Clark Chase M, Kwan Jason C
Division of Pharmaceutical Sciences, School of Pharmacy, University of Wisconsin-Madison, 777 Highland Avenue, Madison, WI 53705, USA.
bioRxiv. 2024 Aug 19:2024.08.16.608329. doi: 10.1101/2024.08.16.608329.
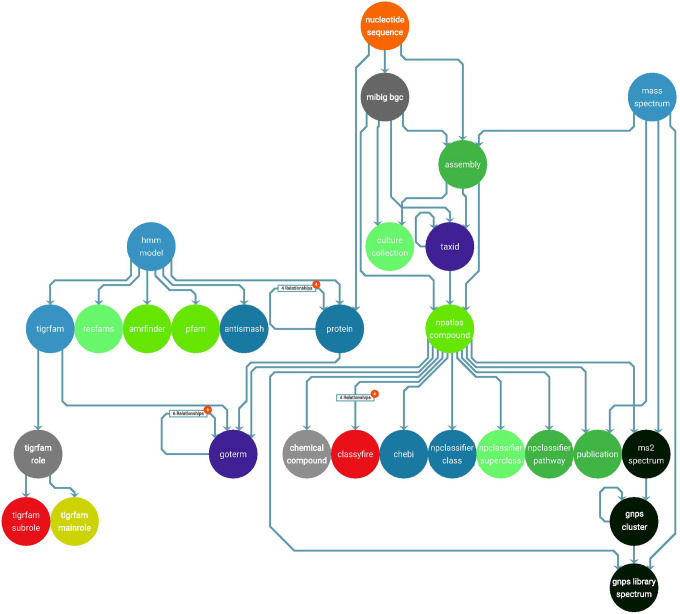
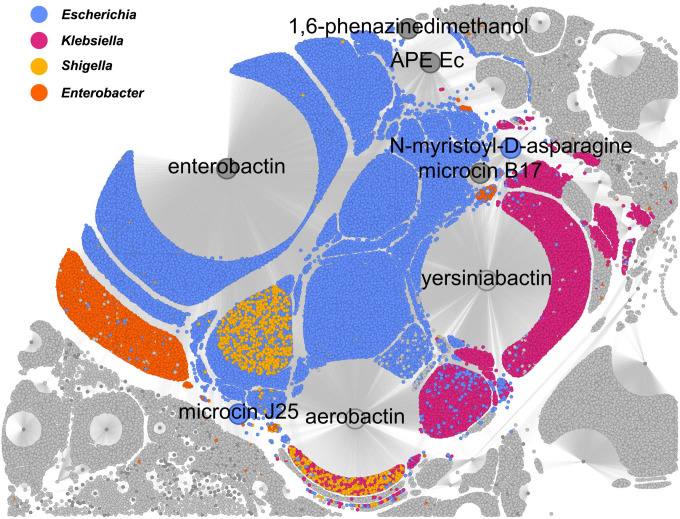
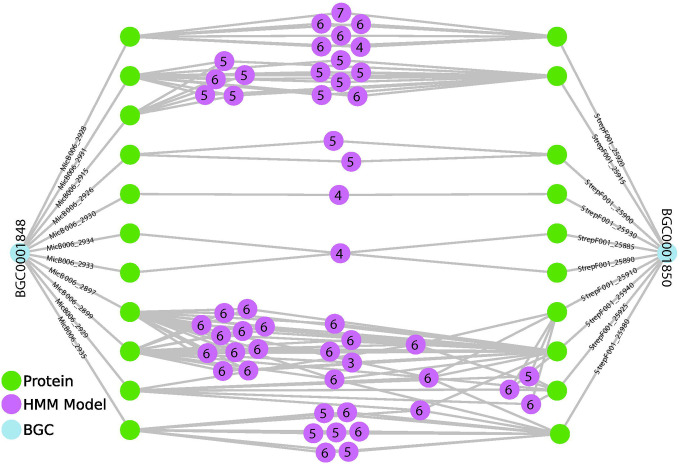
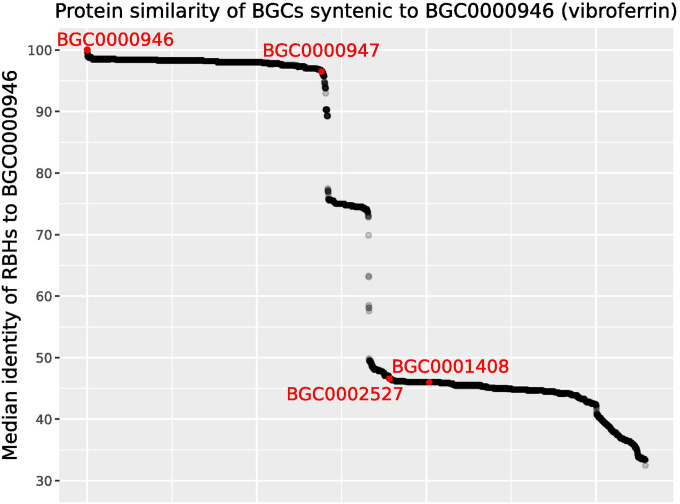
The rapid expansion of multi-omics data has transformed biological research, offering unprecedented opportunities to explore complex genomic relationships across diverse organisms. However, the vast volume and heterogeneity of these datasets presents significant challenges for analyses. Here we introduce SocialGene, a comprehensive software suite designed to collect, analyze, and organize multi-omics data into structured knowledge graphs, with the ability to handle small projects to repository-scale analyses. Originally developed to enhance genome mining for natural product drug discovery, SocialGene has been effective across various applications, including functional genomics, evolutionary studies, and systems biology. SocialGene's concerted Python and Nextflow libraries streamline data ingestion, manipulation, aggregation, and analysis, culminating in a custom Neo4j database. The software not only facilitates the exploration of genomic synteny but also provides a foundational knowledge graph supporting the integration of additional diverse datasets and the development of advanced search engines and analyses. This manuscript introduces some of SocialGene's capabilities through brief case studies including targeted genome mining for drug discovery, accelerated searches for similar and distantly related biosynthetic gene clusters in biobank-available organisms, integration of chemical and analytical data, and more. SocialGene is free, open-source, MIT-licensed, designed for adaptability and extension, and available from github.com/socialgene.
多组学数据的迅速扩展改变了生物学研究,为探索不同生物体之间复杂的基因组关系提供了前所未有的机会。然而,这些数据集的巨大规模和异质性给分析带来了重大挑战。在这里,我们介绍SocialGene,这是一个综合软件套件,旨在将多组学数据收集、分析并组织成结构化的知识图谱,能够处理从小型项目到库规模的分析。SocialGene最初是为加强天然产物药物发现的基因组挖掘而开发的,已在包括功能基因组学、进化研究和系统生物学在内的各种应用中发挥了作用。SocialGene协同的Python和Nextflow库简化了数据摄取、操作、聚合和分析,最终形成一个定制的Neo4j数据库。该软件不仅便于探索基因组共线性,还提供了一个基础知识图谱,支持整合其他不同的数据集以及开发高级搜索引擎和分析工具。本文通过简短的案例研究介绍了SocialGene的一些功能,包括用于药物发现的靶向基因组挖掘、在生物样本库可用生物体中加速搜索相似和远缘相关的生物合成基因簇、化学和分析数据的整合等。SocialGene是免费的、开源的,遵循麻省理工学院许可协议,设计具有适应性和扩展性,可从github.com/socialgene获取。