Sanches Pedro H Godoy, de Melo Nicolly Clemente, Porcari Andreia M, de Carvalho Lucas Miguel
MS4Life Laboratory of Mass Spectrometry, Health Sciences Postgraduate Program, São Francisco University, Bragança Paulista 12916-900, SP, Brazil.
Graduate Program in Biomedicine, São Francisco University, Bragança Paulista 12916-900, SP, Brazil.
Biology (Basel). 2024 Oct 22;13(11):848. doi: 10.3390/biology13110848.
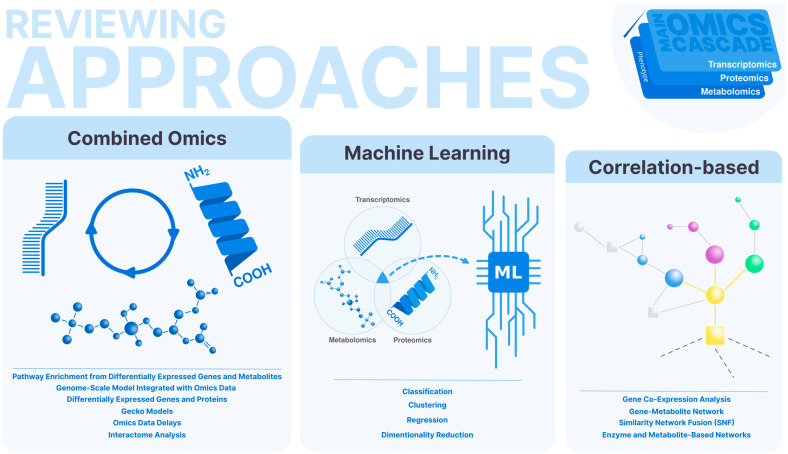
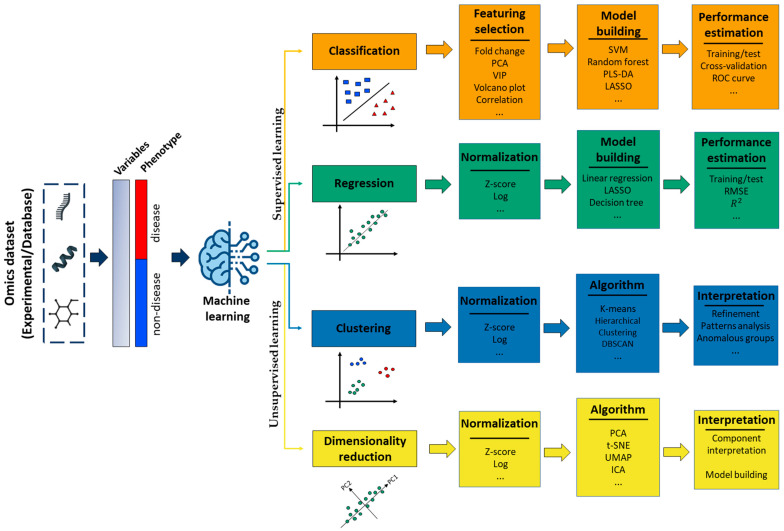
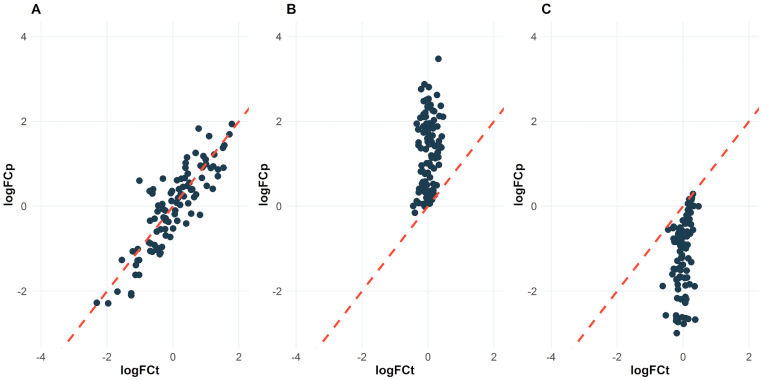
With the advent of high-throughput technologies, the field of omics has made significant strides in characterizing biological systems at various levels of complexity. Transcriptomics, proteomics, and metabolomics are the three most widely used omics technologies, each providing unique insights into different layers of a biological system. However, analyzing each omics data set separately may not provide a comprehensive understanding of the subject under study. Therefore, integrating multi-omics data has become increasingly important in bioinformatics research. In this article, we review strategies for integrating transcriptomics, proteomics, and metabolomics data, including co-expression analysis, metabolite-gene networks, constraint-based models, pathway enrichment analysis, and interactome analysis. We discuss combined omics integration approaches, correlation-based strategies, and machine learning techniques that utilize one or more types of omics data. By presenting these methods, we aim to provide researchers with a better understanding of how to integrate omics data to gain a more comprehensive view of a biological system, facilitating the identification of complex patterns and interactions that might be missed by single-omics analyses.
随着高通量技术的出现,组学领域在表征不同复杂程度的生物系统方面取得了重大进展。转录组学、蛋白质组学和代谢组学是三种应用最广泛的组学技术,每种技术都能为生物系统的不同层面提供独特的见解。然而,单独分析每个组学数据集可能无法全面了解所研究的主题。因此,整合多组学数据在生物信息学研究中变得越来越重要。在本文中,我们综述了整合转录组学、蛋白质组学和代谢组学数据的策略,包括共表达分析、代谢物-基因网络、基于约束的模型、通路富集分析和相互作用组分析。我们讨论了结合组学整合方法、基于相关性的策略以及利用一种或多种组学数据的机器学习技术。通过介绍这些方法,我们旨在让研究人员更好地理解如何整合组学数据以更全面地了解生物系统,从而有助于识别单一组学分析可能遗漏的复杂模式和相互作用。