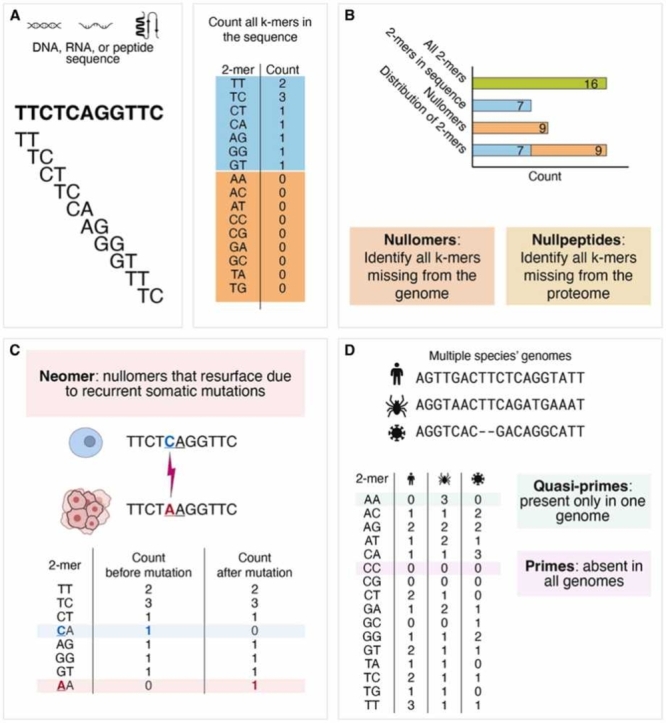
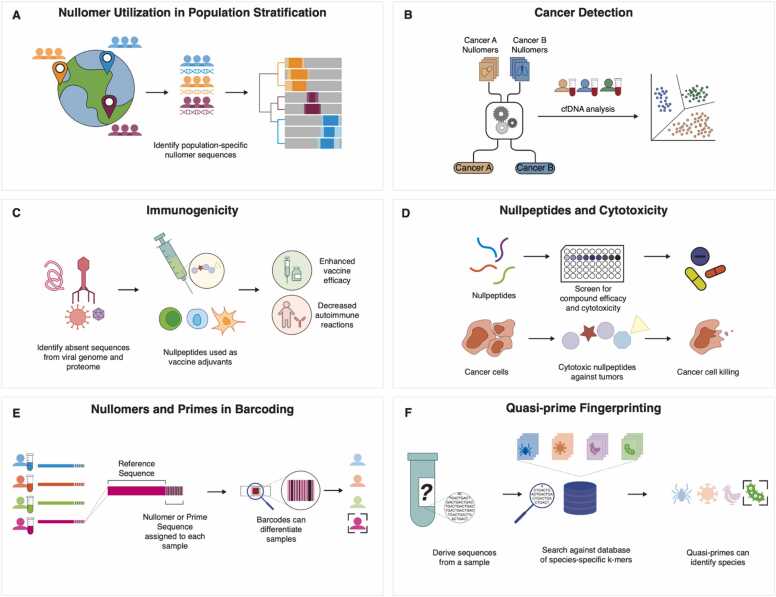
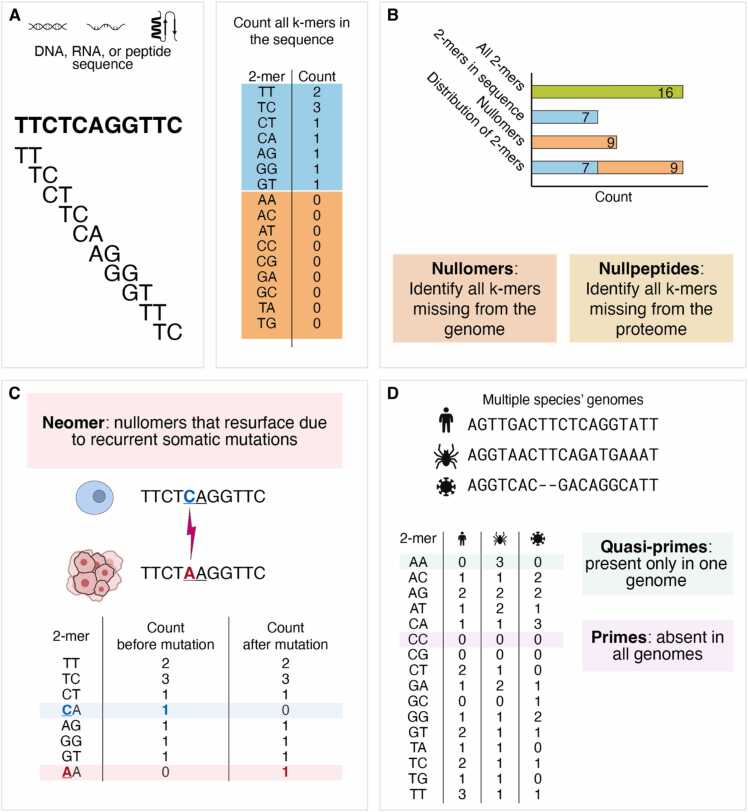
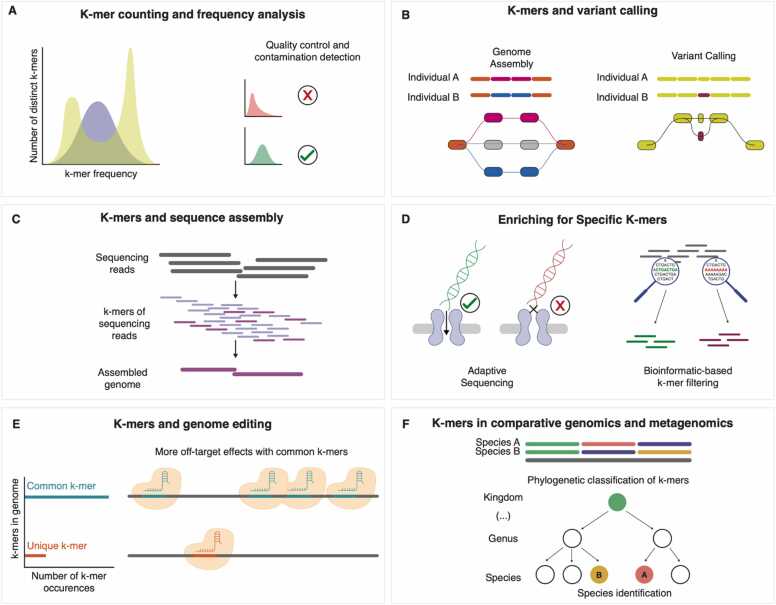
Moeckel Camille, Mareboina Manvita, Konnaris Maxwell A, Chan Candace S Y, Mouratidis Ioannis, Montgomery Austin, Chantzi Nikol, Pavlopoulos Georgios A, Georgakopoulos-Soares Ilias
Institute for Personalized Medicine, Department of Biochemistry and Molecular Biology, The Pennsylvania State University College of Medicine, Hershey, PA, USA.
Department of Bioengineering and Therapeutic Sciences, University of California San Francisco, San Francisco, CA, USA.
Comput Struct Biotechnol J. 2024 May 21;23:2289-2303. doi: 10.1016/j.csbj.2024.05.025. eCollection 2024 Dec.
The rapid progression of genomics and proteomics has been driven by the advent of advanced sequencing technologies, large, diverse, and readily available omics datasets, and the evolution of computational data processing capabilities. The vast amount of data generated by these advancements necessitates efficient algorithms to extract meaningful information. K-mers serve as a valuable tool when working with large sequencing datasets, offering several advantages in computational speed and memory efficiency and carrying the potential for intrinsic biological functionality. This review provides an overview of the methods, applications, and significance of k-mers in genomic and proteomic data analyses, as well as the utility of absent sequences, including nullomers and nullpeptides, in disease detection, vaccine development, therapeutics, and forensic science. Therefore, the review highlights the pivotal role of k-mers in addressing current genomic and proteomic problems and underscores their potential for future breakthroughs in research.
先进测序技术的出现、大规模、多样化且易于获取的组学数据集以及计算数据处理能力的发展推动了基因组学和蛋白质组学的快速发展。这些进展产生的大量数据需要高效算法来提取有意义的信息。k-mer在处理大型测序数据集时是一种有价值的工具,在计算速度和内存效率方面具有多个优势,并具有内在生物学功能的潜力。本综述概述了k-mer在基因组和蛋白质组数据分析中的方法、应用和意义,以及缺失序列(包括零聚体和零肽)在疾病检测、疫苗开发、治疗学和法医学中的效用。因此,本综述强调了k-mer在解决当前基因组和蛋白质组问题中的关键作用,并强调了它们在未来研究中取得突破的潜力。