Department of Pediatrics, "G. D'Annunzio" University of Chieti-Pescara, Chieti, Italy.
Division of Pediatric Rheumatology, "G. D'Annunzio" University of Chieti-Pescara, Chieti, Italy.
Pediatr Rheumatol Online J. 2024 Aug 23;22(1):78. doi: 10.1186/s12969-024-01011-0.
Artificial intelligence (AI) has become a popular tool for clinical and research use in the medical field. The aim of this study was to evaluate the accuracy and reliability of a generative AI tool on pediatric familial Mediterranean fever (FMF).
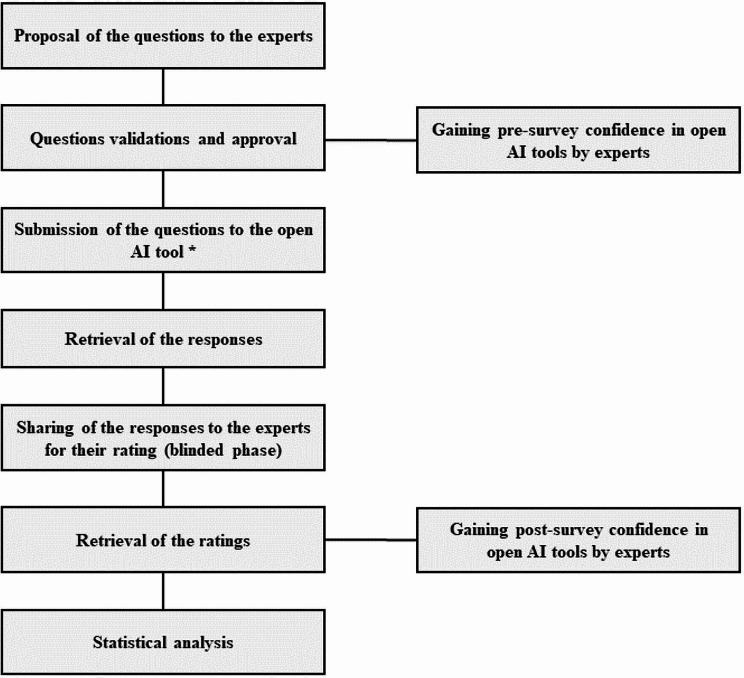
Fifteen questions repeated thrice on pediatric FMF were prompted to the popular generative AI tool Microsoft Copilot with Chat-GPT 4.0. Nine pediatric rheumatology experts rated response accuracy with a blinded mechanism using a Likert-like scale with values from 1 to 5.
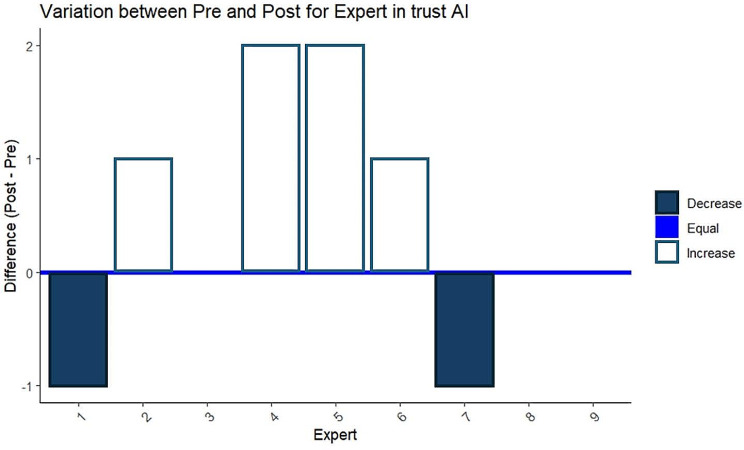
Median values for overall responses at the initial assessment ranged from 2.00 to 5.00. During the second assessment, median values spanned from 2.00 to 4.00, while for the third assessment, they ranged from 3.00 to 4.00. Intra-rater variability showed poor to moderate agreement (intraclass correlation coefficient range: -0.151 to 0.534). A diminishing level of agreement among experts over time was documented, as highlighted by Krippendorff's alpha coefficient values, ranging from 0.136 (at the first response) to 0.132 (at the second response) to 0.089 (at the third response). Lastly, experts displayed varying levels of trust in AI pre- and post-survey.
AI has promising implications in pediatric rheumatology, including early diagnosis and management optimization, but challenges persist due to uncertain information reliability and the lack of expert validation. Our survey revealed considerable inaccuracies and incompleteness in AI-generated responses regarding FMF, with poor intra- and extra-rater reliability. Human validation remains crucial in managing AI-generated medical information.
人工智能(AI)已成为医学领域临床和研究应用的热门工具。本研究旨在评估生成式 AI 工具在儿科家族性地中海热(FMF)中的准确性和可靠性。
向流行的生成式 AI 工具 Microsoft Copilot 与 Chat-GPT 4.0 提出了十五个关于儿科 FMF 的重复三遍的问题。九名儿科风湿病专家使用类似于李克特量表的机制进行盲法评估,对反应准确性进行评分,分值范围为 1 到 5。
初始评估时,整体反应的中位数值范围为 2.00 到 5.00。在第二次评估时,中位数值范围为 2.00 到 4.00,而在第三次评估时,中位数值范围为 3.00 到 4.00。内部评估者的变异性显示出较差到中等的一致性(组内相关系数范围:-0.151 到 0.534)。随着时间的推移,专家之间的一致性水平逐渐降低,正如 Krippendorff 的 alpha 系数值所强调的那样,从第一次响应的 0.136 到第二次响应的 0.132 到第三次响应的 0.089。最后,专家在调查前后对 AI 的信任程度存在差异。
AI 在儿科风湿病学中具有广阔的应用前景,包括早期诊断和管理优化,但由于信息可靠性不确定和缺乏专家验证,仍存在挑战。我们的调查显示,AI 生成的关于 FMF 的反应存在相当大的不准确和不完整,内部和外部评估者的可靠性都较差。在管理 AI 生成的医疗信息时,人工验证仍然至关重要。