Gehrke Allison, Sun Shaojun, Kurgan Lukasz, Ahn Natalie, Resing Katheryn, Kafadar Karen, Cios Krzysztof
Department of Computer Science and Engineering, University of Colorado at Denver, USA.
BMC Bioinformatics. 2008 Dec 3;9:515. doi: 10.1186/1471-2105-9-515.
Accurate peptide identification is important to high-throughput proteomics analyses that use mass spectrometry. Search programs compare fragmentation spectra (MS/MS) of peptides from complex digests with theoretically derived spectra from a database of protein sequences. Improved discrimination is achieved with theoretical spectra that are based on simulating gas phase chemistry of the peptides, but the limited understanding of those processes affects the accuracy of predictions from theoretical spectra.
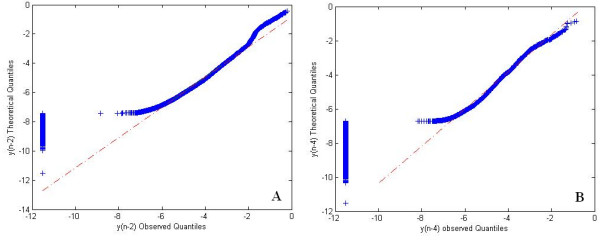
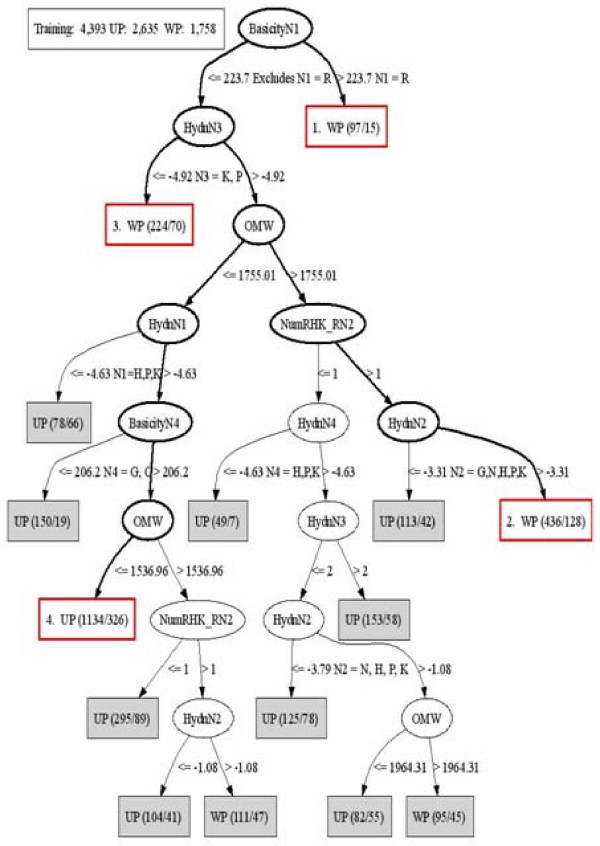
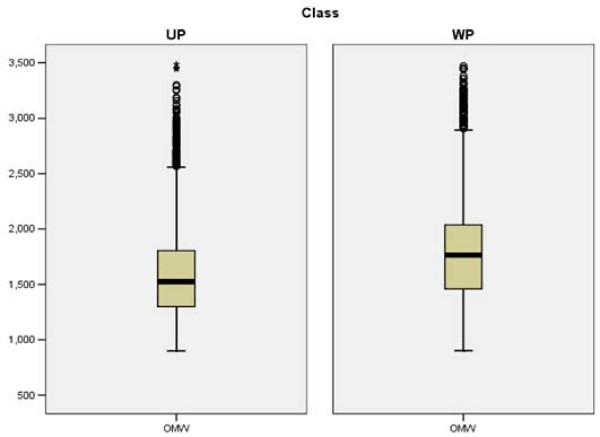
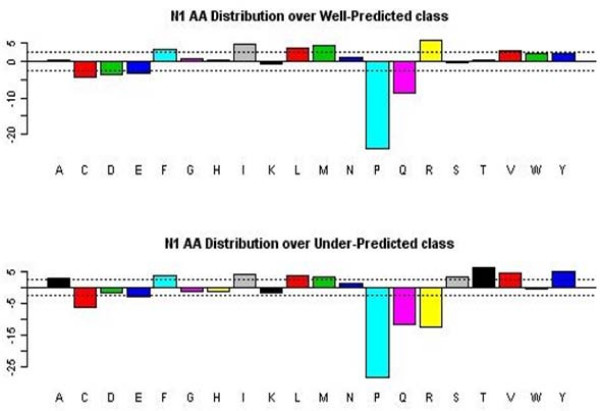
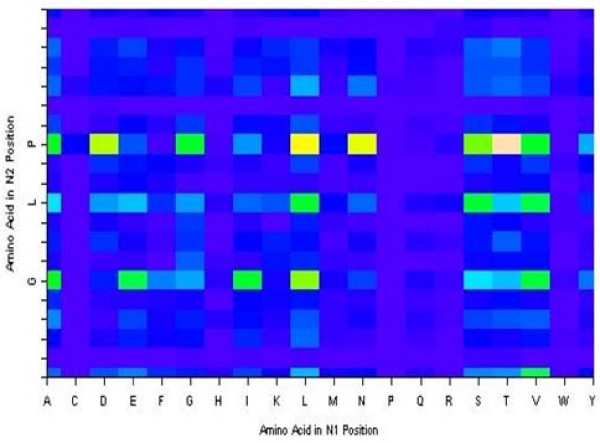
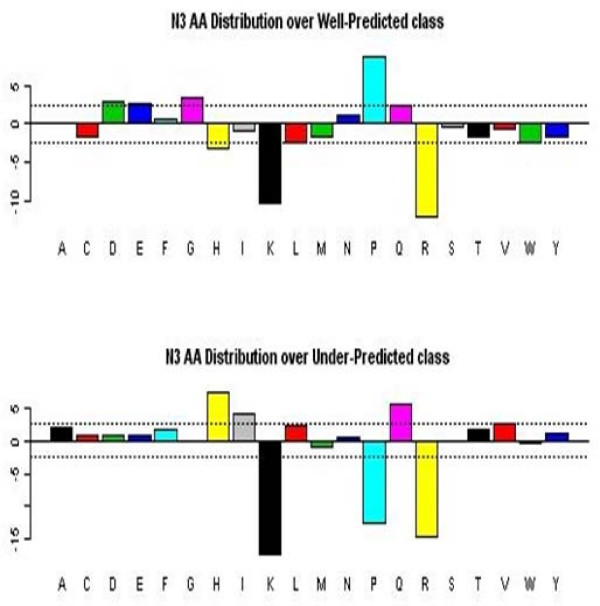
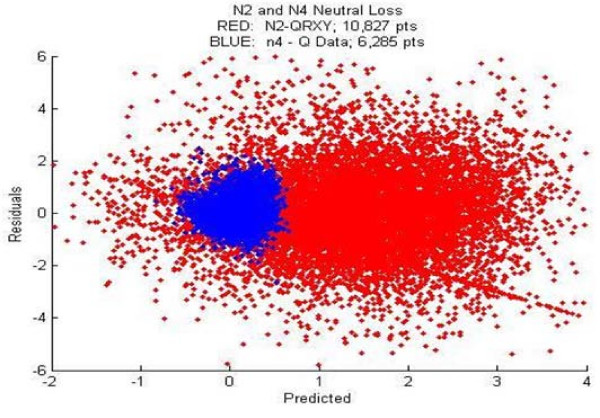
We employed a robust data mining strategy using new feature annotation functions of MAE software, which revealed under-prediction of the frequency of occurrence in fragmentation of the second peptide bond. We applied methods of exploratory data analysis to pre-process the information in the MS/MS spectra, including data normalization and attribute selection, to reduce the attributes to a smaller, less correlated set for machine learning studies. We then compared our rule building machine learning program, DataSqueezer, with commonly used association rules and decision tree algorithms. All used machine learning algorithms produced similar results that were consistent with expected properties for a second gas phase mechanism at the second peptide bond.
The results provide compelling evidence that we have identified underlying chemical properties in the data that suggest the existence of an additional gas phase mechanism for the second peptide bond. Thus, the methods described in this study provide a valuable approach for analyses of this kind in the future.
准确的肽段鉴定对于使用质谱的高通量蛋白质组学分析至关重要。搜索程序将复杂消化产物中肽段的碎片谱(MS/MS)与蛋白质序列数据库中理论推导的谱进行比较。基于模拟肽段气相化学的理论谱能实现更好的区分,但对这些过程的有限理解影响了理论谱预测的准确性。
我们采用了一种强大的数据挖掘策略,利用MAE软件的新特征注释功能,该功能揭示了第二个肽键断裂中出现频率的预测不足。我们应用探索性数据分析方法对MS/MS谱中的信息进行预处理,包括数据归一化和属性选择,以将属性减少到更小、相关性更低的集合用于机器学习研究。然后,我们将我们的规则构建机器学习程序DataSqueezer与常用的关联规则和决策树算法进行比较。所有使用的机器学习算法都产生了相似的结果,这些结果与第二个肽键处第二种气相机制的预期特性一致。
结果提供了令人信服的证据,表明我们已经在数据中识别出潜在的化学性质,这表明第二个肽键存在额外的气相机制。因此,本研究中描述的方法为未来此类分析提供了一种有价值的方法。