University College London - Structural and Molecular Biology, London, UK.
Nucleic Acids Res. 2010 Jan;38(3):720-37. doi: 10.1093/nar/gkp1049. Epub 2009 Nov 18.
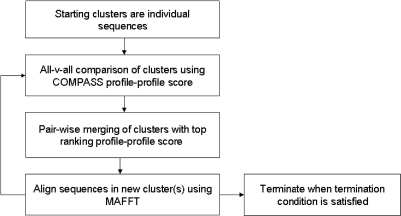
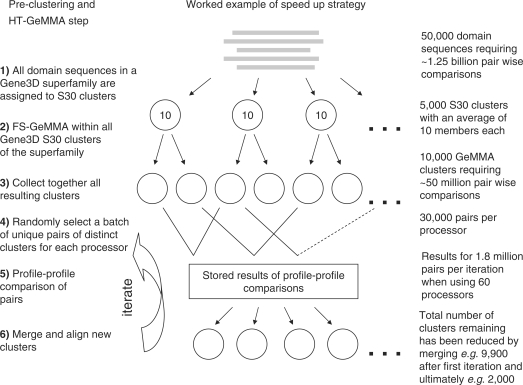
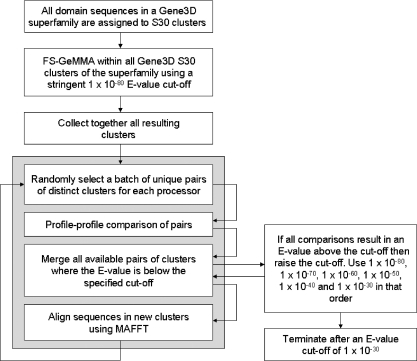
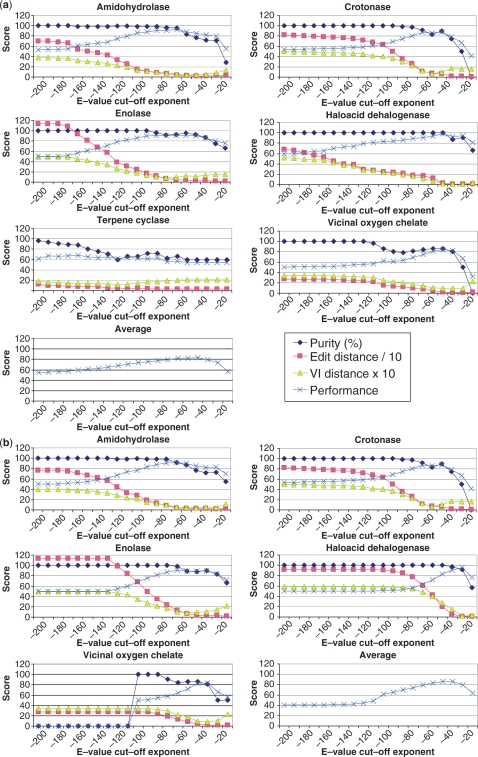
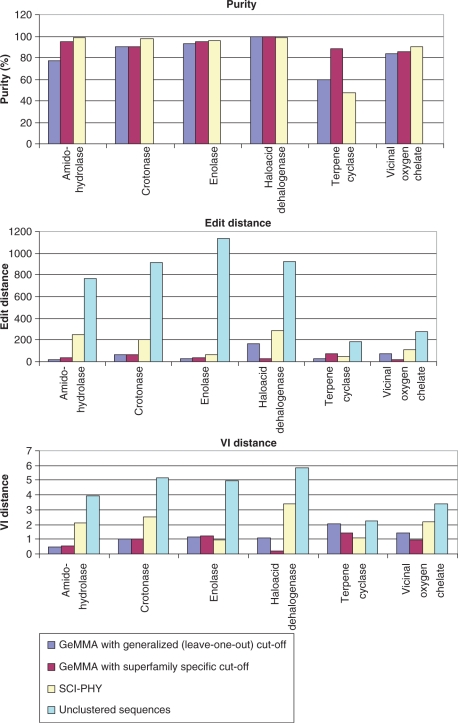
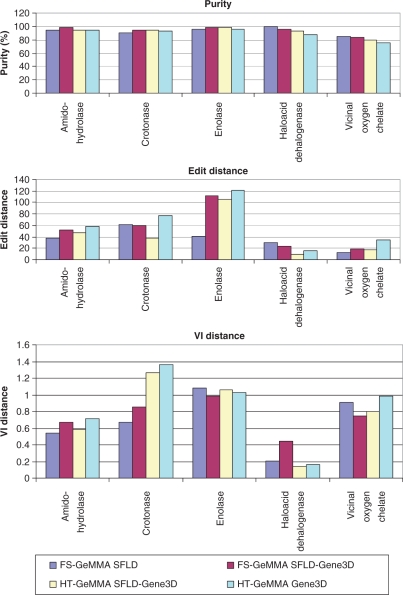
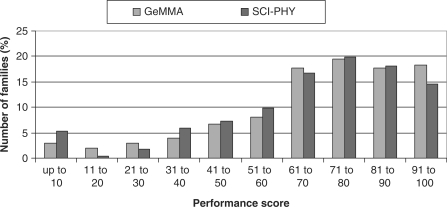
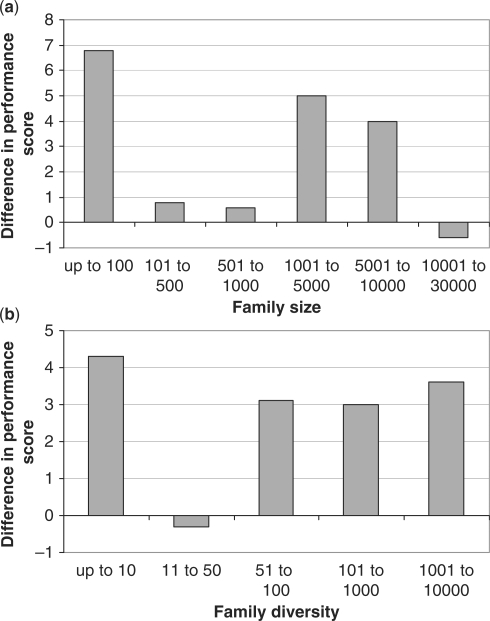
GeMMA (Genome Modelling and Model Annotation) is a new approach to automatic functional subfamily classification within families and superfamilies of protein sequences. A major advantage of GeMMA is its ability to subclassify very large and diverse superfamilies with tens of thousands of members, without the need for an initial multiple sequence alignment. Its performance is shown to be comparable to the established high-performance method SCI-PHY. GeMMA follows an agglomerative clustering protocol that uses existing software for sensitive and accurate multiple sequence alignment and profile-profile comparison. The produced subfamilies are shown to be equivalent in quality whether whole protein sequences are used or just the sequences of component predicted structural domains. A faster, heuristic version of GeMMA that also uses distributed computing is shown to maintain the performance levels of the original implementation. The use of GeMMA to increase the functional annotation coverage of functionally diverse Pfam families is demonstrated. It is further shown how GeMMA clusters can help to predict the impact of experimentally determining a protein domain structure on comparative protein modelling coverage, in the context of structural genomics.
GeMMA(基因组建模和模型注释)是一种在蛋白质序列家族和超家族中自动进行功能亚家族分类的新方法。GeMMA 的一个主要优势是,它能够对具有成千上万成员的非常大且多样化的超家族进行子类划分,而无需进行初始的多重序列比对。其性能被证明可与既定的高性能方法 SCI-PHY 相媲美。GeMMA 采用聚合聚类协议,该协议使用现有软件进行敏感和准确的多重序列比对和轮廓-轮廓比较。无论使用完整的蛋白质序列还是仅使用组成预测结构域的序列,所产生的亚家族在质量上都是等效的。一种更快、基于启发式的 GeMMA 版本也使用分布式计算,其性能水平与原始实现保持一致。展示了如何使用 GeMMA 来提高功能多样的 Pfam 家族的功能注释覆盖率。进一步展示了 GeMMA 聚类如何帮助预测在结构基因组学中,实验确定蛋白质结构域结构对比较蛋白质建模覆盖范围的影响。