Kameshima Haruka, Uejima Tokuhisa, Fraser Alan G, Takahashi Lisa, Cho Junyi, Suzuki Shinya, Kato Yuko, Yajima Junji, Yamashita Takeshi
The Cardiovascular Institute Hospital, Tokyo, Japan.
School of Medicine, Cardiff University, Cardiff, United Kingdom.
Front Cardiovasc Med. 2021 Dec 23;8:755109. doi: 10.3389/fcvm.2021.755109. eCollection 2021.
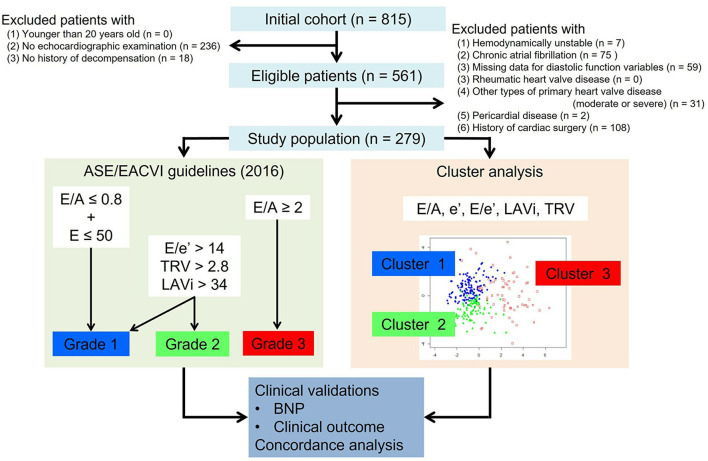
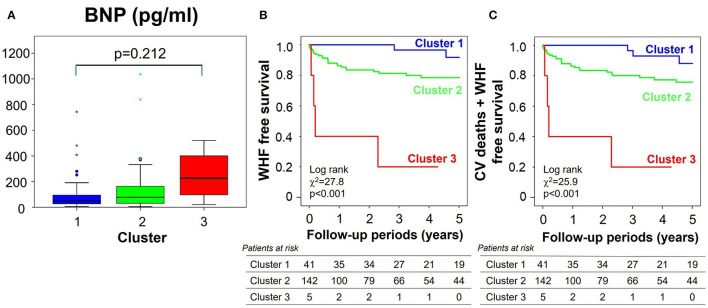
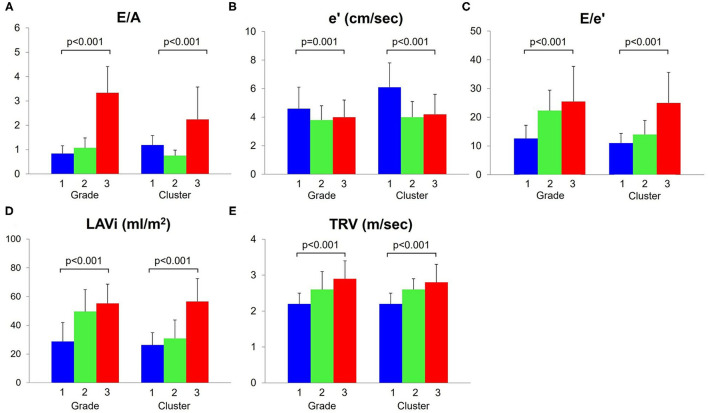
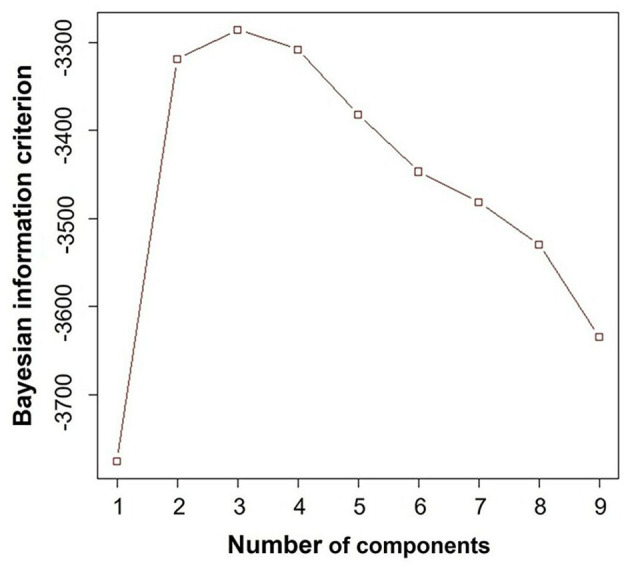
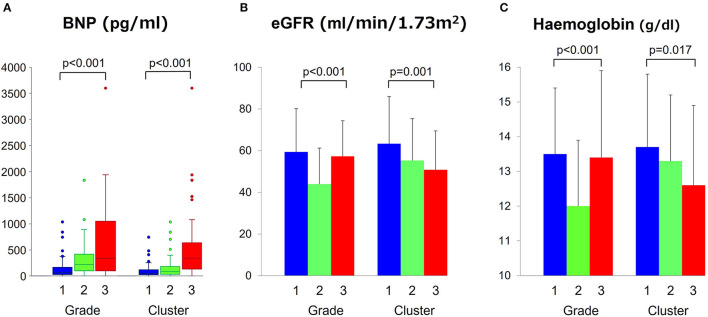
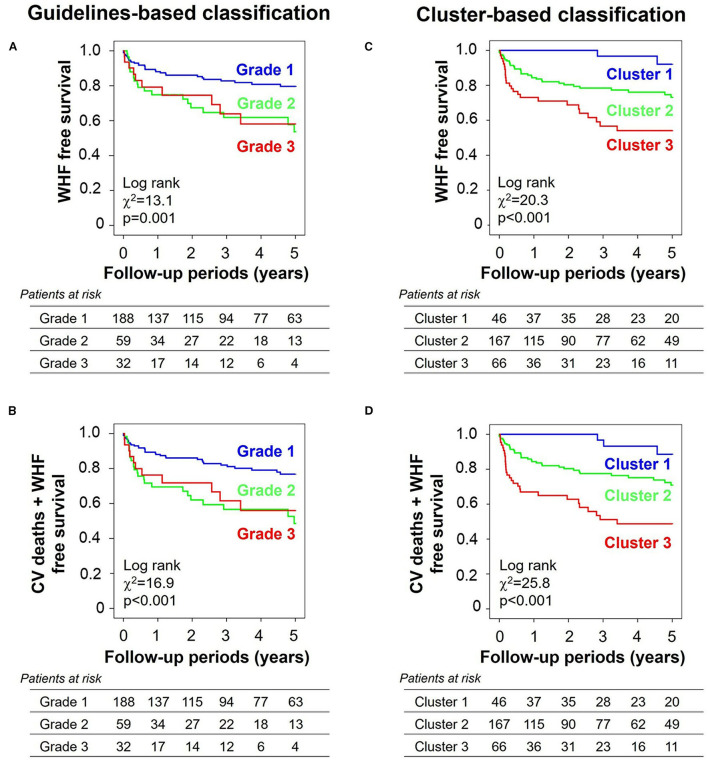
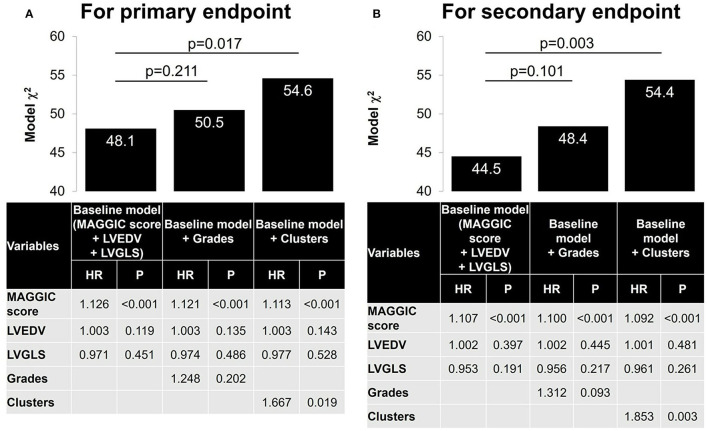
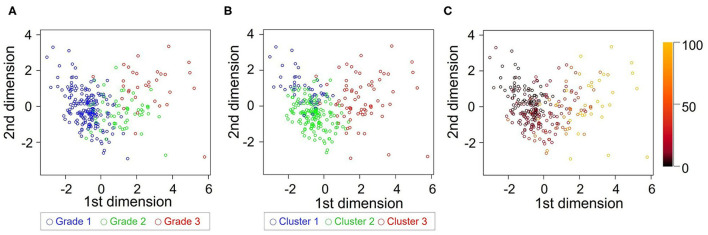
Discriminating between different patterns of diastolic dysfunction in heart failure (HF) is still challenging. We tested the hypothesis that an unsupervised machine learning algorithm would detect heterogeneity in diastolic function and improve risk stratification compared with recommended consensus criteria. This study included 279 consecutive patients aged 24-97 years old with clinically stable HF referred for echocardiographic assessment, in whom diastolic variables were measured according to the current guidelines. Cluster analysis was undertaken to identify homogeneous groups of patients with similar profiles of the variables. Sequential Cox models were used to compare cluster-based classification with guidelines-based classification for predicting clinical outcomes. The primary endpoint was hospitalization for worsening HF. The analysis identified three clusters with distinct properties of diastolic function that shared similarities with guidelines-based classification. The clusters were associated with brain natriuretic peptide level ( < 0.001), hemoglobin concentration ( = 0.017) and estimated glomerular filtration rate ( = 0.001). During a mean follow-up period of 2.6 ± 2.0 years, 62 patients (22%) experienced the primary endpoint. Cluster-based classification predicted events with a hazard ratio 1.68 ( = 0.019) that was independent from and incremental to the Meta-analysis Global Group in Chronic Heart Failure (MAGGIC) risk score for HF, and from left ventricular end-diastolic volume and global longitudinal strain, whereas guidelines-based classification did not retain its independent prognostic value (hazard ratio = 1.25, = 0.202). Machine learning can identify patterns of diastolic function that better stratify the risk for decompensation than the current consensus recommendations in HF. Integrating this data-driven phenotyping may help in refining prognostication and optimizing treatment.
区分心力衰竭(HF)中不同类型的舒张功能障碍仍然具有挑战性。我们检验了这样一个假设:与推荐的共识标准相比,无监督机器学习算法能够检测舒张功能的异质性并改善风险分层。本研究纳入了279例年龄在24 - 97岁、临床稳定的HF患者,这些患者因超声心动图评估前来就诊,根据当前指南测量了他们的舒张变量。进行聚类分析以识别具有相似变量特征的同质患者组。使用序贯Cox模型比较基于聚类的分类和基于指南的分类对临床结局的预测情况。主要终点是因HF恶化而住院。分析确定了三个具有不同舒张功能特性的聚类,它们与基于指南的分类有相似之处。这些聚类与脑钠肽水平(<0.001)、血红蛋白浓度(=0.017)和估算肾小球滤过率(=0.001)相关。在平均2.6±2.0年的随访期内,62例患者(22%)经历了主要终点。基于聚类的分类预测事件的风险比为1.68(=0.019),该风险比独立于慢性心力衰竭荟萃分析全球组(MAGGIC)的HF风险评分,并且在该评分基础上有增量作用,同时也独立于左心室舒张末期容积和整体纵向应变,而基于指南的分类并未保留其独立的预后价值(风险比 = 1.25,=0.202)。机器学习能够识别舒张功能模式,与HF当前的共识推荐相比,该模式能更好地对失代偿风险进行分层。整合这种数据驱动的表型分析可能有助于优化预后和治疗。