Lazovich Tomo, Belli Luca, Gonzales Aaron, Bower Amanda, Tantipongpipat Uthaipon, Lum Kristian, Huszár Ferenc, Chowdhury Rumman
Twitter, Inc., San Francisco, CA 94103, USA.
University of Cambridge, Cambridge, UK.
Patterns (N Y). 2022 Aug 12;3(8):100568. doi: 10.1016/j.patter.2022.100568.
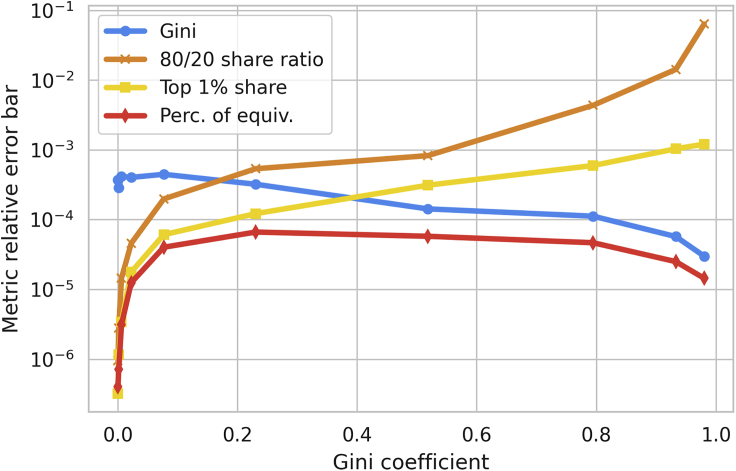
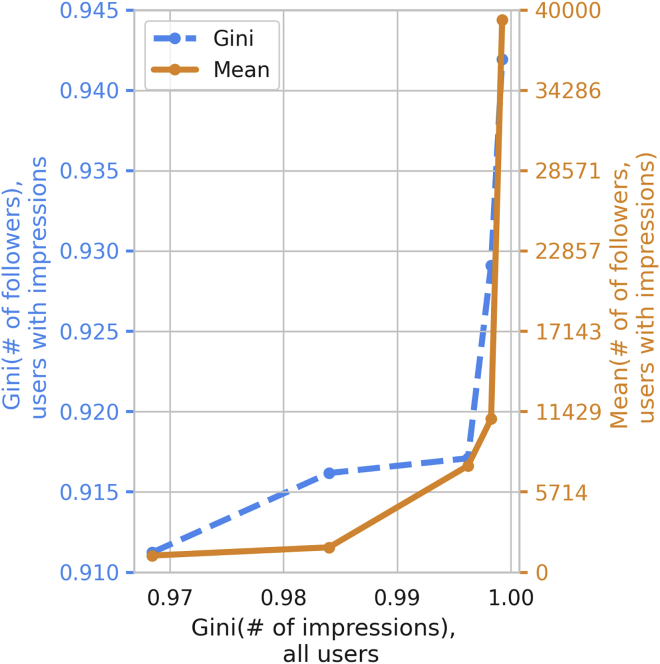
The harmful impacts of algorithmic decision systems have recently come into focus, with many examples of machine learning (ML) models amplifying societal biases. In this paper, we propose adapting income inequality metrics from economics to complement existing model-level fairness metrics, which focus on intergroup differences of model performance. In particular, we evaluate their ability to measure disparities between exposures that individuals receive in a production recommendation system, the Twitter algorithmic timeline. We define desirable criteria for metrics to be used in an operational setting by ML practitioners. We characterize engagements with content on Twitter using these metrics and use the results to evaluate the metrics with respect to our criteria. We also show that we can use these metrics to identify content suggestion algorithms that contribute more strongly to skewed outcomes between users. Overall, we conclude that these metrics can be a useful tool for auditing algorithms in production settings.
算法决策系统的有害影响最近受到关注,有许多机器学习(ML)模型加剧社会偏见的例子。在本文中,我们提议采用经济学中的收入不平等指标来补充现有的模型层面公平性指标,后者侧重于模型性能的群体间差异。具体而言,我们评估这些指标衡量个体在生产推荐系统(推特算法时间线)中所受曝光差异的能力。我们为ML从业者在实际操作环境中使用的指标定义了理想标准。我们使用这些指标来刻画推特上与内容互动情况,并根据我们的标准用结果评估这些指标。我们还表明,我们可以使用这些指标来识别那些对用户间结果偏差贡献更大的内容推荐算法。总体而言,我们得出结论,这些指标可以成为生产环境中算法审计的有用工具。