Yanping Hang, Haixia Zheng, Minmin Yang, Nan Wang, Miaomiao Kong, Mingming Zhao
Department of Respiratory and Critical Care Medicine, Affiliated Nanjing Gaochun People's Hospital, Jiangsu University, Nanjing, 210000, Jiangsu, China.
Sci Rep. 2025 May 16;15(1):17094. doi: 10.1038/s41598-025-01873-8.
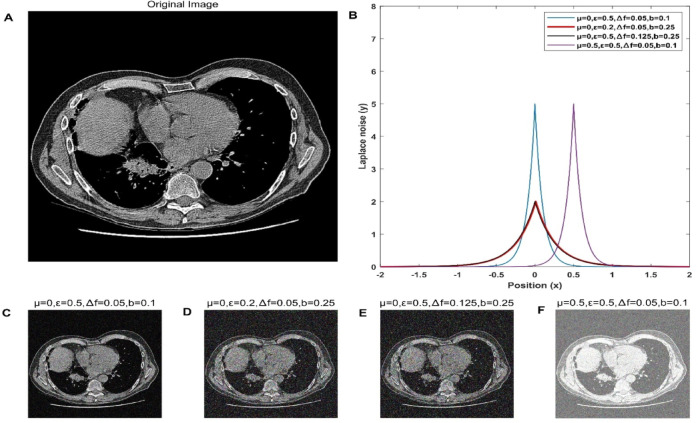
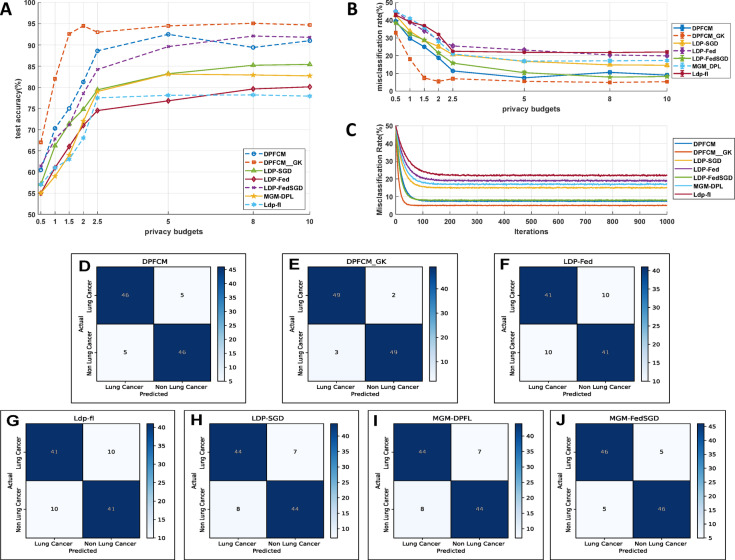
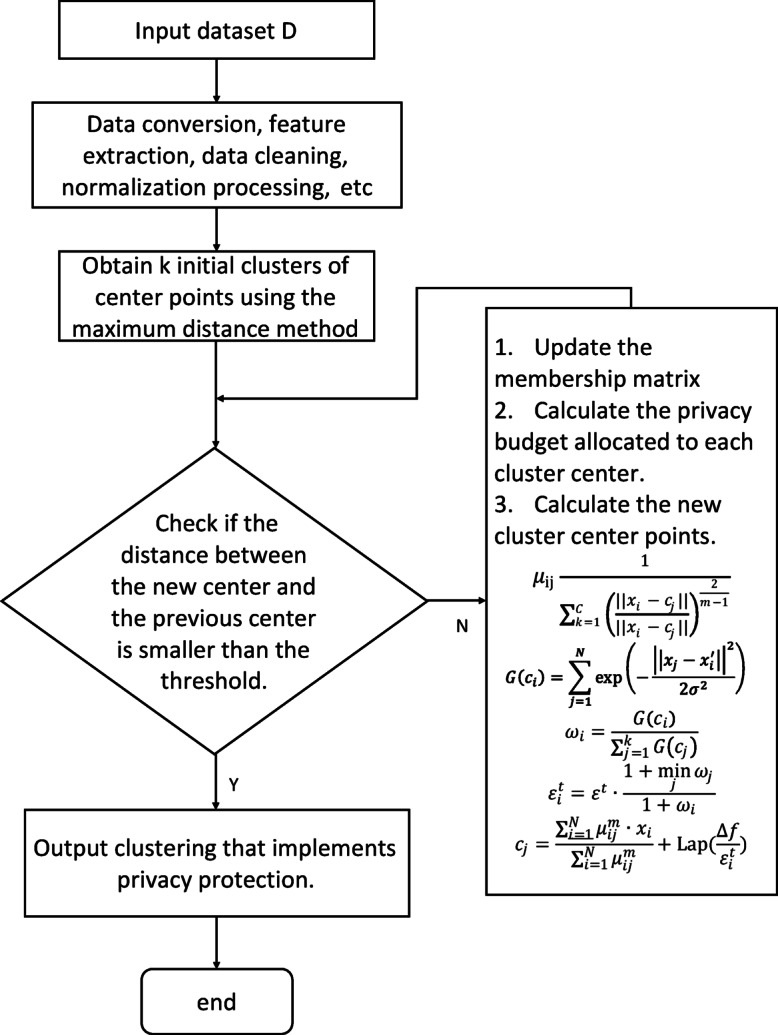
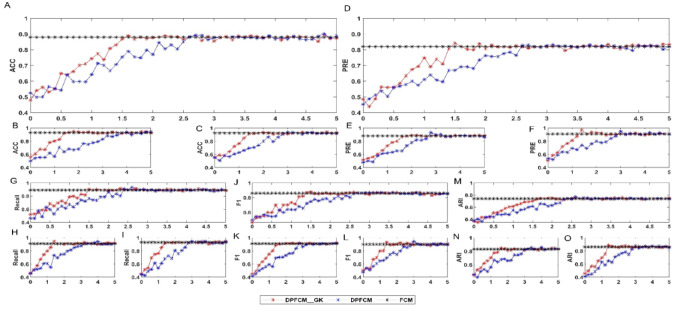
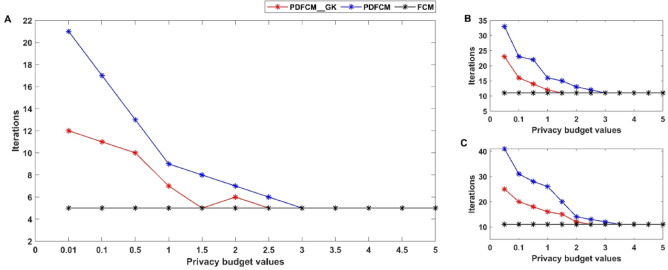
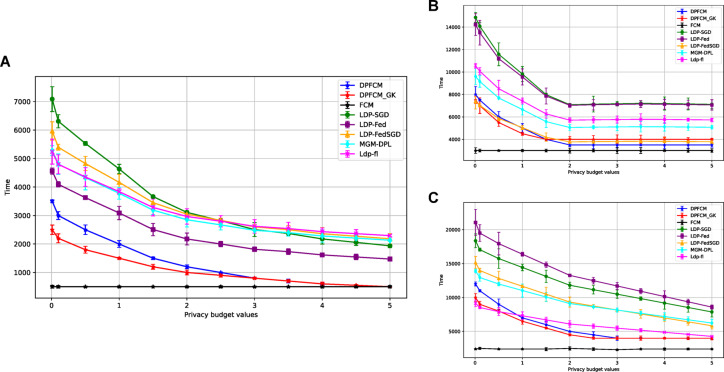
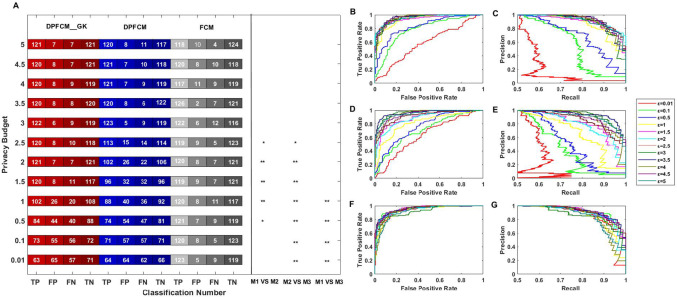
In the age of big data, privacy, particularly medical data privacy, is becoming increasingly important. Differential privacy (DP) has emerged as a key method for safeguarding privacy during data analysis and publishing. Cancer identification and classification play a vital role in early detection and treatment. This paper introduces a novel algorithm, DPFCM_GK, which combines differential privacy with fuzzy c-means (FCM) clustering using a Gaussian kernel function. The algorithm enhances cancer detection while ensuring data privacy. Three publicly available lung cancer datasets, along with a dataset from our hospital, are used to test and demonstrate the effectiveness of DPFCM_GK. The experimental results show that DPFCM_GK achieves high clustering accuracy and enhanced privacy as the privacy budget (ε) increases. For the UCIML, NLST, and NSCLC datasets, it reaches optimal results at lower ε (1.52, 1.24, and 2.32) compared to DPFCM. In the lung cancer dataset, DPFCM_GK outperforms DPFCM within, 0.05 ≤ ε ≤ 2.5, with significant differences (χ = 4.54 ∼ 29.12; P < 0.05), and both methods converge to an accuracy of 94.5% as ε increases. Although differential privacy initially increases iteration counts, DPFCM_GK demonstrates faster convergence and fewer iterations compared to DPFCM, with significant reductions (T= 23.08, 43.47, and 48.93; P<0.05). For the UCIML dataset, DPFCM_GK significantly reduces runtime compared to other models (DPFCM, LDP-SGD, LDP-Fed, LDP-FedSGD, MGM-DPL, LDP-FL) under the same privacy budget. The runtime reduction is statistically significant with T-values of (T = 21.08, 316.24, 102.35, 222.37, 162.23, 159.25; P < 0.05). DPFCM_GK still maintains excellent time efficiency when applied to the NLST and NSCLC datasets(P < 0.05). For the LLCS dataset, For the LLCS dataset, the DPFCM_GK demonstrates significant improvement as the privacy budget increases, especially in low-budget scenarios, where the performance gap is most pronounced (T=4.20, 8.44, 10.92, 3.95, 7.16, 8.51, P < 0.05). These results confirm DPFCM_GK as a practical solution for medical data analysis, balancing accuracy, privacy, and efficiency.
在大数据时代,隐私,尤其是医疗数据隐私,正变得越来越重要。差分隐私(DP)已成为在数据分析和发布过程中保护隐私的关键方法。癌症识别和分类在早期检测和治疗中起着至关重要的作用。本文介绍了一种新颖的算法DPFCM_GK,它将差分隐私与使用高斯核函数的模糊c均值(FCM)聚类相结合。该算法在确保数据隐私的同时增强了癌症检测能力。使用三个公开可用的肺癌数据集以及我们医院的一个数据集来测试和证明DPFCM_GK的有效性。实验结果表明,随着隐私预算(ε)的增加,DPFCM_GK实现了高聚类准确率并增强了隐私保护。对于UCIML、NLST和NSCLC数据集,与DPFCM相比,它在较低的ε(1.52、1.24和2.32)下达到了最优结果。在肺癌数据集中,在0.05≤ε≤2.5范围内,DPFCM_GK优于DPFCM,差异显著(χ = 4.54 ∼ 29.12;P < 0.05),并且随着ε的增加,两种方法都收敛到94.5%的准确率。尽管差分隐私最初会增加迭代次数,但与DPFCM相比,DPFCM_GK收敛更快且迭代次数更少,有显著减少(T = 23.08、43.47和48.93;P < 0.05)。对于UCIML数据集,在相同隐私预算下,与其他模型(DPFCM、LDP - SGD、LDP - Fed、LDP - FedSGD、MGM - DPL、LDP - FL)相比,DPFCM_GK显著减少了运行时间。运行时间的减少具有统计学意义,T值为(T = 21.08、316.24、102.35、222.37、162.23、159.25;P < 0.05)。当应用于NLST和NSCLC数据集时,DPFCM_GK仍然保持出色的时间效率(P < 0.05)。对于LLCS数据集,随着隐私预算的增加,DPFCM_GK表现出显著改善,尤其是在低预算场景中,性能差距最为明显(T = 4.20、8.44、10.92、3.95、7.16、8.51,P < 0.05)。这些结果证实DPFCM_GK是医疗数据分析的一种实用解决方案,在准确性、隐私和效率之间取得了平衡。