
在人工智能席卷全球的今天,我们已经习惯了AI能写诗、作画甚至生成视频。但在3D视觉领域,一直存在着一只“拦路虎”——昂贵且稀缺的3D标注数据。现有的主流3D模型,大多像是一个需要老师手把手教的学生,训练时必须提供精确的“标准答案”,比如相机的具体位置、拍摄角度以及场景的几何形状。
然而,获取这些数据不仅成本高昂,还需要使用像COLMAP这样复杂的传统算法进行漫长的计算。更糟糕的是,如果面对是一面白墙或者反光的玻璃,这些传统算法往往会“两眼一抹黑”,算出的数据全是错的,直接导致AI学废了。
但是,现在规则变了。
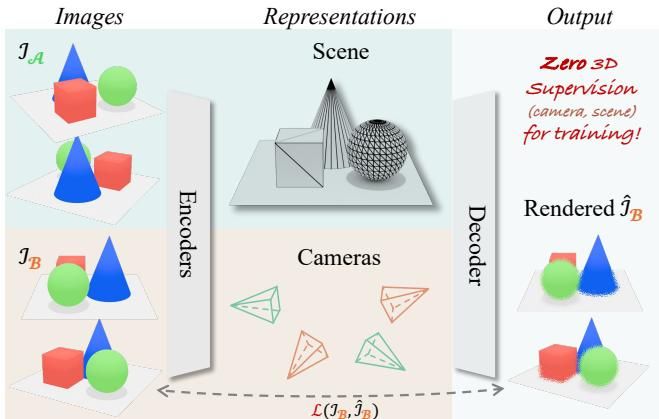
来自得克萨斯大学奥斯汀分校、Adobe研究室等机构的研究人员提出了一种名为 RayZer 的全新模型。它完全打破了对3D标注的依赖,不需要知道相机的位姿,也不需要场景几何信息,仅凭几张普通的照片,就能通过“自学”完美重建3D场景,其效果甚至反超了那些依赖昂贵标注数据的“高配”模型。
想象一下,如果你想教会一个AI认识“杯子”的3D形状,传统的方法是:
这个“必须”就是问题的关键。在实验室里,我们可以用精密的仪器测量这些数据。但在现实世界中,互联网上浩如烟海的视频和图片只有画面,没有相机参数。为了利用这些数据,研究人员不得不先用COLMAP等软件去反推相机参数。
但这有个大坑:COLMAP非常慢,而且在很多场景下(比如纹理少的墙面、透明的玻璃)根本算不准。一旦算错了,喂给AI的数据就是“有毒”的。
如图[1]所示,当传统算法COLMAP在处理复杂的书架或建筑反光面时出现失误,依赖这些数据的模型(如GS-LRM和LVSM)生成的图像就会出现严重的重影或模糊(见图中红色虚线框区域)。而RayZer因为不依赖这些外部提供的“伪参考答案”,反而生成了清晰、准确的图像。

RayZer的核心理念非常接近人类的认知方式。当我们走进一个陌生的房间,没有人告诉我们眼睛的精确坐标,但我们通过移动和观察,大脑就能自动构建出房间的3D结构。RayZer正是做到了这一点:它具备了“涌现”出的3D感知能力。
RayZer的训练过程是一个绝妙的“左右互搏”游戏。研究人员设计了一个不需要任何外部3D标签的自监督框架。简单来说,它的学习过程是这样的:
如图[2]所示,这就是RayZer的训练逻辑:将图片分为“输入组”(Images A)和“目标组”(Images B)。模型看一眼A组图片,脑补出3D场景,然后尝试预测B组图片长什么样。通过不断缩小预测图与真实B组图之间的差异(即图中的虚线箭头所指的损失函数),RayZer就被迫学会了理解3D空间和相机位置,而这一切完全不需要人类提供3D标注。
传统的3D重建往往依赖复杂的物理公式和手工设计的模块。而RayZer走了一条更现代化的路子:全Transformer架构。就像ChatGPT用Transformer处理文字一样,RayZer用它来处理图片和3D空间。这种设计让模型具有极强的灵活性和扩展性,能够从海量数据中自动学习规律。
如图[3]所示,RayZer的工作流程非常清晰:
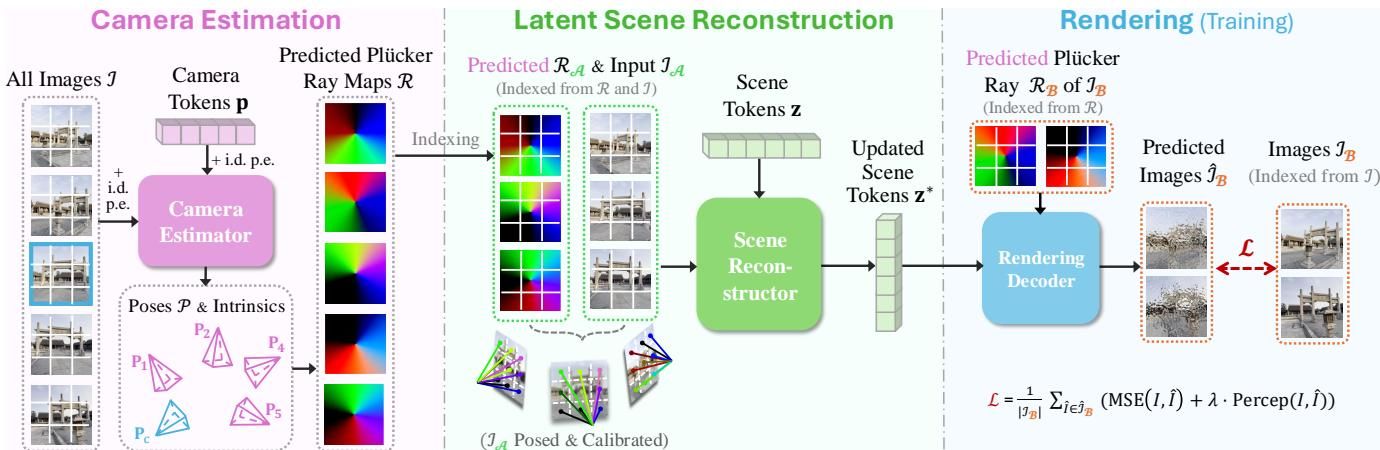
虽然RayZer尽量减少人为干预,但它保留了一个关键的物理常识——光线(Ray)。光沿直线传播,这是物理铁律。RayZer将预测出的相机参数转化为“Plücker光线图”(Plücker Ray Maps)。这相当于给模型提供了一个最基础的几何脚手架,告诉它像素是如何通过光线投射到空间中的。
这个设计巧妙地解决了“先有鸡还是先有蛋”的问题:相机位置不准会导致场景重建歪了,场景歪了又反过来误导相机位置判断。通过引入光线结构作为桥梁,两者可以相互纠正,共同进步。
既然是自学成才,RayZer的成绩单到底怎么样?研究人员在DL3DV(室内场景)、RealEstate10k(房地产视频)和Objaverse(3D物体)三个数据集上进行了严苛的测试。对比的对手是GS-LRM和LVSM,这两位可是拥有“上帝视角”的选手——它们在训练时使用了额外的相机位姿标注。
结果令人大跌眼镜:在没有任何3D标注的情况下,RayZer的表现不仅追平了,甚至在很多场景下超越了这些“顶配”选手。
特别是在DL3DV和RealEstate这两个真实场景数据集上,RayZer生成的图像质量(PSNR指标)击败了依赖COLMAP标注的LVSM模型。为什么会这样?
让我们看一组直观的对比。如图[4]所示,注意看第一行的游乐场设施和第二行的街道招牌,GS-LRM生成的图像有些模糊,LVSM虽然好一些但在细节处仍有瑕疵。而RayZer生成的图像(第三列)在清晰度和几何结构的准确性上都更胜一筹,甚至接近了真实照片(GT)。

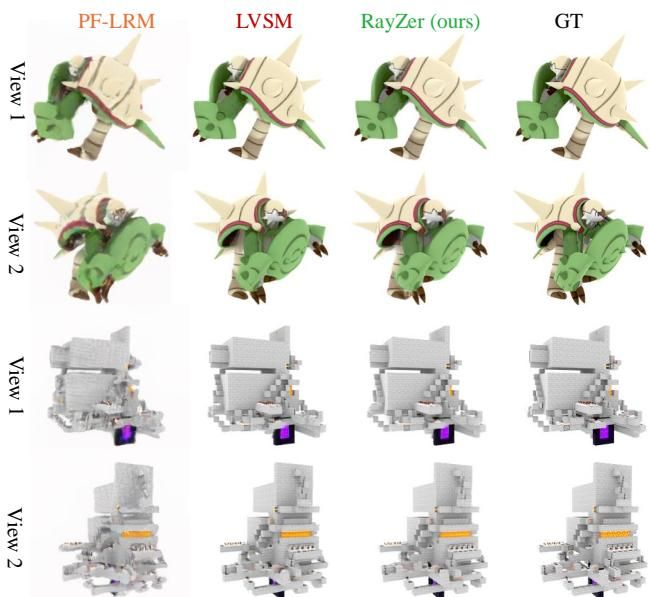
除了整体画质,RayZer在处理棘手物体时也表现出了惊人的稳定性。如图[5]所示,面对具有复杂几何结构的3D物体(如第一行的绿色怪物和第三行的白色建筑),传统的监督方法PF-LRM(第一列)往往会出现严重的扭曲或伪影。相比之下,RayZer(第三列)重建出的物体结构紧凑、细节丰富,几乎与右侧的真实模型(GT)一模一样。
更令人印象深刻的是对“透明”和“反光”的处理。再次回到图[4],请观察左下角的室内场景(RealEstate),其中包含了大面积的落地窗(红色虚线框区域)。依赖COLMAP的GS-LRM和LVSM模型在处理这种透明和反光材质时,往往会出现严重的伪影或模糊,因为COLMAP很难在玻璃表面找到准确的特征点。而RayZer凭借自监督学习到的光线理解能力,成功还原了清晰的窗框和透视关系,证明了其在处理挑战性材质时的鲁棒性。
RayZer 的出现,不仅仅是算法上的胜利,更是数据战略的一次突围。传统的 3D 模型训练像是在“精耕细作”,每一条数据都需要经过繁琐的预处理和清洗。而 RayZer 将这种模式转变为“粗放式”的规模化扩张——既然不需要任何标注,那么互联网上无穷无尽的视频资源,瞬间都变成了它的“教材”。
研究发现,RayZer 特别擅长从连续的视频帧中学习。相比于一堆杂乱无章的照片,视频本身蕴含了时间上的连续性和空间上的平滑变化。RayZer 利用这种特性,能够更准确地推断出相机是如何在空间中移动的。
如图[6]所示,我们可以看到 RayZer 在处理一段厨房场景视频时的表现。左侧三列是模型渲染出的新视角图像,画面连贯自然;最右侧则展示了模型“脑补”出的相机运动轨迹。请注意,这些整齐排列的相机位姿(彩色锥体)完全是模型通过自监督学习推理出来的,没有任何人工输入的坐标信息。这意味着,未来的 AI 只要“看”足够多的视频,就能像人类一样建立起对物理世界运动规律的深刻理解。

长期以来,3D 视觉领域一直被困在“数据饥渴”和“标注昂贵”的怪圈里。RayZer 用一种近乎暴力美学的方式证明了:与其费尽心思给 AI 喂这喂那,不如给它一套好的自我纠错机制,让它自己在海量数据中寻找答案。
这就好比大语言模型(LLM)通过阅读海量文本学会了写作,RayZer 让我们看到了视觉模型通过“观看”海量视频学会构建 3D 世界的可能。当摆脱了对 COLMAP 等传统工具的依赖,当每一段上传到 YouTube 或 TikTok 的视频都能直接成为训练养料,我们距离那个能理解、生成并交互真实 3D 世界的通用人工智能,或许又近了一大步。
这一次,AI 真的学会了自己看世界。
本文由超能文献“资讯AI智能体”基于4000万篇Pubmed文献自主选题与撰写,并经AI核查及编辑团队二次人工审校。内容仅供学术交流参考,不代表任何医学建议。
分享



