Porro Ivan, Torterolo Livia, Corradi Luca, Fato Marco, Papadimitropoulos Adam, Scaglione Silvia, Schenone Andrea, Viti Federica
Computer Science, Systems, and Communication Department, University of Genova, Viale Causa 12, 16100 Genova, Italy.
BMC Bioinformatics. 2007 Mar 8;8 Suppl 1(Suppl 1):S7. doi: 10.1186/1471-2105-8-S1-S7.
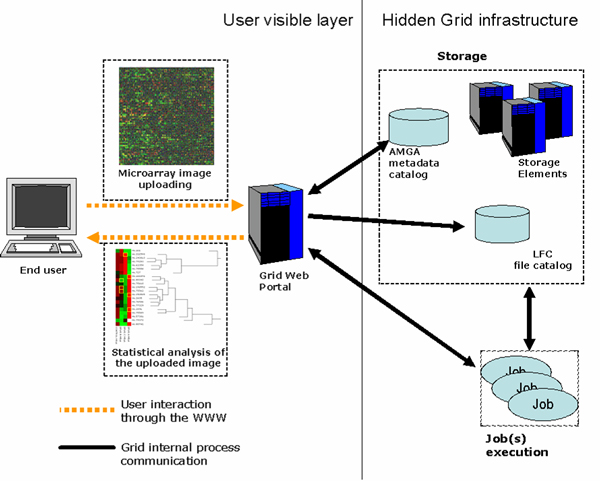
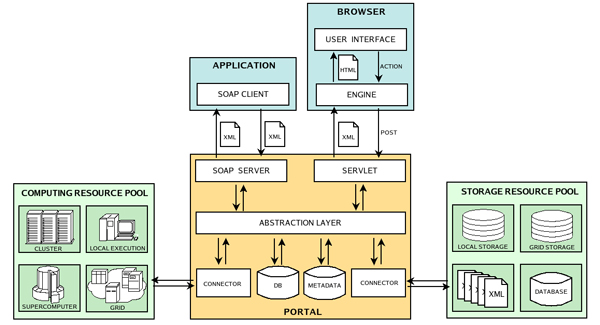
Several systems have been presented in the last years in order to manage the complexity of large microarray experiments. Although good results have been achieved, most systems tend to lack in one or more fields. A Grid based approach may provide a shared, standardized and reliable solution for storage and analysis of biological data, in order to maximize the results of experimental efforts. A Grid framework has been therefore adopted due to the necessity of remotely accessing large amounts of distributed data as well as to scale computational performances for terabyte datasets. Two different biological studies have been planned in order to highlight the benefits that can emerge from our Grid based platform. The described environment relies on storage services and computational services provided by the gLite Grid middleware. The Grid environment is also able to exploit the added value of metadata in order to let users better classify and search experiments. A state-of-art Grid portal has been implemented in order to hide the complexity of framework from end users and to make them able to easily access available services and data. The functional architecture of the portal is described. As a first test of the system performances, a gene expression analysis has been performed on a dataset of Affymetrix GeneChip Rat Expression Array RAE230A, from the ArrayExpress database. The sequence of analysis includes three steps: (i) group opening and image set uploading, (ii) normalization, and (iii) model based gene expression (based on PM/MM difference model). Two different Linux versions (sequential and parallel) of the dChip software have been developed to implement the analysis and have been tested on a cluster. From results, it emerges that the parallelization of the analysis process and the execution of parallel jobs on distributed computational resources actually improve the performances. Moreover, the Grid environment have been tested both against the possibility of uploading and accessing distributed datasets through the Grid middleware and against its ability in managing the execution of jobs on distributed computational resources. Results from the Grid test will be discussed in a further paper.
在过去几年中,已经出现了多个系统来管理大型微阵列实验的复杂性。尽管取得了不错的成果,但大多数系统在一个或多个方面仍存在不足。基于网格的方法可能为生物数据的存储和分析提供一个共享、标准化且可靠的解决方案,以便最大限度地提高实验工作的成果。因此,由于需要远程访问大量分布式数据以及扩展对万亿字节数据集的计算性能,采用了一种网格框架。为了突出我们基于网格的平台可能带来的好处,已经规划了两项不同的生物学研究。所描述的环境依赖于gLite网格中间件提供的存储服务和计算服务。网格环境还能够利用元数据的附加值,以便让用户更好地对实验进行分类和搜索。已经实现了一个先进的网格门户,以向最终用户隐藏框架的复杂性,并使他们能够轻松访问可用的服务和数据。描述了该门户的功能架构。作为对系统性能的首次测试,对来自ArrayExpress数据库的Affymetrix GeneChip Rat Expression Array RAE230A数据集进行了基因表达分析。分析序列包括三个步骤:(i) 分组打开和图像集上传,(ii) 归一化,以及 (iii) 基于模型的基因表达(基于PM/MM差异模型)。已经开发了dChip软件的两个不同Linux版本(顺序版和并行版)来实现分析,并在一个集群上进行了测试。从结果可以看出,分析过程的并行化以及在分布式计算资源上执行并行作业实际上提高了性能。此外,还针对通过网格中间件上传和访问分布式数据集的可能性以及其在管理分布式计算资源上的作业执行能力对网格环境进行了测试。网格测试的结果将在另一篇论文中讨论。