Department of Diagnostic and Generalist Medicine, Dokkyo Medical University, Tochigi 321-0293, Japan.
Int J Environ Res Public Health. 2023 Feb 15;20(4):3378. doi: 10.3390/ijerph20043378.
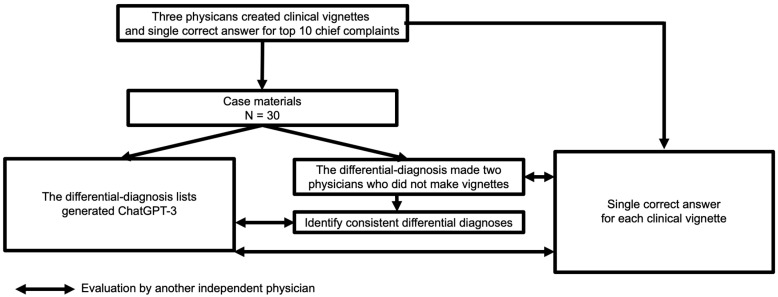
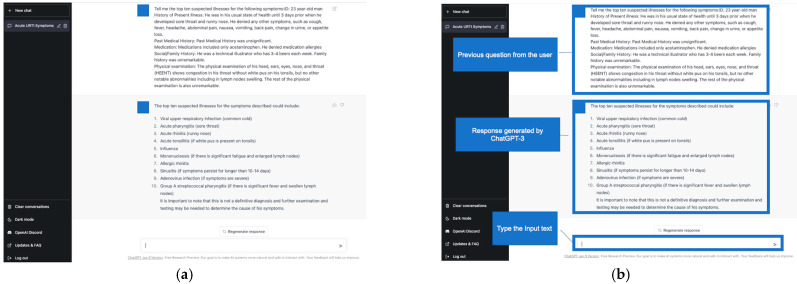
The diagnostic accuracy of differential diagnoses generated by artificial intelligence (AI) chatbots, including the generative pretrained transformer 3 (GPT-3) chatbot (ChatGPT-3) is unknown. This study evaluated the accuracy of differential-diagnosis lists generated by ChatGPT-3 for clinical vignettes with common chief complaints. General internal medicine physicians created clinical cases, correct diagnoses, and five differential diagnoses for ten common chief complaints. The rate of correct diagnosis by ChatGPT-3 within the ten differential-diagnosis lists was 28/30 (93.3%). The rate of correct diagnosis by physicians was still superior to that by ChatGPT-3 within the five differential-diagnosis lists (98.3% vs. 83.3%, = 0.03). The rate of correct diagnosis by physicians was also superior to that by ChatGPT-3 in the top diagnosis (53.3% vs. 93.3%, < 0.001). The rate of consistent differential diagnoses among physicians within the ten differential-diagnosis lists generated by ChatGPT-3 was 62/88 (70.5%). In summary, this study demonstrates the high diagnostic accuracy of differential-diagnosis lists generated by ChatGPT-3 for clinical cases with common chief complaints. This suggests that AI chatbots such as ChatGPT-3 can generate a well-differentiated diagnosis list for common chief complaints. However, the order of these lists can be improved in the future.
人工智能(AI)聊天机器人生成的鉴别诊断的准确性,包括生成式预训练转换器 3(GPT-3)聊天机器人(ChatGPT-3),目前尚不清楚。本研究评估了 ChatGPT-3 对常见主诉临床病例生成的鉴别诊断列表的准确性。内科医生创建了临床病例、正确诊断和十个常见主诉的五个鉴别诊断。ChatGPT-3 在十个鉴别诊断列表中的正确诊断率为 28/30(93.3%)。在五个鉴别诊断列表中,医生的正确诊断率仍高于 ChatGPT-3(98.3% vs. 83.3%, = 0.03)。医生在主要诊断中的正确诊断率也高于 ChatGPT-3(53.3% vs. 93.3%,<0.001)。ChatGPT-3 生成的十个鉴别诊断列表中,医生之间的鉴别诊断一致性率为 62/88(70.5%)。总之,本研究表明 ChatGPT-3 对常见主诉临床病例生成的鉴别诊断列表具有较高的诊断准确性。这表明,像 ChatGPT-3 这样的 AI 聊天机器人可以为常见主诉生成一个良好区分的诊断列表。然而,这些列表的顺序在未来可以得到改进。