Shamir Lior
Laboratory of Genetics, National Institute on Aging, National Institutes of Health, 333 Cassell Dr., Baltimore, MD 21224, Tel: 410-558-8682 , Email:
Int J Comput Vis. 2008;79(3):225-230. doi: 10.1007/s11263-008-0143-7.
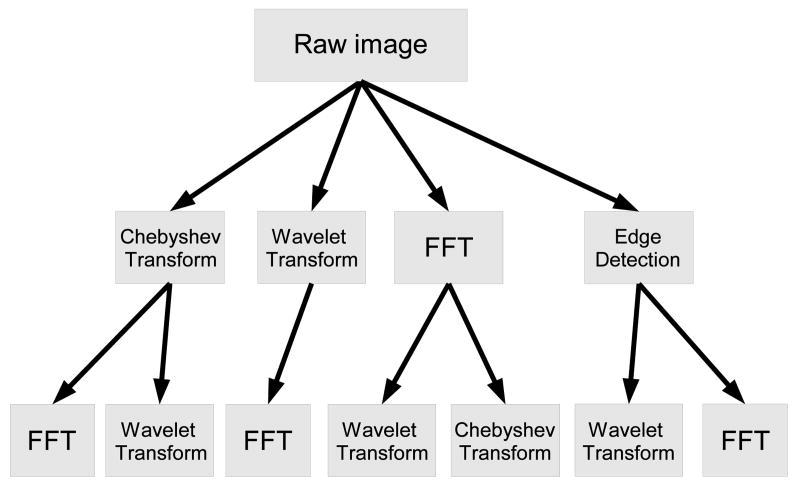
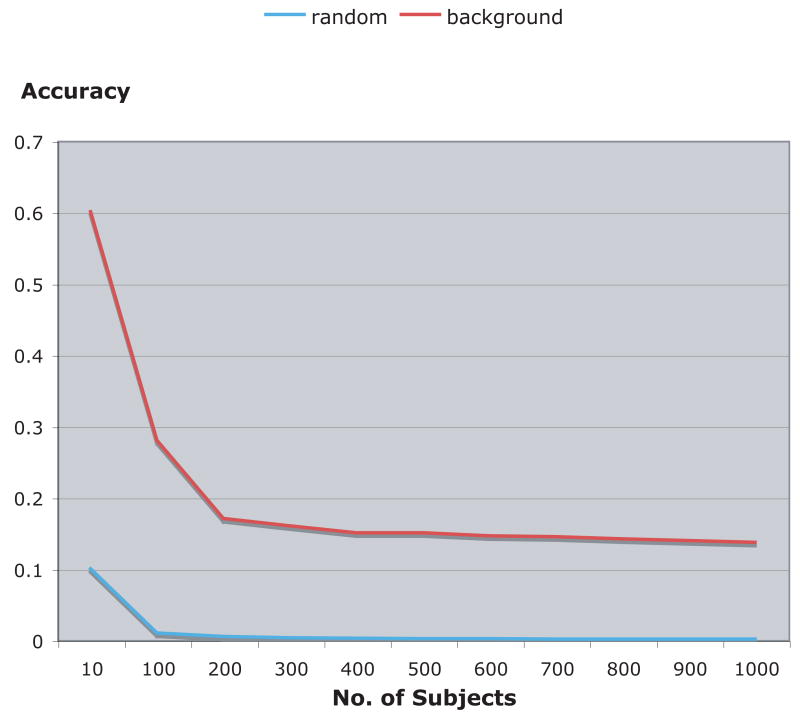
Face datasets are considered a primary tool for evaluating the efficacy of face recognition methods. Here we show that in many of the commonly used face datasets, face images can be recognized accurately at a rate significantly higher than random even when no face, hair or clothes features appear in the image. The experiments were done by cutting a small background area from each face image, so that each face dataset provided a new image dataset which included only seemingly blank images. Then, an image classification method was used in order to check the classification accuracy. Experimental results show that the classification accuracy ranged between 13.5% (color FERET) to 99% (YaleB). These results indicate that the performance of face recognition methods measured using face image datasets may be biased. Compilable source code used for this experiment is freely available for download via the internet.
人脸数据集被视为评估人脸识别方法有效性的主要工具。我们在此表明,在许多常用的人脸数据集中,即使图像中没有人脸、头发或衣服特征,人脸图像也能以显著高于随机概率的准确率被识别。实验通过从每张人脸图像中裁剪出一小块背景区域来进行,这样每个人脸数据集都提供了一个仅包含看似空白图像的新图像数据集。然后,使用一种图像分类方法来检查分类准确率。实验结果表明,分类准确率在13.5%(彩色FERET数据集)到99%(耶鲁B数据集)之间。这些结果表明,用人脸图像数据集衡量的人脸识别方法的性能可能存在偏差。用于本实验的可编译源代码可通过互联网免费下载。