Persico Maria, Ceol Arnaud, Gavrila Caius, Hoffmann Robert, Florio Arnaldo, Cesareni Gianni
Department of Biology, University of Rome Tor Vergata, Via della Ricerca Scientifica, 00133 Rome, Italy.
BMC Bioinformatics. 2005 Dec 1;6 Suppl 4(Suppl 4):S21. doi: 10.1186/1471-2105-6-S4-S21.
The application of high throughput approaches to the identification of protein interactions has offered for the first time a glimpse of the global interactome of some model organisms. Until now, however, such genome-wide approaches have not been applied to the human proteome.
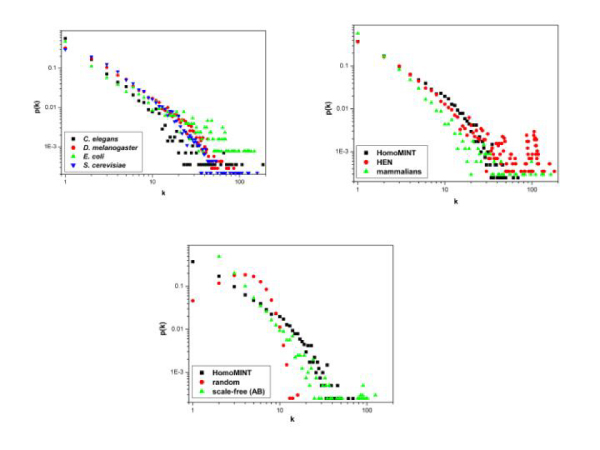
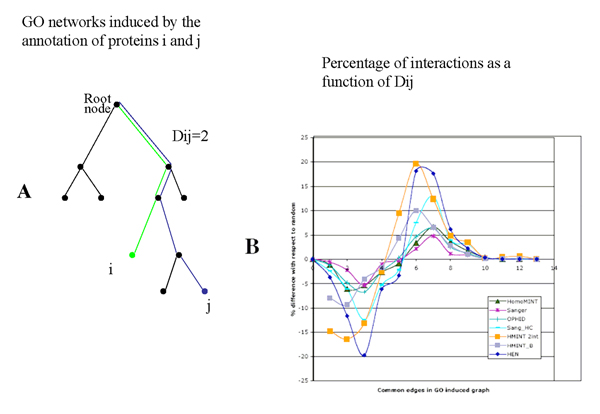
In order to fill this gap we have assembled an inferred human protein interaction network where interactions discovered in model organisms are mapped onto the corresponding human orthologs. In addition to a stringent assignment to orthology classes based on the InParanoid algorithm, we have implemented a string matching algorithm to filter out orthology assignments of proteins whose global domain organization is not conserved. Finally, we have assessed the accuracy of our own, and related, inferred networks by benchmarking them against i) an assembled experimental interactome, ii) a network derived by mining of the scientific literature and iii) by measuring the enrichment of interacting protein pairs sharing common Gene Ontology annotation.
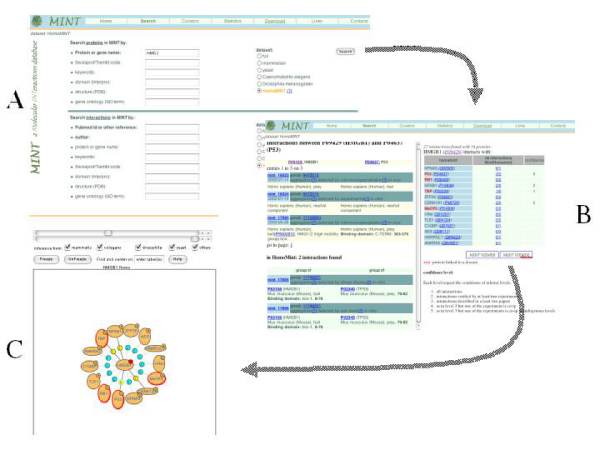
The resulting networks are named HomoMINT and HomoMINT_filtered, the latter being based on the orthology table filtered by the domain architecture matching algorithm. They contains 9749 and 5203 interactions respectively and can be analyzed and viewed in the context of the experimentally verified interactions between human proteins stored in the MINT database. HomoMINT is constantly updated to take into account the growing information in the MINT database.
高通量方法在蛋白质相互作用识别中的应用首次让我们得以一窥某些模式生物的全局相互作用组。然而,直到现在,这种全基因组方法尚未应用于人类蛋白质组。
为了填补这一空白,我们构建了一个推断的人类蛋白质相互作用网络,其中在模式生物中发现的相互作用被映射到相应的人类直系同源物上。除了基于InParanoid算法对直系同源类进行严格分配外,我们还实施了一种字符串匹配算法,以筛选出全局结构域组织不保守的蛋白质的直系同源分配。最后,我们通过将我们自己的以及相关的推断网络与以下内容进行基准测试来评估其准确性:i)一个组装的实验相互作用组,ii)通过挖掘科学文献得出的网络,以及iii)通过测量共享共同基因本体注释的相互作用蛋白对的富集情况。
所得网络分别命名为HomoMINT和HomoMINT_filtered,后者基于通过结构域架构匹配算法过滤的直系同源表。它们分别包含9749和5203个相互作用,并且可以在存储于MINT数据库中的人类蛋白质之间经实验验证的相互作用的背景下进行分析和查看。HomoMINT会不断更新,以考虑MINT数据库中不断增长的信息。