Chen Lusheng, Wang Wei, Ling Shaoping, Jia Caiyan, Wang Fei
Shanghai Key Laboratory of Intelligent Information Processing, Fudan University, Shanghai, PR China.
Nucleic Acids Res. 2006 Jul 1;34(Web Server issue):W158-63. doi: 10.1093/nar/gkl331.
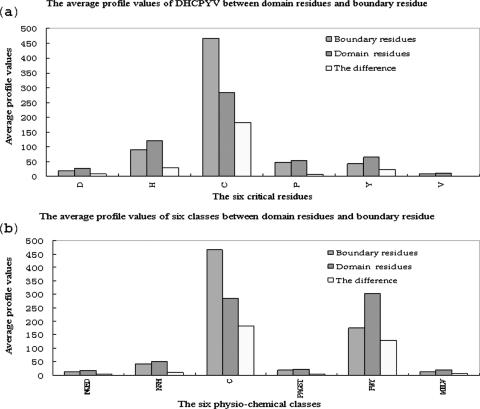
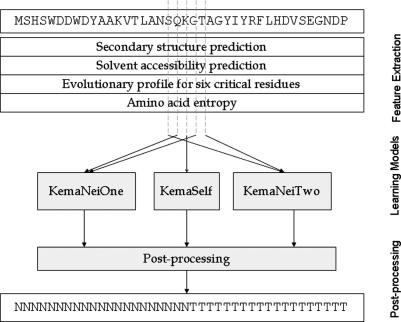
Predicting domains of proteins is an important and challenging problem in computational biology because of its significant role in understanding the complexity of proteomes. Although many template-based prediction servers have been developed, ab initio methods should be designed and further improved to be the complementarity of the template-based methods. In this paper, we present a novel domain prediction system KemaDom by ensembling three kernel machines with the local context information among neighboring amino acids. KemaDom, an alternative ab initio predictor, can achieve high performance in predicting the number of domains in proteins. It is freely accessible at http://www.iipl.fudan.edu.cn/lschen/kemadom.htm and http://www.iipl.fudan.edu.cn/~lschen/kemadom.htm.
预测蛋白质结构域是计算生物学中一个重要且具有挑战性的问题,因为它在理解蛋白质组的复杂性方面具有重要作用。尽管已经开发了许多基于模板的预测服务器,但仍应设计并进一步改进从头预测方法,以作为基于模板方法的补充。在本文中,我们通过整合三台内核机器以及相邻氨基酸之间的局部上下文信息,提出了一种新颖的结构域预测系统KemaDom。KemaDom作为一种从头预测器的替代方法,在预测蛋白质结构域数量方面能够实现高性能。可通过http://www.iipl.fudan.edu.cn/lschen/kemadom.htm和http://www.iipl.fudan.edu.cn/~lschen/kemadom.htm免费访问该系统。