Wang Yan, Zhang Hang, Zhong Haolin, Xue Zhidong
Institute of Medical Artificial Intelligence, Binzhou Medical College, Yantai, Shandong 264003, China.
School of Life Science and Technology, Huazhong University of Science and Technology, Wuhan, Hubei 430074, China.
Comput Struct Biotechnol J. 2021 Feb 2;19:1145-1153. doi: 10.1016/j.csbj.2021.01.041. eCollection 2021.
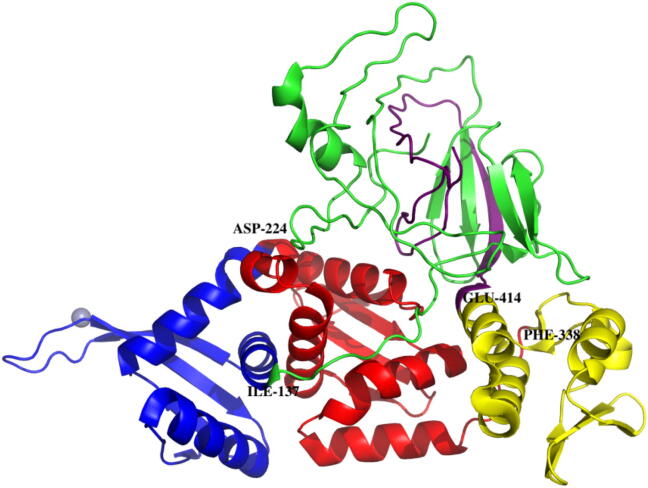
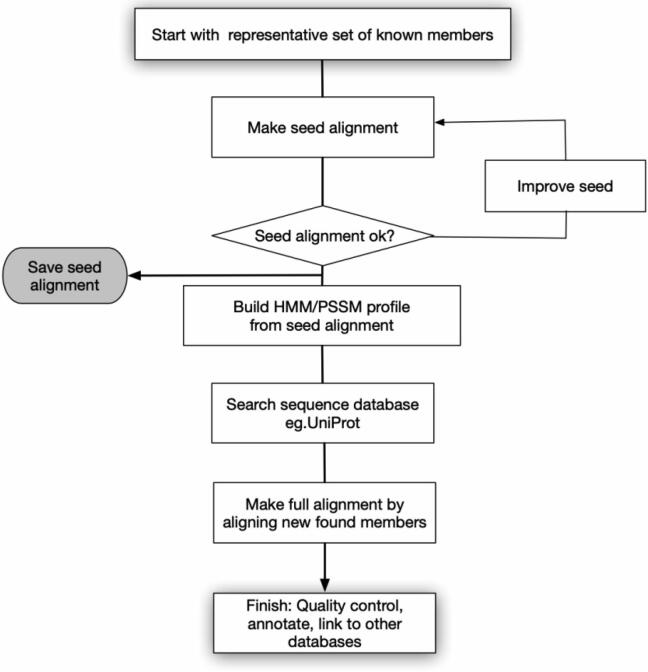
Protein domains are the basic units of proteins that can fold, function, and evolve independently. Knowledge of protein domains is critical for protein classification, understanding their biological functions, annotating their evolutionary mechanisms and protein design. Thus, over the past two decades, a number of protein domain identification approaches have been developed, and a variety of protein domain databases have also been constructed. This review divides protein domain prediction methods into two categories, namely sequence-based and structure-based. These methods are introduced in detail, and their advantages and limitations are compared. Furthermore, this review also provides a comprehensive overview of popular online protein domain sequence and structure databases. Finally, we discuss potential improvements of these prediction methods.
蛋白质结构域是蛋白质能够独立折叠、发挥功能并进化的基本单元。蛋白质结构域的知识对于蛋白质分类、理解其生物学功能、诠释其进化机制以及蛋白质设计至关重要。因此,在过去二十年中,已经开发了许多蛋白质结构域识别方法,并且还构建了各种蛋白质结构域数据库。本综述将蛋白质结构域预测方法分为两类,即基于序列的方法和基于结构的方法。详细介绍了这些方法,并比较了它们的优缺点。此外,本综述还全面概述了流行的在线蛋白质结构域序列和结构数据库。最后,我们讨论了这些预测方法的潜在改进。