Department of Bioengineering, University of Illinois at Chicago, Chicago, IL 60612, USA.
Nucleic Acids Res. 2010 Jun;38(10):3149-58. doi: 10.1093/nar/gkq061. Epub 2010 Feb 15.
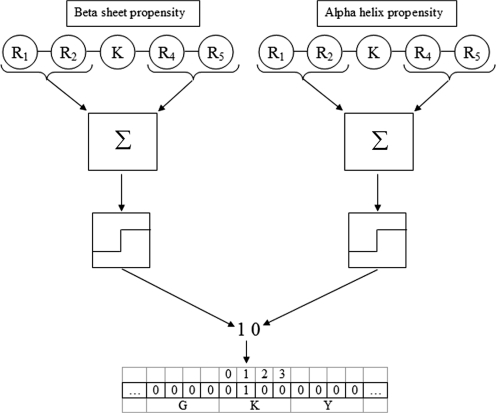
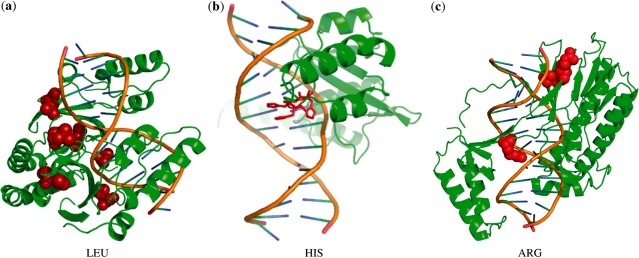
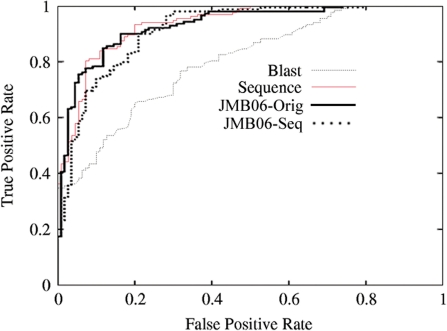
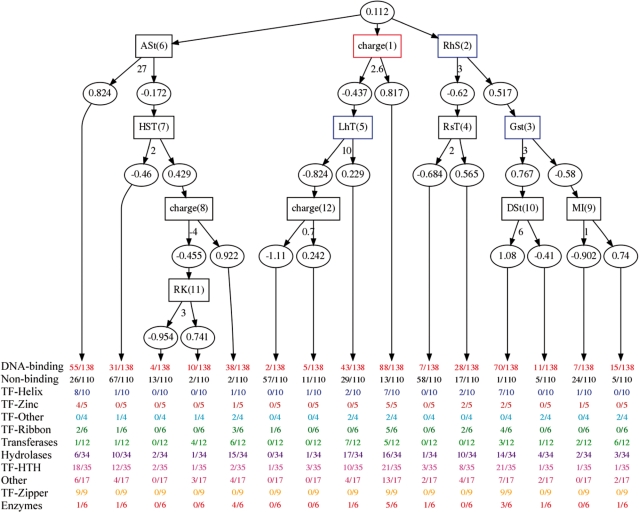
DNA-binding proteins perform vital functions related to transcription, repair and replication. We have developed a new sequence-based machine learning protocol to identify DNA-binding proteins. We compare our method with an extensive benchmark of previously published structure-based machine learning methods as well as a standard sequence alignment technique, BLAST. Furthermore, we elucidate important feature interactions found in a learned model and analyze how specific rules capture general mechanisms that extend across DNA-binding motifs. This analysis is carried out using the malibu machine learning workbench available at http://proteomics.bioengr.uic.edu/malibu and the corresponding data sets and features are available at http://proteomics.bioengr.uic.edu/dna.
DNA 结合蛋白执行与转录、修复和复制相关的重要功能。我们开发了一种新的基于序列的机器学习协议来识别 DNA 结合蛋白。我们将我们的方法与广泛的先前发表的基于结构的机器学习方法的基准以及标准序列比对技术 BLAST 进行了比较。此外,我们阐明了在学习模型中发现的重要特征相互作用,并分析了特定规则如何捕获跨 DNA 结合基序延伸的一般机制。这项分析是使用可在 http://proteomics.bioengr.uic.edu/malibu 上获得的 malibu 机器学习工作台以及可在 http://proteomics.bioengr.uic.edu/dna 上获得的相应数据集和特征来进行的。