Guigó Roderic, Flicek Paul, Abril Josep F, Reymond Alexandre, Lagarde Julien, Denoeud France, Antonarakis Stylianos, Ashburner Michael, Bajic Vladimir B, Birney Ewan, Castelo Robert, Eyras Eduardo, Ucla Catherine, Gingeras Thomas R, Harrow Jennifer, Hubbard Tim, Lewis Suzanna E, Reese Martin G
Centre de Regulació Genòmica, Institut Municipal d'Investigació Mèdica-Universitat Pompeu Fabra, E08003 Barcelona, Catalonia, Spain.
Genome Biol. 2006;7 Suppl 1(Suppl 1):S2.1-31. doi: 10.1186/gb-2006-7-s1-s2. Epub 2006 Aug 7.
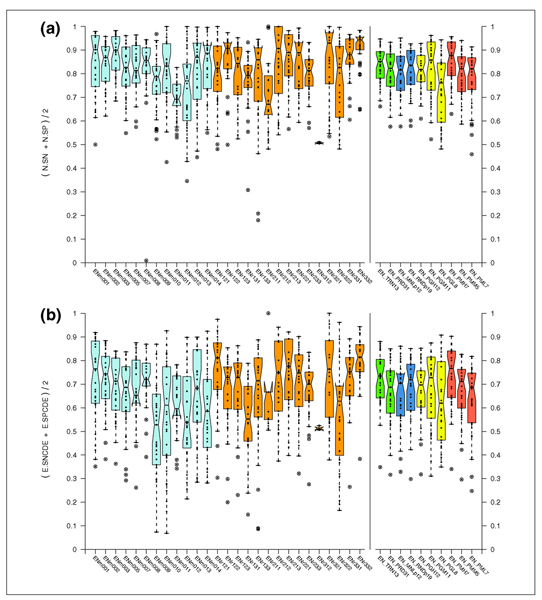
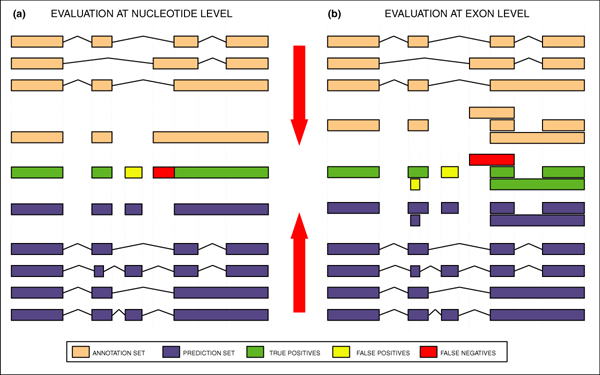
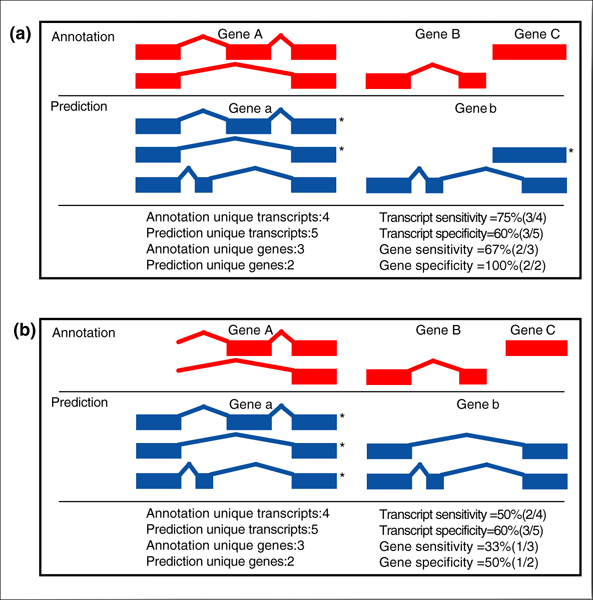
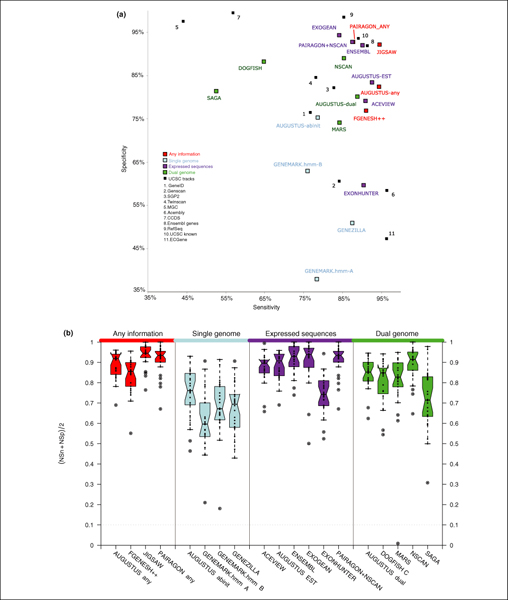
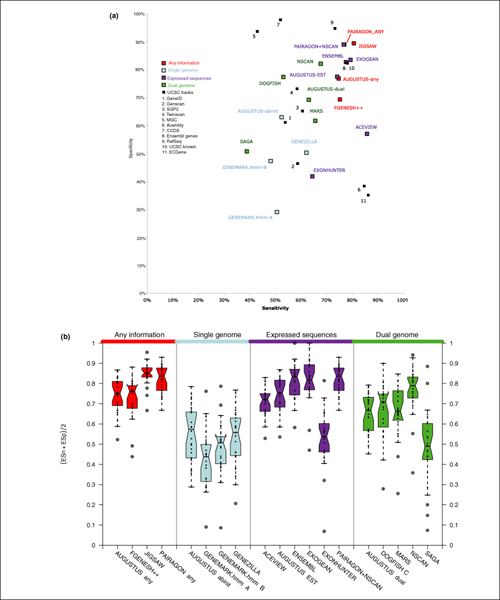
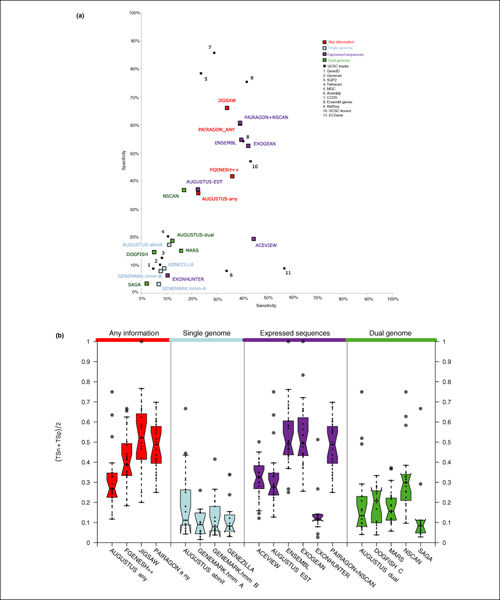
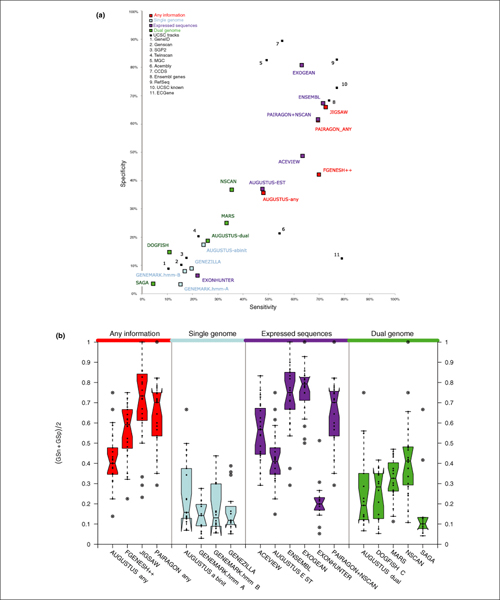
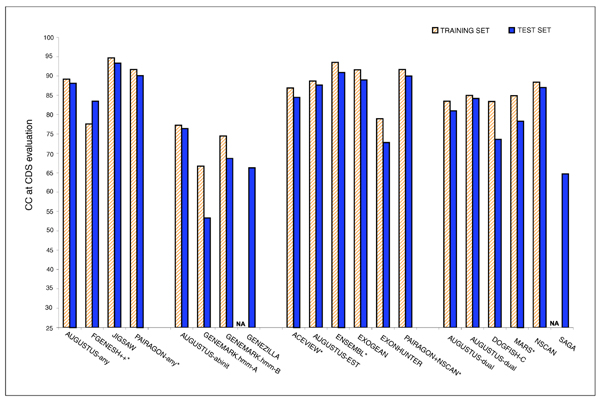
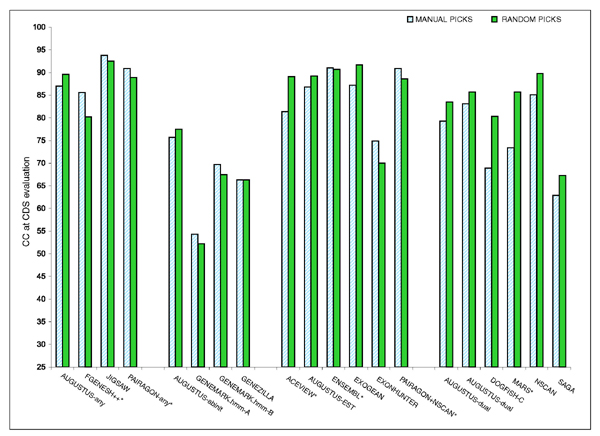
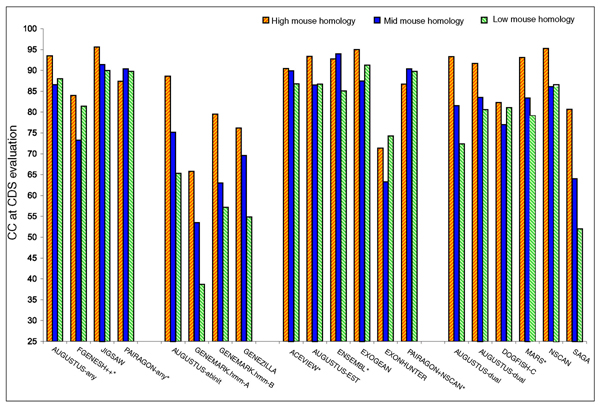
We present the results of EGASP, a community experiment to assess the state-of-the-art in genome annotation within the ENCODE regions, which span 1% of the human genome sequence. The experiment had two major goals: the assessment of the accuracy of computational methods to predict protein coding genes; and the overall assessment of the completeness of the current human genome annotations as represented in the ENCODE regions. For the computational prediction assessment, eighteen groups contributed gene predictions. We evaluated these submissions against each other based on a 'reference set' of annotations generated as part of the GENCODE project. These annotations were not available to the prediction groups prior to the submission deadline, so that their predictions were blind and an external advisory committee could perform a fair assessment.
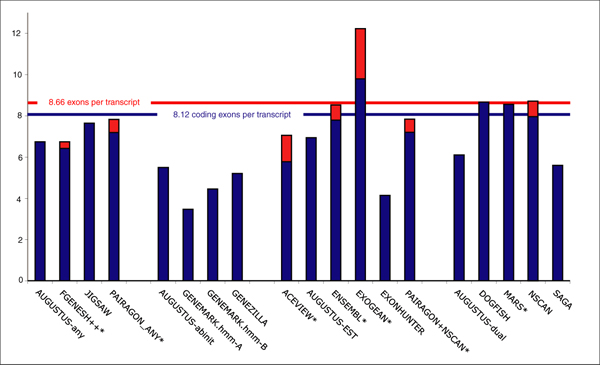
The best methods had at least one gene transcript correctly predicted for close to 70% of the annotated genes. Nevertheless, the multiple transcript accuracy, taking into account alternative splicing, reached only approximately 40% to 50% accuracy. At the coding nucleotide level, the best programs reached an accuracy of 90% in both sensitivity and specificity. Programs relying on mRNA and protein sequences were the most accurate in reproducing the manually curated annotations. Experimental validation shows that only a very small percentage (3.2%) of the selected 221 computationally predicted exons outside of the existing annotation could be verified.
This is the first such experiment in human DNA, and we have followed the standards established in a similar experiment, GASP1, in Drosophila melanogaster. We believe the results presented here contribute to the value of ongoing large-scale annotation projects and should guide further experimental methods when being scaled up to the entire human genome sequence.
我们展示了ENCODE基因组注释评估项目(EGASP)的结果,这是一项旨在评估人类基因组序列1%的ENCODE区域内基因组注释技术现状的社区实验。该实验有两个主要目标:评估预测蛋白质编码基因的计算方法的准确性;以及全面评估ENCODE区域所代表的当前人类基因组注释的完整性。对于计算预测评估,有18个团队提交了基因预测结果。我们根据作为GENCODE项目一部分生成的注释“参考集”对这些提交结果进行了相互评估。这些注释在提交截止日期之前对预测团队不可用,因此他们的预测是盲测,并且一个外部咨询委员会可以进行公平评估。
最佳方法对近70%的注释基因至少正确预测了一个基因转录本。然而,考虑到可变剪接,多个转录本的准确率仅达到约40%至50%。在编码核苷酸水平上,最佳程序在敏感性和特异性方面均达到了90%的准确率。依赖mRNA和蛋白质序列的程序在重现人工编辑注释方面最为准确。实验验证表明,在现有注释之外选择的221个计算预测外显子中,只有非常小的比例(3.2%)能够得到验证。
这是人类DNA领域的首次此类实验,我们遵循了在果蝇中进行的类似实验GASP1所确立的标准。我们相信这里展示的结果有助于正在进行的大规模注释项目的价值提升,并且在扩大到整个人类基因组序列时应指导进一步的实验方法。