Human Language and Accesibility Technologies, Computer Science Department, Universidad Carlos III de Madrid, Avenidad de la Universidad, 30, Leganés, 28911, Madrid, Spain.
Tissue Engineering and Regenerative Medicine group, Department of Bioengineering, Universidad Carlos III de Madrid, Avenidad de la Universidad, 30, Leganés, 28911, Madrid, Spain.
BMC Bioinformatics. 2022 Jul 6;23(1):263. doi: 10.1186/s12859-022-04810-y.
Although rare diseases are characterized by low prevalence, approximately 400 million people are affected by a rare disease. The early and accurate diagnosis of these conditions is a major challenge for general practitioners, who do not have enough knowledge to identify them. In addition to this, rare diseases usually show a wide variety of manifestations, which might make the diagnosis even more difficult. A delayed diagnosis can negatively affect the patient's life. Therefore, there is an urgent need to increase the scientific and medical knowledge about rare diseases. Natural Language Processing (NLP) and Deep Learning can help to extract relevant information about rare diseases to facilitate their diagnosis and treatments.
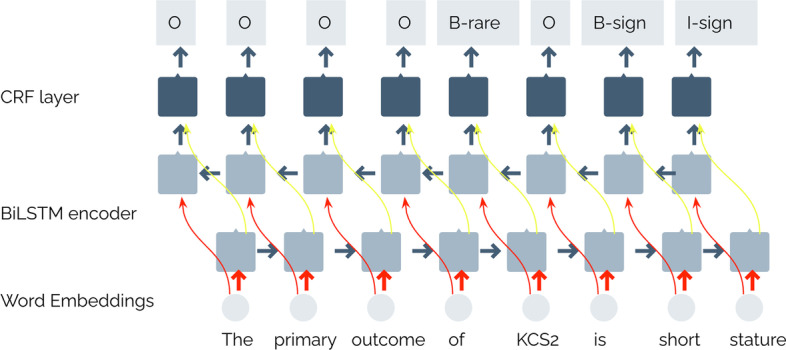
The paper explores several deep learning techniques such as Bidirectional Long Short Term Memory (BiLSTM) networks or deep contextualized word representations based on Bidirectional Encoder Representations from Transformers (BERT) to recognize rare diseases and their clinical manifestations (signs and symptoms).
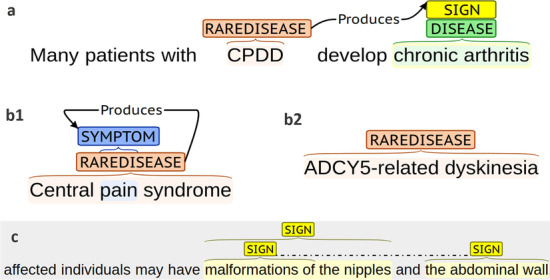
BioBERT, a domain-specific language representation based on BERT and trained on biomedical corpora, obtains the best results with an F1 of 85.2% for rare diseases. Since many signs are usually described by complex noun phrases that involve the use of use of overlapped, nested and discontinuous entities, the model provides lower results with an F1 of 57.2%.
While our results are promising, there is still much room for improvement, especially with respect to the identification of clinical manifestations (signs and symptoms).
尽管罕见病的患病率较低,但全球约有 4 亿人受到罕见病的影响。这些疾病的早期和准确诊断对全科医生来说是一个重大挑战,他们缺乏足够的知识来识别这些疾病。此外,罕见病通常表现出多种不同的症状,这可能使诊断更加困难。诊断延迟可能会对患者的生活产生负面影响。因此,迫切需要增加对罕见病的科学和医学知识。自然语言处理 (NLP) 和深度学习可以帮助提取有关罕见病的相关信息,以促进其诊断和治疗。
本文探讨了几种深度学习技术,如双向长短期记忆 (BiLSTM) 网络或基于转换器的双向编码器表示 (BERT) 的深度上下文词表示,以识别罕见病及其临床表现 (体征和症状)。
基于 BERT 的生物特定领域语言表示 BioBERT 在生物医学语料库上进行训练,在罕见病识别方面取得了最佳效果,F1 值为 85.2%。由于许多体征通常由涉及重叠、嵌套和不连续实体的复杂名词短语描述,因此该模型的 F1 值为 57.2%,识别效果较差。
虽然我们的结果很有希望,但仍有很大的改进空间,特别是在识别临床表现 (体征和症状) 方面。