Joshi Trupti, Xu Dong
Digital Biology Laboratory, Department of Computer Science and Christopher S, Bond Life Sciences Center, University of Missouri, Columbia, Missouri 65211, USA.
BMC Genomics. 2007 Jul 9;8:222. doi: 10.1186/1471-2164-8-222.
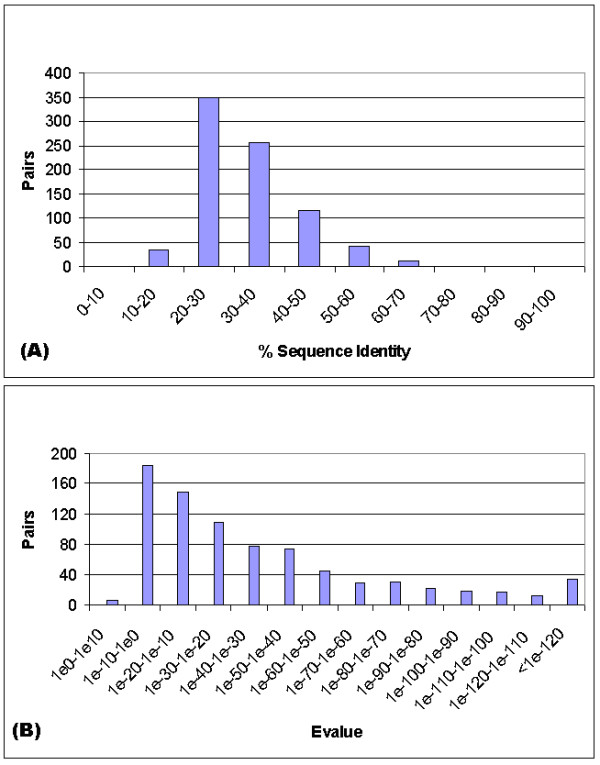
Comparative sequence analysis is considered as the first step towards annotating new proteins in genome annotation. However, sequence comparison may lead to creation and propagation of function assignment errors. Thus, it is important to perform a thorough analysis for the quality of sequence-based function assignment using large-scale data in a systematic way.
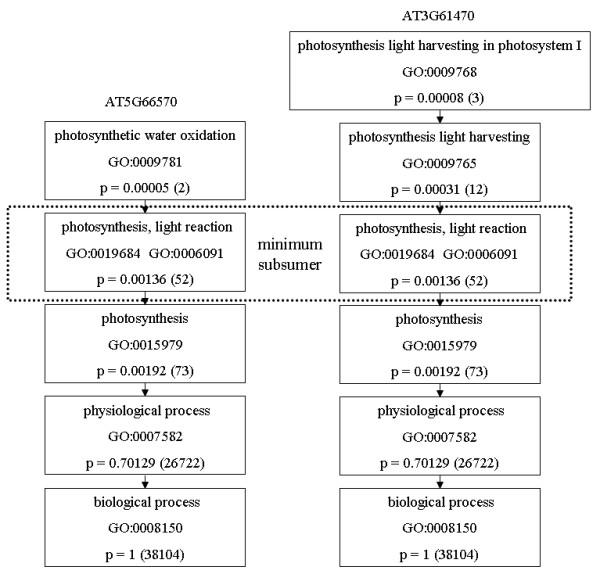
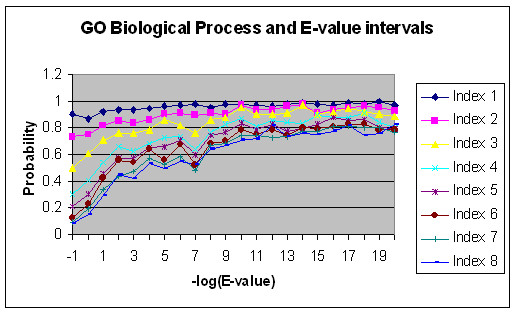
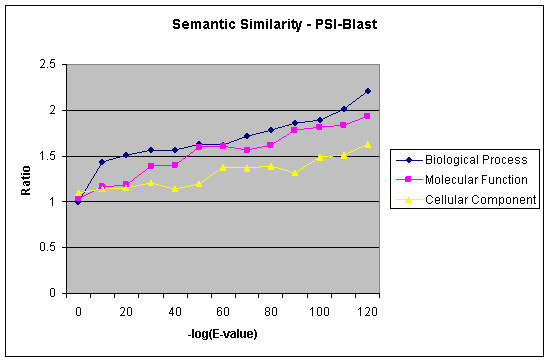
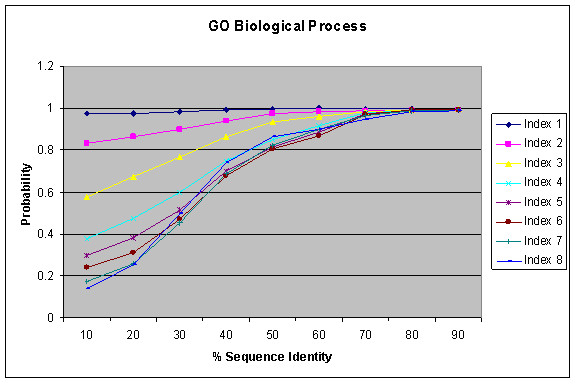
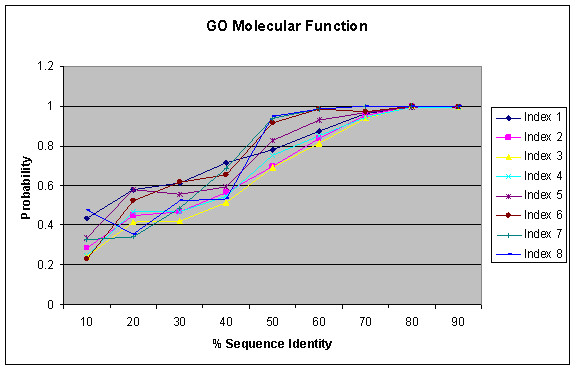
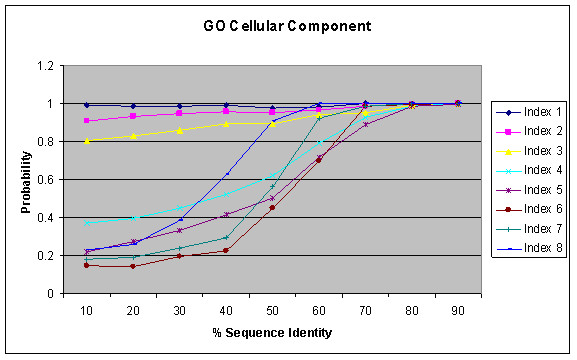
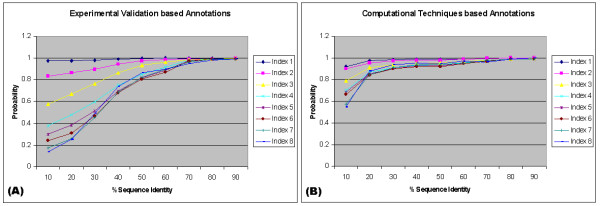
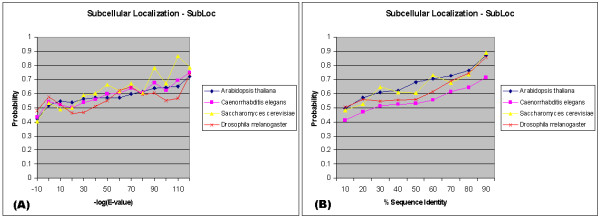
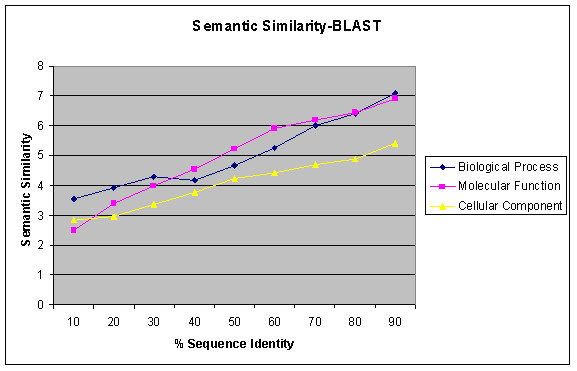
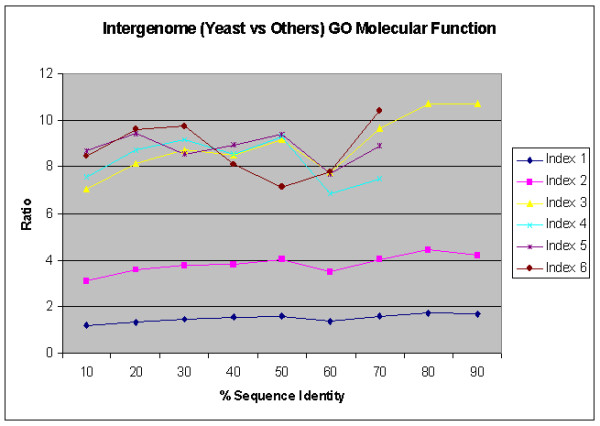
We present an analysis of the relationship between sequence similarity and function similarity for the proteins in four model organisms, i.e., Arabidopsis thaliana, Saccharomyces cerevisiae, Caenorrhabditis elegans, and Drosophila melanogaster. Using a measure of functional similarity based on the three categories of Gene Ontology (GO) classifications (biological process, molecular function, and cellular component), we quantified the correlation between functional similarity and sequence similarity measured by sequence identity or statistical significance of the alignment and compared such a correlation against randomly chosen protein pairs.
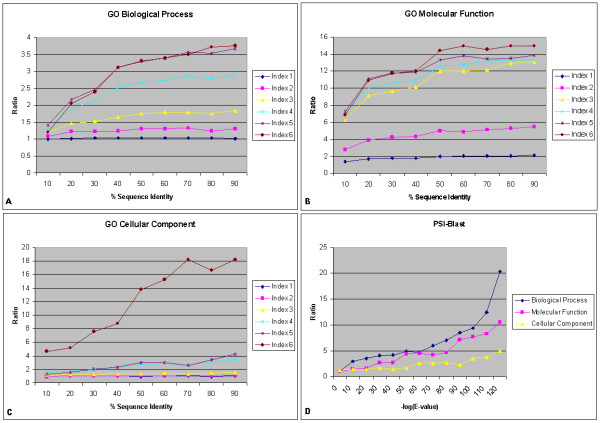
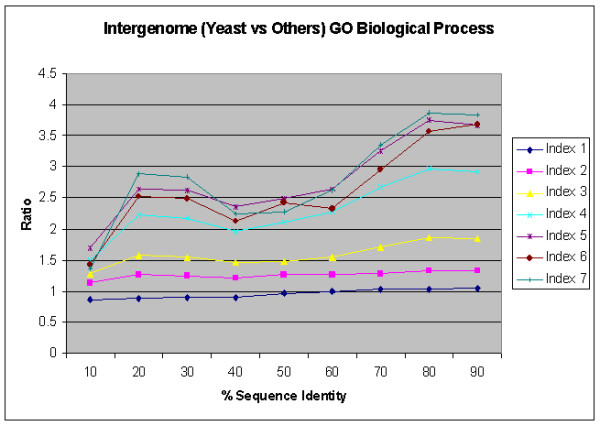
Various sequence-function relationships were identified from BLAST versus PSI-BLAST, sequence identity versus Expectation Value, GO indices versus semantic similarity approaches, and within genome versus between genome comparisons, for the three GO categories. Our study provides a benchmark to estimate the confidence in assignment of functions purely based on sequence similarity.
在基因组注释中,比较序列分析被视为注释新蛋白质的第一步。然而,序列比较可能会导致功能分配错误的产生和传播。因此,使用大规模数据以系统的方式对基于序列的功能分配质量进行全面分析非常重要。
我们对四种模式生物(即拟南芥、酿酒酵母、秀丽隐杆线虫和黑腹果蝇)中的蛋白质序列相似性与功能相似性之间的关系进行了分析。使用基于基因本体论(GO)分类的三个类别(生物过程、分子功能和细胞成分)的功能相似性度量,我们量化了通过序列同一性或比对的统计显著性测量的功能相似性与序列相似性之间的相关性,并将这种相关性与随机选择的蛋白质对进行了比较。
对于三个GO类别,从BLAST与PSI-BLAST、序列同一性与期望值、GO索引与语义相似性方法以及基因组内与基因组间比较中识别出了各种序列-功能关系。我们的研究提供了一个基准,用于估计仅基于序列相似性进行功能分配的置信度。