McGovern Institute for Brain Research, Massachusetts Institute of Technology, Cambridge, Massachussetts, USA.
PLoS Comput Biol. 2009 Nov;5(11):e1000579. doi: 10.1371/journal.pcbi.1000579. Epub 2009 Nov 26.
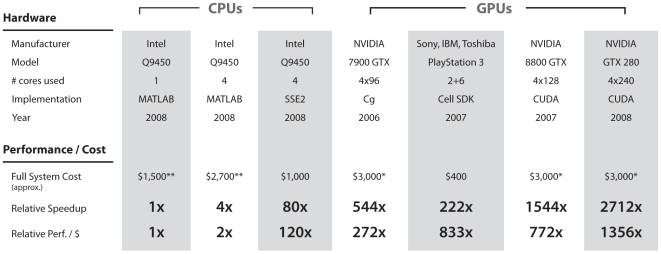
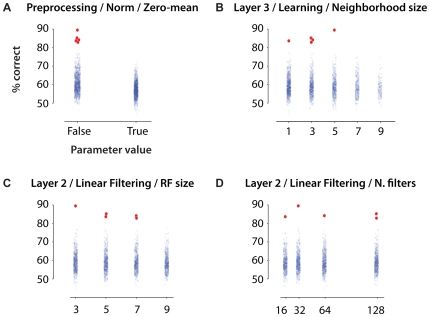
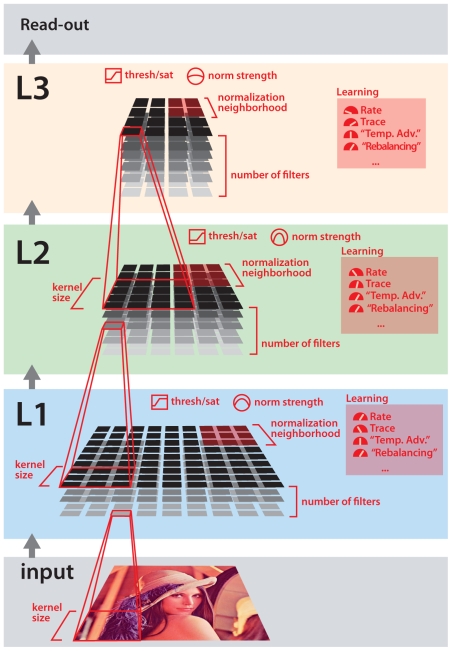
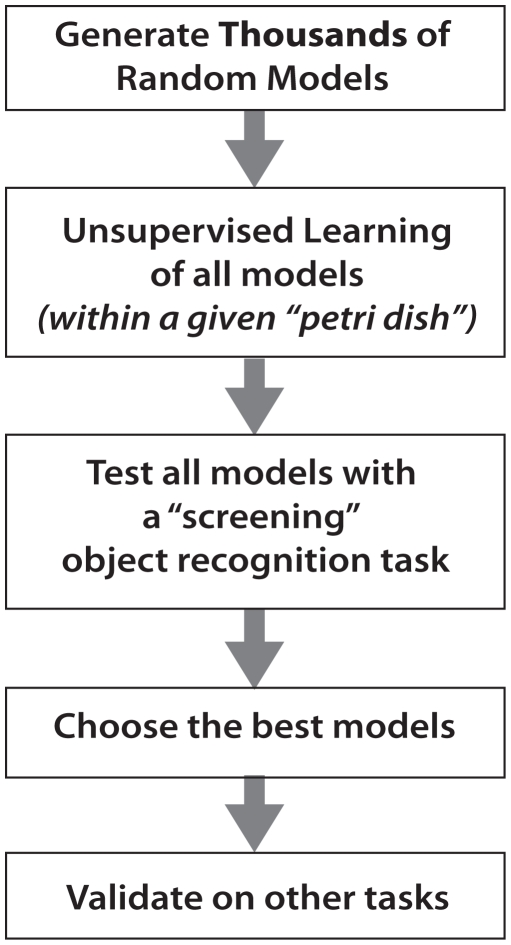
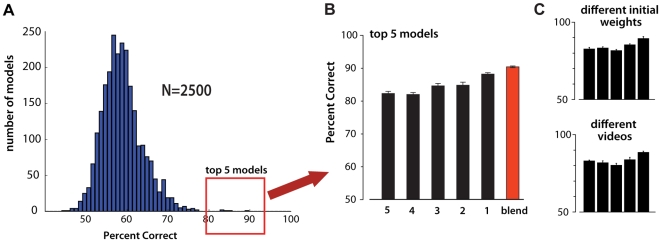
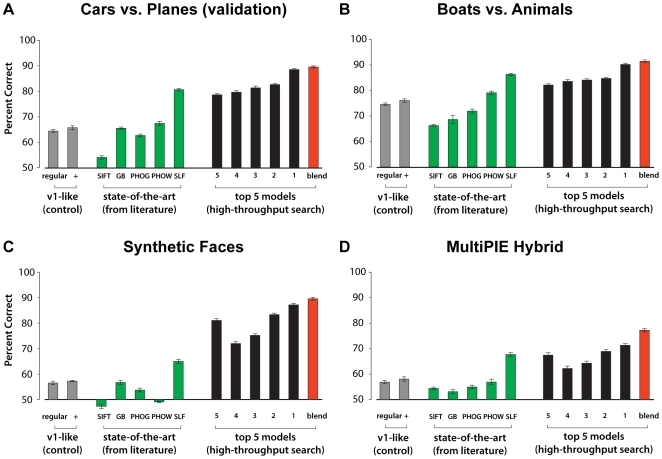
While many models of biological object recognition share a common set of "broad-stroke" properties, the performance of any one model depends strongly on the choice of parameters in a particular instantiation of that model--e.g., the number of units per layer, the size of pooling kernels, exponents in normalization operations, etc. Since the number of such parameters (explicit or implicit) is typically large and the computational cost of evaluating one particular parameter set is high, the space of possible model instantiations goes largely unexplored. Thus, when a model fails to approach the abilities of biological visual systems, we are left uncertain whether this failure is because we are missing a fundamental idea or because the correct "parts" have not been tuned correctly, assembled at sufficient scale, or provided with enough training. Here, we present a high-throughput approach to the exploration of such parameter sets, leveraging recent advances in stream processing hardware (high-end NVIDIA graphic cards and the PlayStation 3's IBM Cell Processor). In analogy to high-throughput screening approaches in molecular biology and genetics, we explored thousands of potential network architectures and parameter instantiations, screening those that show promising object recognition performance for further analysis. We show that this approach can yield significant, reproducible gains in performance across an array of basic object recognition tasks, consistently outperforming a variety of state-of-the-art purpose-built vision systems from the literature. As the scale of available computational power continues to expand, we argue that this approach has the potential to greatly accelerate progress in both artificial vision and our understanding of the computational underpinning of biological vision.
虽然许多生物目标识别模型都具有一组共同的“粗线条”特性,但任何一个模型的性能都强烈依赖于该模型特定实例中参数的选择——例如,每层的单元数量、池化核的大小、归一化操作中的指数等。由于此类参数(显式或隐式)的数量通常很大,并且评估一个特定参数集的计算成本很高,因此可能的模型实例空间在很大程度上未被探索。因此,当模型未能达到生物视觉系统的能力时,我们不确定这种失败是因为我们缺少一个基本思想,还是因为正确的“部分”没有被正确调整、以足够的规模组装,或者没有得到足够的训练。在这里,我们提出了一种利用流处理硬件(高端 NVIDIA 显卡和 PlayStation 3 的 IBM Cell 处理器)探索此类参数集的高通量方法。类似于分子生物学和遗传学中的高通量筛选方法,我们探索了数千种潜在的网络架构和参数实例,筛选出那些在对象识别性能方面表现出前景的架构和参数实例进行进一步分析。我们表明,这种方法可以在一系列基本对象识别任务中产生显著的、可重复的性能提升,始终优于各种来自文献的最先进的专用视觉系统。随着可用计算能力的规模继续扩大,我们认为这种方法有可能大大加快人工视觉和我们对生物视觉计算基础的理解的进展。