Builoff Valerie, Shanbhag Aakash, Miller Robert Jh, Dey Damini, Liang Joanna X, Flood Kathleen, Bourque Jamieson M, Chareonthaitawee Panithaya, Phillips Lawrence M, Slomka Piotr J
Departments of Medicine (Division of Artificial Intelligence in Medicine), Imaging and Biomedical Sciences Cedars-Sinai Medical Center, Los Angeles, CA, USA.
Signal and Image Processing Institute, Ming Hsieh Department of Electrical and Computer Engineering, University of Southern California, Los Angeles, CA, USA.
medRxiv. 2024 Jul 16:2024.07.16.24310297. doi: 10.1101/2024.07.16.24310297.
Previous studies evaluated the ability of large language models (LLMs) in medical disciplines; however, few have focused on image analysis, and none specifically on cardiovascular imaging or nuclear cardiology.
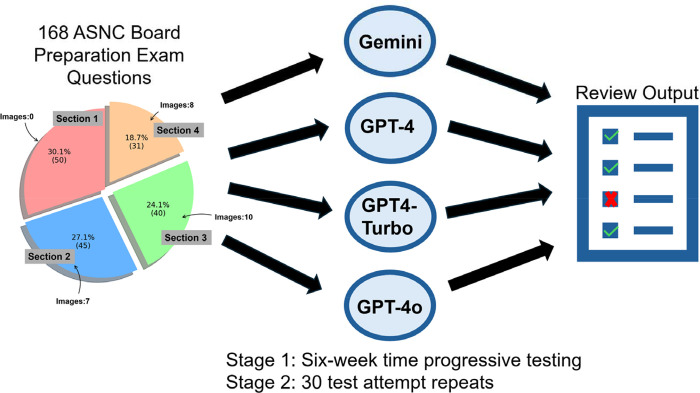
This study assesses four LLMs - GPT-4, GPT-4 Turbo, GPT-4omni (GPT-4o) (Open AI), and Gemini (Google Inc.) - in responding to questions from the 2023 American Society of Nuclear Cardiology Board Preparation Exam, reflecting the scope of the Certification Board of Nuclear Cardiology (CBNC) examination.
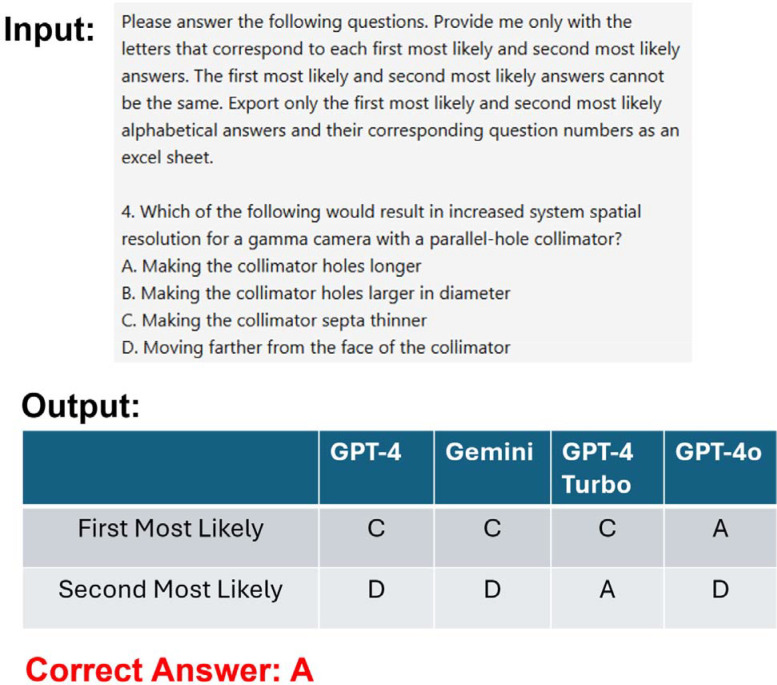
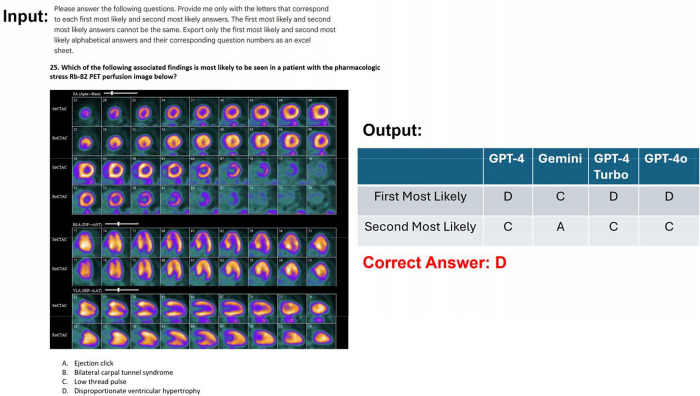
We used 168 questions: 141 text-only and 27 image-based, categorized into four sections mirroring the CBNC exam. Each LLM was presented with the same standardized prompt and applied to each section 30 times to account for stochasticity. Performance over six weeks was assessed for all models except GPT-4o. McNemar's test compared correct response proportions.
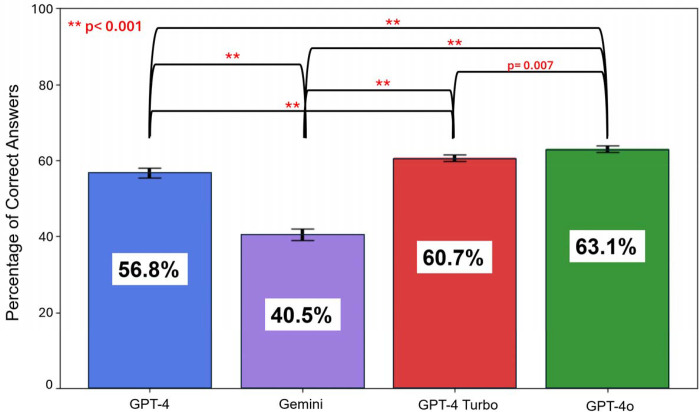
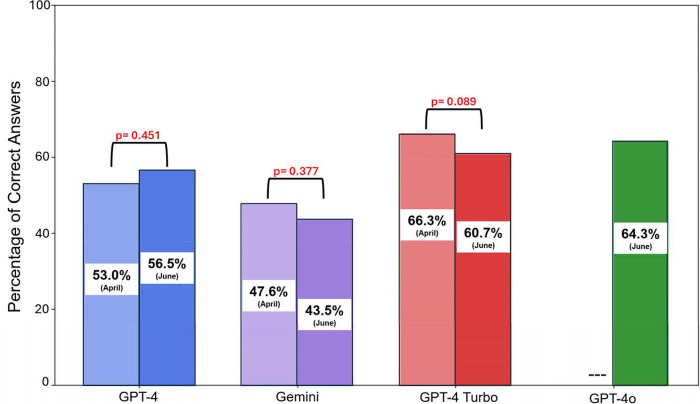
GPT-4, Gemini, GPT4-Turbo, and GPT-4o correctly answered median percentiles of 56.8% (95% confidence interval 55.4% - 58.0%), 40.5% (39.9% - 42.9%), 60.7% (59.9% - 61.3%) and 63.1% (62.5 - 64.3%) of questions, respectively. GPT4o significantly outperformed other models (p=0.007 vs. GPT-4Turbo, p<0.001 vs. GPT-4 and Gemini). GPT-4o excelled on text-only questions compared to GPT-4, Gemini, and GPT-4 Turbo (p<0.001, p<0.001, and p=0.001), while Gemini performed worse on image-based questions (p<0.001 for all).
GPT-4o demonstrated superior performance among the four LLMs, achieving scores likely within or just outside the range required to pass a test akin to the CBNC examination. Although improvements in medical image interpretation are needed, GPT-4o shows potential to support physicians in answering text-based clinical questions.
以往的研究评估了大语言模型(LLMs)在医学领域的能力;然而,很少有研究关注图像分析,且没有专门针对心血管成像或核心脏病学的研究。
本研究评估了四种大语言模型——GPT-4、GPT-4 Turbo、GPT-4omni(GPT-4o)(OpenAI)和Gemini(谷歌公司)——对2023年美国核心脏病学会委员会预备考试问题的回答情况,该考试反映了核心脏病学认证委员会(CBNC)考试的范围。
我们使用了168个问题:141个纯文本问题和27个基于图像的问题,分为四个部分,与CBNC考试相对应。每个大语言模型都收到相同的标准化提示,并应用于每个部分30次,以考虑随机性。除GPT-4o外,对所有模型在六周内的表现进行了评估。使用McNemar检验比较正确回答比例。
GPT-4、Gemini、GPT4-Turbo和GPT-4o正确回答问题的中位数百分比分别为56.8%(95%置信区间55.4% - 58.0%)、40.5%(39.9% - 42.9%)、60.7%(59.9% - 61.3%)和63.1%(62.5 - 64.3%)。GPT4o显著优于其他模型(与GPT-4Turbo相比,p = 0.007;与GPT-4和Gemini相比,p < 0.001)。与GPT-4、Gemini和GPT-4 Turbo相比,GPT-4o在纯文本问题上表现出色(p < 0.001、p < 0.001和p = 0.001),而Gemini在基于图像的问题上表现较差(所有比较p < 0.001)。
GPT-4o在这四种大语言模型中表现出卓越的性能,其得分可能在类似于CBNC考试的及格范围内或略高于该范围。尽管医学图像解读仍需改进,但GPT-4o显示出支持医生回答基于文本的临床问题的潜力。