
在这个大模型“卷”翻天的时代,我们对 AI 的胃口越来越大。最早我们只希望它能写首打油诗,后来希望它能聊几句天,现在?我们恨不得把整本《红楼梦》、几万行的代码库、或者长达几十页的财报直接扔给它,然后指着屏幕说:“读完它,告诉我哪里有问题。”
这时候,你可能会发现一个尴尬的现象:平时反应挺快的 AI,一旦遇到这种“长篇大论”,往往就变笨了。要么是读半天没反应(延迟高),要么是读着读着显存爆了(成本高),最惨的是读完了之后“瞎编”,把开头的内容忘得一干二净。
这背后的核心矛盾在于,目前主流 AI 模型普遍采用的“全注意力机制”(Full Attention),本质上是一个“完美主义者”。
想象一下,如果你要从一本书里找一个答案,全注意力机制的做法是:把书里的每一个字都盯着看一遍,并且计算每一个字和其他所有字之间的关系。 当书只有 100 页时,这还能应付;但当书有 1000 页、10000 页时,这种计算量是呈指数级爆炸增长的。研究数据显示,当处理 64k(约 6.4 万个 token)长度的文本时,AI 生成每一个新字,光是“回顾前文”这一项工作,就要占用 70%-80% 的时间。
既要 AI 记得多(长上下文),又要 AI 跑得快(低延迟),这似乎成了一个不可兼得的死结。
然而,DeepSeek 团队最近发布的一项名为 NSA(Native Sparse Attention,原生稀疏注意力) 的研究,似乎找到了一把解开这个死结的钥匙。这就好比让 AI 学会了人类的“速读”技巧——不再死盯着每个字看,而是有的放矢地抓重点。结果如何?
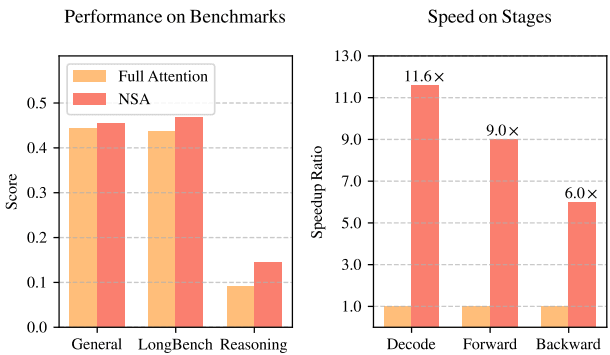
如图[1]所示,DeepSeek 的 NSA 架构不仅在处理 64k 长文时速度暴涨 11.6 倍,而且在很多任务上的表现甚至比那些“逐字逐句”读的 AI 还要好。
既然“全注意力”太慢,那能不能让 AI “偷个懒”,只关注重要的信息?这就是“稀疏注意力”(Sparse Attention)的初衷。这就好比你在准备考试,不需要把整本教材背下来,只需要看重点摘要和考前划的重点。
但是,以往的“稀疏注意力”技术往往有两个大坑:
DeepSeek 的 NSA 架构,顾名思义,是 “原生”(Native) 的。也就是说,这个 AI 从“娘胎”里(预训练阶段)就开始学习如何高效地分配注意力,而不是事后打补丁。同时,它是专门对着显卡的脾气设计的,主打一个 “硬件友好”。
具体来说,NSA 将 AI 的注意力分配成了三路“纵队”,分工明确,各司其职。我们可以结合图[2]来看看这个精妙的设计:
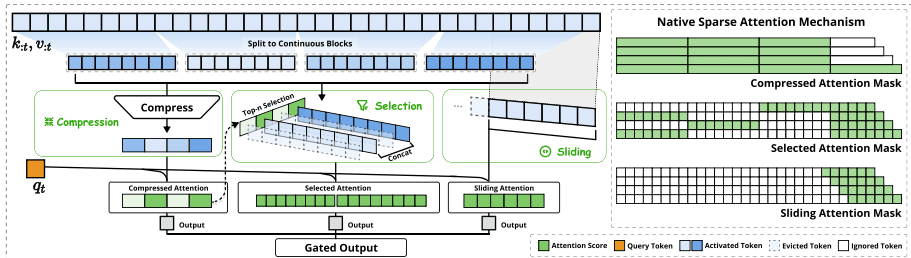
这是 NSA 的第一层策略。它把那些比较久远的、不够紧急的信息,像压缩饼干一样打包起来。比如前文有一大段关于“天气”的描写,AI 不需要记住每一个形容词,只需要生成一个“粗粒度”的压缩包,代表“这里描写了天气”即可。这让 AI 能够用极小的代价,保留对全局信息的掌控,不至于读了后文忘了前文的大概。
这是最关键的一步。在压缩信息的基础上,AI 会根据当前的问题,动态地去“回看”那些真正重要的原始片段。比如你问“主角最后怎么死的?”,AI 就会精准定位到书的结局部分,把那些细节“调取”出来进行精细处理。这种“掐尖”式的选择,既保证了精度,又避免了无效计算。
无论前文多长,哪怕是几千页之前的内容,AI 处理当前这一句话时,最相关的往往是前几句话。比如你说“我喜欢吃苹果”,下一句接“因为它很甜”,“它”指代的就是紧挨着的“苹果”。NSA 保留了一个“滑动窗口”,专门负责处理这些就在眼前的、局部的上下文信息,确保对话的连贯性。
通过这“三板斧”,NSA 成功实现了在不牺牲理解能力的前提下,大幅削减了计算量。
很多人可能不知道,虽然我们常说“算法牛逼”,但在实际运行中,往往是“算法设想很美好,显卡跑得想睡觉”。
传统的稀疏注意力算法之所以落地难,是因为它们太“零碎”了。这就好比你去超市买菜,如果你一会跑去拿个苹果,一会跑去拿瓶酱油,再跑回去拿个香蕉,大把的时间都浪费在“走路”(数据读取)上了,而不是“买单”(计算)。显卡最讨厌这种零散的内存读取,它喜欢的是整整齐齐、大块大块地处理数据。
DeepSeek 的 NSA 在这方面做了极为硬核的优化,被称为 “硬件对齐”(Hardware-Aligned) 设计。
如图[3]所示,NSA 设计了一套专门的“交通指挥系统”(Kernel Design)。它不再让显卡去抓取单个的数据点,而是以“块”(Block)为单位进行操作。它把需要计算的查询(Query)按组打包,一次性把相关的数据块搬运到显卡的高速缓存(SRAM)里。这就像是把你要买的所有东西都集中在一个货架上,你伸手就能拿完,不用满超市乱跑。
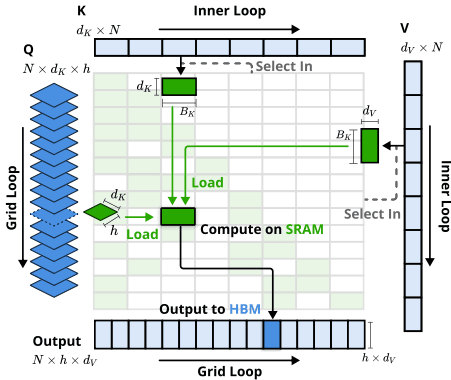
这种设计极大地提高了 “算力利用率”,让显卡不再因为等待数据传输而空转,把理论上的“少算点”变成了实打实的“跑得快”。
很多人担心:AI “偷懒”跳着读,会不会漏掉关键信息?会不会变笨?
为了验证这一点,DeepSeek 团队把 NSA 放到了一系列“地狱级”难度测试中,结果令人大跌眼镜——它不仅没变笨,在很多方面反而超越了那些“老实人”(全注意力模型)。
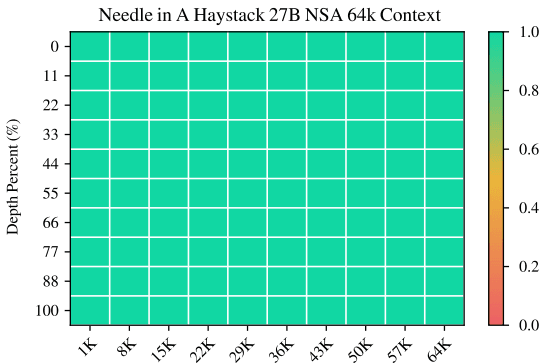
长文本模型最怕的就是“大海捞针”测试:在长达几万字的废话中,随机插入一句关键指令(比如“密码是123456”),看 AI 能不能找出来。
如图[4]所示,这是一张展示 AI 找回率的热力图。横轴代表文本长度(从 1k 到 64k),纵轴代表关键信息藏匿的位置(从开头到结尾)。可以看到,整张图呈现出一片完美的翠绿色,这意味着准确率是 100%。无论关键信息藏在 6.4 万字的哪个角落,NSA 凭借其“粗看+精读”的策略,都能精准地把它揪出来。这证明了它虽然“稀疏”,但绝不“疏漏”。
在更广泛的通用基准测试(涵盖知识问答、代码、数学等)中,NSA 同样表现强悍。数据显示,在 9 项权威测试中,NSA 有 7 项都击败了全注意力模型。特别是在需要复杂逻辑的数学推理任务中,NSA 甚至展现出了独特的优势。
为什么“少读点”反而效果更好?一种可能的解释是:全注意力机制有时候会引入太多的“噪音”。就像人读书一样,如果连页眉页脚和无关的废话都死记硬背,反而会干扰对核心逻辑的理解。NSA 通过筛选机制,实际上起到了“去噪”的作用,让模型更专注于那些真正有价值的信息流。
最后,我们来看看最激动人心的部分——速度。
对于我们普通用户来说,最直观的感受就是:不用等了。
随着文本长度的增加,NSA 的速度优势像滚雪球一样越来越大。如图[5]所示,在训练阶段(前向和后向传播),当处理长序列时,NSA 相比全注意力机制展现出了巨大的速度提升,原本耗时的长文训练变得轻盈高效。
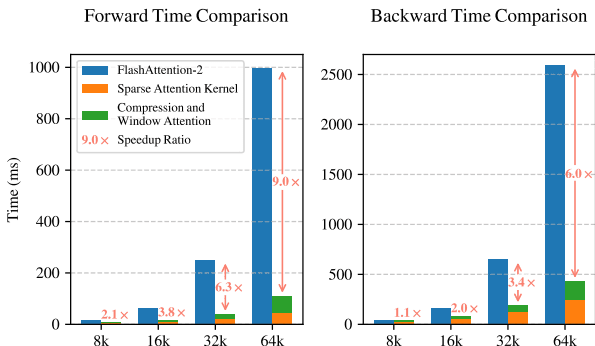
而在我们最感知的推理阶段,如图[1]右侧的图表所示,NSA 的表现更是惊人:
想象一下,以前因为算力成本太高,很多长文档分析功能只能是企业级用户的专属;而有了 NSA 这种技术,未来我们在手机上跑一个能读完你整个微信聊天记录并帮你总结重点的 AI 助手,将不再是梦。
DeepSeek 的这项研究,给盲目堆算力的大模型竞赛泼了一盆清醒的冷水,也指明了一条新路。它告诉我们,通往更强 AI 的道路,不一定非要依靠蛮力去穷尽所有数据关系。
通过让 AI 学会“断舍离”,学会原生、自适应地分配注意力,我们不仅能打破长文本处理的算力枷锁,还能让 AI 变得更加聪明和高效。NSA 只是一个开始,它预示着一个更轻量、更普及的长文本 AI 时代正在到来。或许不久的将来,你的 AI 助手不仅能秒读万字长文,还能在你刚发完资料的一瞬间,就微笑着把核心观点推送到你的面前。
本文由超能文献“资讯AI智能体”基于4000万篇Pubmed文献自主选题与撰写,并经AI核查及编辑团队二次人工审校。内容仅供学术交流参考,不代表任何医学建议。
分享

本文探讨了传统用药模式在治疗炎症性皮肤病(如牛皮癣)时的局限性,特别是“千人一量”的弊端。详细介绍了如何通过“模型引导的精准给药(MIPD)”数据模型,结合患者的体重、白蛋白水平、免疫原性等个体特征,主动预测并计算专属药量,从而实现个性化精准治疗。文章对比了MIPD与经验性给药、传统TDM的优劣,并讨论了精准用药的成本效益、落地挑战及未来发展方向,强调了数字化干预对优化药物使用、减少医疗浪费和提升患者疗效的重要性。

动植物在进化中各自独立地发展出相似的微型RNA分子(piRNAs和phasiRNAs),用于保护生殖细胞,确保基因组稳定和繁衍成功。文章探讨了它们在压制跳跃基因、调节基因表达和分子生成机制上的异同,并指出了未来的研究方向。

全球阿尔茨海默病研究主要集中在西方富裕国家,忽视了占60%以上患者的低收入和中等收入国家。这种"错位"导致现有药物和认知可能不适用于非西方人群,基因和环境差异是关键。文章提出通过AI、轻量化技术和多维度协作(参与者、研究者、方法)来打破地域壁垒,实现更具包容性的全球痴呆症研究。

本文深入探讨了胰淀素(Amylin)在减重和糖尿病治疗中的突破性作用,特别是其与GLP-1药物联合使用后,如何实现超15%的惊人减重效果并减少肌肉流失。

中国药科大学科研团队开发“五维紫外熔解/退火”(5DUVMA)新方法,揭示了特殊四链DNA(i-motif)在复杂环境(温度、酸碱度、盐分)下的行为规律,发现其“怕热、怕碱、怕盐”的反常识特性,并构建了首个多维环境数学模型,为智能纳米药物和生物传感器的开发提供新思路。