Pachetti Eva, Colantonio Sara
"Alessandro Faedo" Institute of Information Science and Technologies (ISTI), National Research Council of Italy (CNR), 56127 Pisa, Italy.
Department of Information Engineering (DII), University of Pisa, 56122 Pisa, Italy.
Bioengineering (Basel). 2023 Aug 28;10(9):1015. doi: 10.3390/bioengineering10091015.
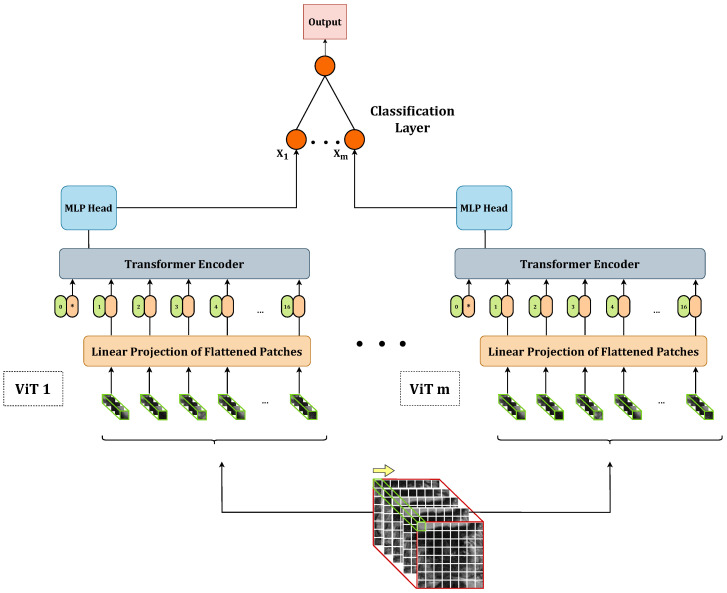
Vision transformers represent the cutting-edge topic in computer vision and are usually employed on two-dimensional data following a transfer learning approach. In this work, we propose a trained-from-scratch stacking ensemble of 3D-vision transformers to assess prostate cancer aggressiveness from T2-weighted images to help radiologists diagnose this disease without performing a biopsy. We trained 18 3D-vision transformers on T2-weighted axial acquisitions and combined them into two- and three-model stacking ensembles. We defined two metrics for measuring model prediction confidence, and we trained all the ensemble combinations according to a five-fold cross-validation, evaluating their accuracy, confidence in predictions, and calibration. In addition, we optimized the 18 base ViTs and compared the best-performing base and ensemble models by re-training them on a 100-sample bootstrapped training set and evaluating each model on the hold-out test set. We compared the two distributions by calculating the median and the 95% confidence interval and performing a Wilcoxon signed-rank test. The best-performing 3D-vision-transformer stacking ensemble provided state-of-the-art results in terms of area under the receiving operating curve (0.89 [0.61-1]) and exceeded the area under the precision-recall curve of the base model of 22% ( < 0.001). However, it resulted to be less confident in classifying the positive class.
视觉Transformer是计算机视觉领域的前沿课题,通常采用迁移学习方法应用于二维数据。在这项工作中,我们提出了一种从零开始训练的3D视觉Transformer堆叠集成模型,用于从T2加权图像评估前列腺癌的侵袭性,以帮助放射科医生在不进行活检的情况下诊断这种疾病。我们在T2加权轴向图像上训练了18个3D视觉Transformer,并将它们组合成双模型和三模型堆叠集成。我们定义了两个用于衡量模型预测置信度的指标,并根据五折交叉验证对所有集成组合进行训练,评估它们的准确性、预测置信度和校准情况。此外,我们对18个基础视觉Transformer进行了优化,并通过在100个样本的自助训练集上重新训练它们,并在留出测试集上评估每个模型,比较了性能最佳的基础模型和集成模型。我们通过计算中位数和95%置信区间并进行Wilcoxon符号秩检验来比较这两个分布。性能最佳的3D视觉Transformer堆叠集成在接受操作曲线下面积(0.89 [0.61 - 1])方面提供了领先的结果,并且比基础模型的精确召回曲线下面积高出22%(< 0.001)。然而,它在对阳性类别进行分类时的置信度较低。