } by binning into m β bins, in such a way that varying the parameter β sweeps out the full Pareto frontier, solving a generalization of the discrete information bottleneck (DIB) problem. We argue that the most interesting points on this frontier are "corners" maximizing I ( Z , Y ) for a fixed number of bins m = 2 , 3 , … which can conveniently be found without multiobjective optimization. We apply this method to the CIFAR-10, MNIST and Fashion-MNIST datasets, illustrating how it can be interpreted as an information-theoretically optimal image clustering algorithm. We find that these Pareto frontiers are not concave, and that recently reported DIB phase transitions correspond to transitions between these corners, changing the number of clusters.
有损数据压缩的目标是降低数据集的存储成本,同时尽可能多地保留与你所关心的事物()相关的信息。例如,图像的哪些方面包含了关于它是否描绘了一只猫的最多信息?从数学上讲,这相当于找到一个映射X → Z ≡ f (X),在熵H (Z)保持在某个固定阈值以下的同时,最大化互信息I (Z, Y)。我们提出了一种新方法来描绘分类任务的帕累托前沿,反映保留的熵和类别信息之间的权衡。我们首先展示了从类别Y ∈ {1, …, n}中抽取的随机变量(比如一幅图像)如何能够无损地提炼为向量W = f (X) ∈ Rⁿ⁻¹,使得I (W, Y) = I (X, Y);例如,对于猫和狗的二分类任务,每幅图像都被映射为一个单一实数,保留所有有助于区分猫和狗的信息。对于二分类的n = 2情况,我们接着展示了如何通过将W划分为m_β个箱,进一步将其压缩为离散变量Z = g_β (W) ∈ {1, …, m_β},这样通过改变参数β可以扫出整个帕累托前沿,解决离散信息瓶颈(DIB)问题的一个推广。我们认为这个前沿上最有趣的点是在固定箱数m = 2, 3, …时最大化I (Z, Y)的“角点”,无需多目标优化就能方便地找到这些点。我们将此方法应用于CIFAR-10、MNIST和Fashion-MNIST数据集,说明它如何可以被解释为一种信息理论上最优的图像聚类算法。我们发现这些帕累托前沿不是凹的,并且最近报道的DIB相变对应于这些角点之间的转变,改变了聚类的数量。