Program in Computational Biology and Bioinformatics, Yale University, New Haven, Connecticut, United States of America.
PLoS Comput Biol. 2010 May 27;6(5):e1000755. doi: 10.1371/journal.pcbi.1000755.
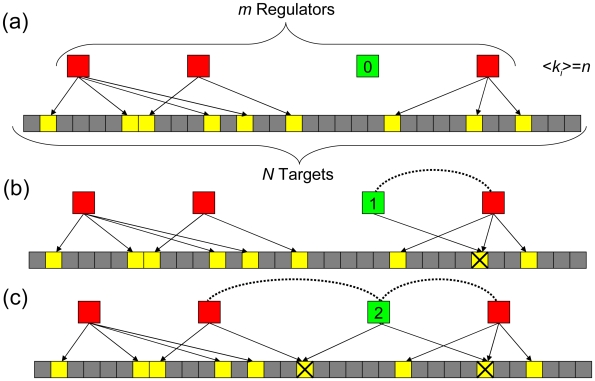
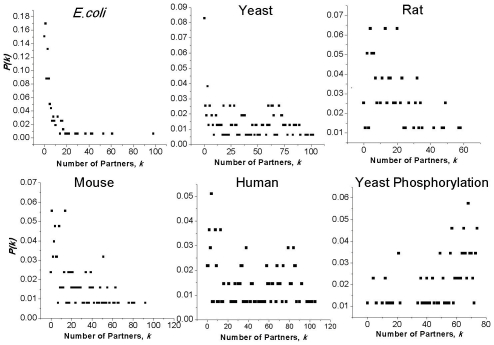
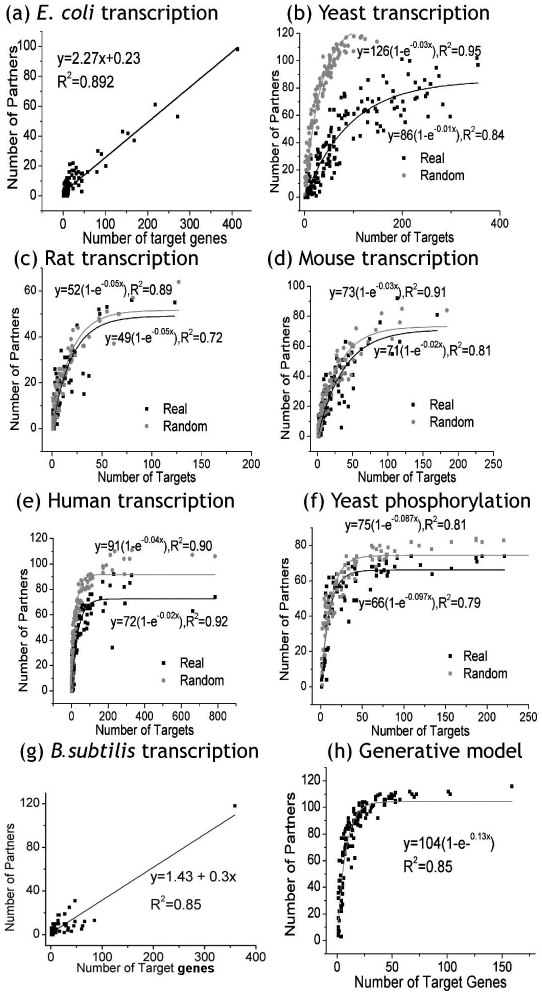
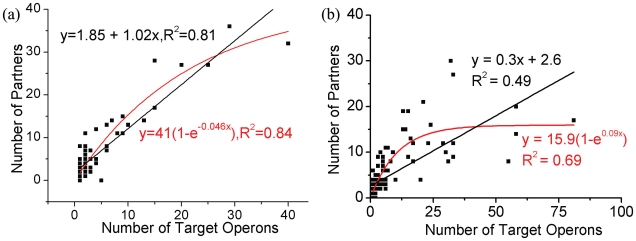
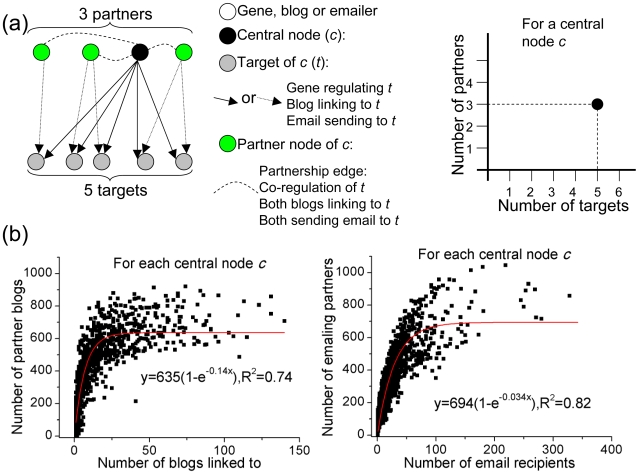
Through combinatorial regulation, regulators partner with each other to control common targets and this allows a small number of regulators to govern many targets. One interesting question is that given this combinatorial regulation, how does the number of regulators scale with the number of targets? Here, we address this question by building and analyzing co-regulation (co-transcription and co-phosphorylation) networks that describe partnerships between regulators controlling common genes. We carry out analyses across five diverse species: Escherichia coli to human. These reveal many properties of partnership networks, such as the absence of a classical power-law degree distribution despite the existence of nodes with many partners. We also find that the number of co-regulatory partnerships follows an exponential saturation curve in relation to the number of targets. (For E. coli and Bacillus subtilis, only the beginning linear part of this curve is evident due to arrangement of genes into operons.) To gain intuition into the saturation process, we relate the biological regulation to more commonplace social contexts where a small number of individuals can form an intricate web of connections on the internet. Indeed, we find that the size of partnership networks saturates even as the complexity of their output increases. We also present a variety of models to account for the saturation phenomenon. In particular, we develop a simple analytical model to show how new partnerships are acquired with an increasing number of target genes; with certain assumptions, it reproduces the observed saturation. Then, we build a more general simulation of network growth and find agreement with a wide range of real networks. Finally, we perform various down-sampling calculations on the observed data to illustrate the robustness of our conclusions.
通过组合调控,调控因子相互合作以控制共同的靶标,这使得少数调控因子能够控制许多靶标。一个有趣的问题是,给定这种组合调控,调控因子的数量如何与靶标数量相适应?在这里,我们通过构建和分析共调控(共转录和共磷酸化)网络来解决这个问题,这些网络描述了控制共同基因的调控因子之间的伙伴关系。我们在五个不同的物种中进行了分析:大肠杆菌到人类。这些揭示了伙伴关系网络的许多特性,例如尽管存在许多伙伴的节点,但不存在经典的幂律度分布。我们还发现,共调控伙伴关系的数量与靶标数量呈指数饱和曲线关系。(对于大肠杆菌和枯草芽孢杆菌,由于基因排列在操纵子中,仅可见此曲线的开始线性部分。)为了深入了解饱和过程,我们将生物调控与更常见的社会背景联系起来,在这些背景下,少数个体可以在互联网上形成错综复杂的连接网络。事实上,我们发现伙伴关系网络的大小即使在其输出的复杂性增加的情况下也会饱和。我们还提出了各种模型来解释饱和现象。特别是,我们开发了一个简单的分析模型来展示随着靶标基因数量的增加如何获得新的伙伴关系;在某些假设下,它再现了观察到的饱和。然后,我们构建了一个更通用的网络增长模拟,并与广泛的真实网络一致。最后,我们对观察到的数据进行了各种降采样计算,以说明我们结论的稳健性。