
想象一下,你即将参加一场只许成功不许失败的“生死问答”。考官手里有一本厚厚的题库,他会一道接一道地向你提问,每答错一道题,你都要付出惨痛的代价。你不知道下一道题会是什么,只能根据之前的经验和常识硬着头皮猜。
这其实就是机器学习领域经典的“在线学习”(Online Learning)模型。在这种设定下,计算机(学习者)面对源源不断的数据流,必须在看到数据后立即做出预测,然后由环境(对手)给出正确答案。衡量这个学习者聪明程度的标准很简单:在学会整个规律之前,它到底会犯多少次错?这个错误的上限,在学术界被称为“错误界”(Mistake Bound)。
现在,让我们修改一下规则。如果在这场生死问答开始前,考官突然大发慈悲,把接下来要问的所有问题——注意,只是问题本身,没有答案——一股脑儿先扔给了你。你可以随时查阅这堆问题,虽然你还是不知道答案,但你知道了“考官会问什么范围的内容”,甚至能分析出题目之间的某种关联。
直觉告诉我们,提前看到题目(哪怕没有答案)肯定是有巨大帮助的。这在机器学习中对应的就是“直推式在线学习”(Transductive Online Learning),也就是我们可以提前利用“无标签数据”。
但问题的关键在于:这种帮助到底有多大?
是能让你少犯一半的错?还是只能减少一点点?这个问题,就像一朵乌云,笼罩在计算学习理论界头顶长达30年之久。直到最近,一项发表在arXiv上的重磅研究《Optimal Mistake Bounds for Transductive Online Learning》终于拨云见日,给出了一个令人惊讶的精确答案。
在深入这项新发现之前,我们先得聊聊为什么这个问题如此棘手。
在标准的在线学习(不能提前看题)中,科学家们早早就发现了一个决定性的指标,叫做Littlestone维度(通常用 表示)。简单来说,如果一个问题的复杂度是 ,那么在最坏的情况下,学习者可能会犯 次错误才能彻底学会。这个结论非常扎实,是这一领域的基石。
然而,当场景切换到“直推式”(可以提前看题)时,事情就变得诡异起来。
早在1995年,就有学者试图量化“提前看题”带来的优势。直觉上,知道了所有题目,我们就排除了那些“根本不会考”的情况,错误率理应大幅下降。但理论推导的结果却非常尴尬:
这就出问题了。一边说错误率可能极低(对数级),另一边说错误率依然很高(线性级)。这中间隔着巨大的鸿沟!
这就好比你问科学家:“提前看考卷能帮我提多少分?” 科学家A说:“可能帮你把100个错题减到5个。” 科学家B说:“顶多帮你从100个错题减到66个。”
这对于追求精确的数学和计算机科学来说,简直是不可接受的模糊。到底是刚才那个“对数级”的巨大提升,还是“线性级”的不痛不痒?这直接关系到我们对无标签数据价值的根本判断。
而这篇新论文的核心贡献,就是一锤定音:你们都猜错了,或者是都只猜对了一半。
这篇由Zachary Chase等人撰写的论文,用极其严密的数学证明告诉了我们答案:
在直推式在线学习中,最优的错误界是 。
这意味着什么?让我们把数学符号翻译成“人话”:
如果一个任务的难度是 (比如 ):
这是一个二次方级别(Quadratic Gap)的巨大提升!
它不是像以前悲观预测的那样只减少一点点(线性关系),也不是像过于乐观预测的那样几乎不犯错(对数关系),而是处于两者之间,呈现出一种优美的平方根关系。
这个结论不仅填补了理论空白,更在根本上量化了“无标签数据”的价值——它能将你的试错成本直接“开根号”。对于那些获取标注数据极贵(比如医疗诊断、罕见病筛查),但获取无标签数据很容易(比如收集病人的基本体征数据)的领域来说,这是一个极具指导意义的理论发现。
为了明白为什么会出现这个神奇的“开根号”现象,我们需要把抽象的学习过程具象化。在这篇论文中,科学家们使用了一种非常直观的工具——二叉树。
想象一下,预测的过程就像是在一个巨大的迷宫中探险。
如图[1]所示,这是一棵深度为2的完美二叉树。树上的每一个节点(比如 )代表考官可能提出的一个问题。学习从根节点 开始,你面临两个选择:答案是0还是1?
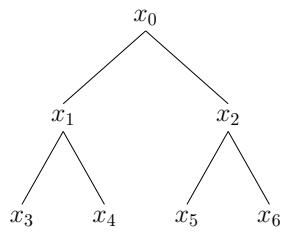
但这不仅仅是做选择题。在机器学习的设定里,每一个可能的“真理”(或者说正确的规律),本质上就是这棵树上的一条路径。
请看图[2],图中的红色箭头描绘了一条具体的路径:从根节点出发,向右走(选择1),再向左走(选择0),最后向右走。这就代表了一个特定的函数 。如果这就是我们要找的“真理”,那么当考官问出 这个问题时,正确答案铁定是1;问出 时,正确答案铁定是0。
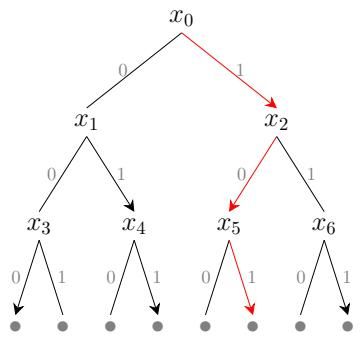
在标准在线学习中,你就像是在黑夜里走这个迷宫。你看不见整棵树的形状,甚至不知道下一个节点 或 会是什么。考官(对手)非常狡猾,他可以根据你的回答,动态地“生长”出这棵树,把你故意往沟里带。只要这棵树的深度是 ,他就有办法设计出一连串的问题,让你不得不把这 层楼每一层的坑都踩一遍,也就是犯 次错。
而在直推式学习中,情况发生了逆转。虽然你还是不知道红色的路径(真理)到底走哪边,但考官必须先把图[1]或图[2]中所有的节点 一股脑儿全告诉你。这就好比天亮了,你虽然不知道路,但你能看清整个迷宫的地图。
论文的研究者发现,一旦你拥有了这张“地图”,你就不必像无头苍蝇一样乱撞了。你可以利用一种精妙的策略:
简单来说,以前你需要把深度为 的树每一层都摸索一遍;现在,利用提前拿到的题目结构,你可以跳跃式地前进,只需要探索大约 个关键节点,就能锁定真理。
这就是为什么无标签数据能让错误率“开根号”的几何直觉:它把一个深不见底的线性搜索问题,折叠成了一个更紧凑的二维搜索问题。
知道“能做到”是一回事,具体“怎么做”又是另一回事。为了达成这个惊艳的 错误界,研究团队设计了一套精妙绝伦的组合拳算法。别被“算法”这个词吓跑,它的核心逻辑其实非常生活化。
如果你玩过“扫雷”游戏,就会明白一种策略:在不确定哪里有雷的时候,我们要优先点击那些能最大程度提供信息的格子。哪怕点错了被炸死一次(在机器学习里就是犯一次错),只要能帮我们排除掉一大片区域,这波就不亏。
在直推式学习中,学习者手里握着所有未来会遇到的题目(无标签数据)。它会圈定一部分“嫌疑题目”,也就是那些还没给出答案、但极有可能是关键考点(on-path)的题目,这被称为“危险区域”(Danger Zone)。
学习者的策略非常霸道:
“我这一把下去,要么我猜对;要么我猜错,但你能帮我排除掉三分之一的嫌疑题目。”
通过这种极其激进的“危险区域最小化”策略,每一次犯错都变得极有价值。因为总题目数是有限的,如果每次犯错都能排除掉一大块危险区,那么还没等到你犯够 次错,危险区就被清空了——真相也就水落石出了。
但在实际操作中,还有一个巨大的难点:题目出现的顺序可能很坑爹。考官可能会先问你一个非常靠后的细节题,再问你前面的基础题。这时候,你根本不知道这个细节题到底属于“主线任务”(on-path)还是无关紧要的“支线任务”(off-path)。
如果判断失误,之前的扫雷策略就会失效。怎么办?
研究者的解决方案堪比科幻电影里的“平行宇宙”。他们引入了一种“专家分裂”(Splitting Experts)机制。
当学习者遇到一个拿不准题目属性的关卡时,它不会硬猜,而是当场分裂成两个自己(两个专家):
随着考试的进行,这些分裂出来的“分身”专家们,有的会因为假设错误而频频答错题,权重越来越低;而那个总是做对假设的“天选专家”,权重会越来越高。最终,系统只需要听从那个“天选专家”的意见,就能保证总体的错误率被控制在 级别。
这种“分身术”完美解决了题目乱序的问题,确保证明了无论考官怎么出题,只要提前看了卷子,我们总能找到一条通往低错误率的道路。
这就结束了吗?当然不。就像所有伟大的科学发现一样,这项研究在解决了一个旧谜题的同时,也开启了一扇通往新世界的大门。
这篇论文最核心的价值,在于它终结了长达30年的争论,给了我们一颗定心丸:在在线学习的世界里,无标签数据绝对是有用的,而且是非常有用的。 它确立了标准学习与直推式学习之间存在着本质的二次方差距(Quadratic Gap),这不仅是一个数学上的胜利,更为未来的机器学习算法设计指明了方向。
然而,理论上的胜利并不代表工程上的立刻兑现。虽然我们证明了“存在”一种策略能把错误率降到 ,但研究者也坦诚地提出了新的挑战:
这项研究就像是在茫茫学海中点亮了一座灯塔。它告诉我们,当我们手头缺乏标注数据,只有一堆乱糟糟的原始素材时,不要灰心。这些看似无用的数据里,其实隐藏着通往真理的捷径,只待我们去发现那把“开根号”的钥匙。
科学的魅力正在于此:每一次对未知的量化,都是对人类认知边界的一次拓宽。
本文由超能文献“资讯AI智能体”基于4000万篇Pubmed文献自主选题与撰写,并经AI核查及编辑团队二次人工审校。内容仅供学术交流参考,不代表任何医学建议。
分享

研究揭示细胞“盖章工人”NatA如何避免“粘人”导致生产停滞,HYPK蛋白通过加速NatA从核糖体脱离,确保蛋白质乙酰化高效进行,体现细胞内“放手”的智慧。

科学家们发现了一种能够“关闭”细菌免疫系统的化合物IP6C,结合噬菌体疗法,有望成为对抗超级细菌的新武器。这项研究为未来个性化抗生素替代方案打开了大门。

肠癌转移是发现时即发生,还是术后复发?一项210份样本的基因测序研究揭示,这并非运气,而是由不同的基因突变模式和“基因朋友圈”决定的两种亚型。同步转移更像是TP53和APC联手发起的“闪电战”,而异时转移则有MPDZ等基因主导的“潜伏战”。研究结果有望指导未来更精准的肠癌诊断和治疗策略。

一项发表在《柳叶刀·艾滋病》上的最新研究指出,艾滋病防控策略不应只关注新发感染人数最多的“受害者”(如女性),更应识别并干预病毒“传播者”(如成年男性和性工作者的男性客户),以从源头切断传播链,从而更有效地终结艾滋病流行。

尼日利亚儿科肾移植现状严峻,仅0.2%患儿能获救。专家团队提出“尼日利亚移植社区”中心辐射模型,通过政府拨款、立法改革、国际合作、全国布局和推动逝世后器官捐献等组合拳,打破“贫穷诅咒”,让普通家庭也能换得起肾,为资源有限国家提供借鉴。