Department of Biostatistics, University of Michigan, 1415 Washington Heights, Ann Arbor, Michigan, 48109, United States.
Department of Statistics, University of Michigan, 1085 South University, Ann Arbor, Michigan, 48109, United States.
Bioinformatics. 2024 Nov 1;40(11). doi: 10.1093/bioinformatics/btae661.
Microbiome differential abundance analysis (DAA) remains a challenging problem despite multiple methods proposed in the literature. The excessive zeros and compositionality of metagenomics data are two main challenges for DAA.
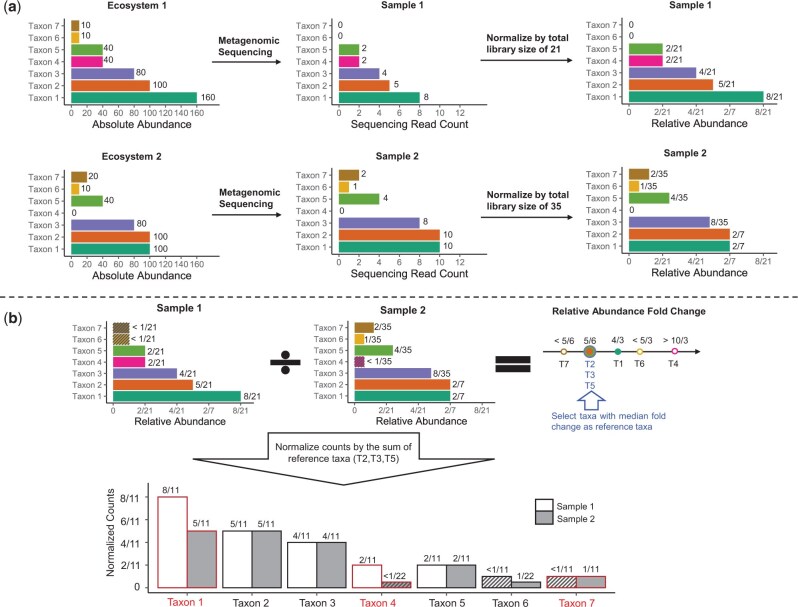
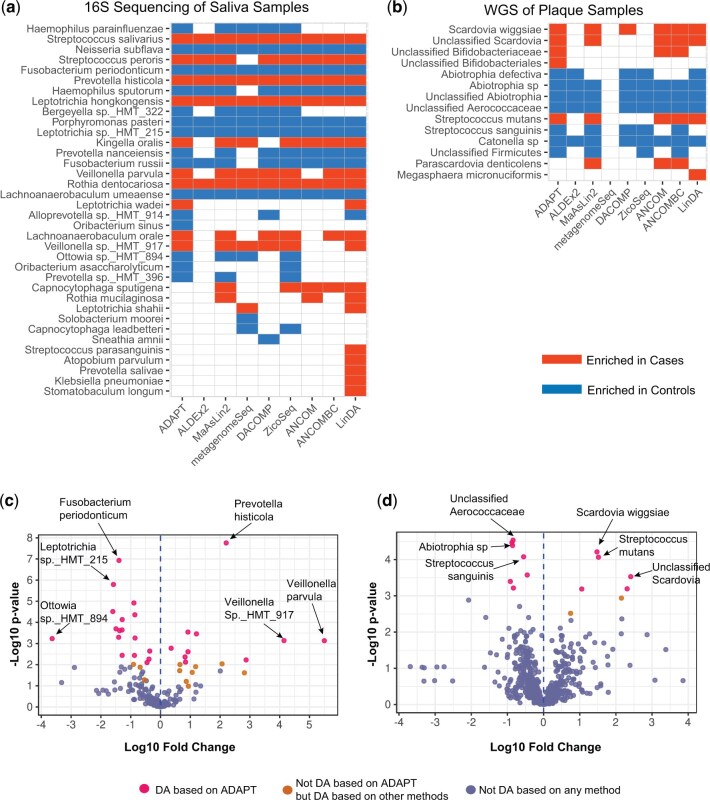
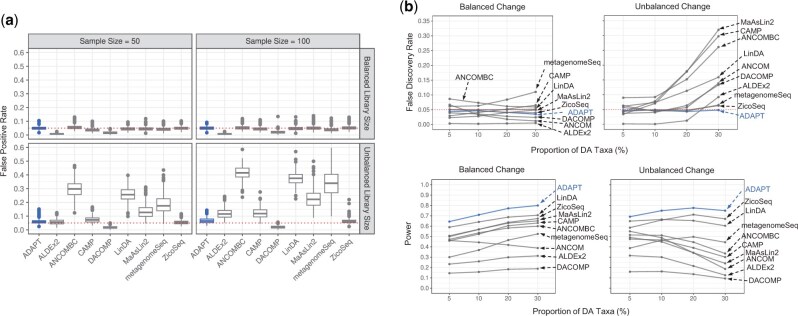
We propose a novel method called "Analysis of Microbiome Differential Abundance by Pooling Tobit Models" (ADAPT) to overcome these two challenges. ADAPT interprets zero counts as left-censored observations to avoid unfounded assumptions and complex models. ADAPT also encompasses a theoretically justified way of selecting non-differentially abundant microbiome taxa as a reference to reveal differentially abundant taxa while avoiding false discoveries. We generate synthetic data using independent simulation frameworks to show that ADAPT has more consistent false discovery rate control and higher statistical power than competitors. We use ADAPT to analyze 16S rRNA sequencing of saliva samples and shotgun metagenomics sequencing of plaque samples collected from infants in the COHRA2 study. The results provide novel insights into the association between the oral microbiome and early childhood dental caries.
The R package ADAPT can be installed from Bioconductor at https://bioconductor.org/packages/release/bioc/html/ADAPT.html or from Github at https://github.com/mkbwang/ADAPT. The source codes for simulation studies and real data analysis are available at https://github.com/mkbwang/ADAPT_example.
尽管文献中提出了多种方法,但微生物组差异丰度分析(DAA)仍然是一个具有挑战性的问题。宏基因组数据的过多零值和组成性是 DAA 的两个主要挑战。
我们提出了一种名为“通过汇集 Tobit 模型分析微生物组差异丰度”(ADAPT)的新方法来克服这两个挑战。ADAPT 将零计数解释为左截断观测值,以避免无根据的假设和复杂的模型。ADAPT 还包括一种合理的方法来选择非差异丰度的微生物组分类群作为参考,以揭示差异丰度的分类群,同时避免假发现。我们使用独立的模拟框架生成合成数据,表明 ADAPT 具有更一致的错误发现率控制和比竞争对手更高的统计功效。我们使用 ADAPT 分析了来自 COHRA2 研究中婴儿唾液样本的 16S rRNA 测序和菌斑样本的 shotgun 宏基因组测序。结果提供了有关口腔微生物组与儿童早期龋齿之间关联的新见解。
R 包 ADAPT 可以从 Bioconductor 在 https://bioconductor.org/packages/release/bioc/html/ADAPT.html 或从 Github 在 https://github.com/mkbwang/ADAPT 安装。模拟研究和真实数据分析的源代码可在 https://github.com/mkbwang/ADAPT_example 获得。