Wei Qi, Collier Nigel
Department of Informatics, The Graduate University for Advanced Studies (Sokendai), 2-1-2 Hitotsubashi, Chiyoda-ku, Tokyo.
BMC Res Notes. 2011 Feb 4;4:32. doi: 10.1186/1756-0500-4-32.
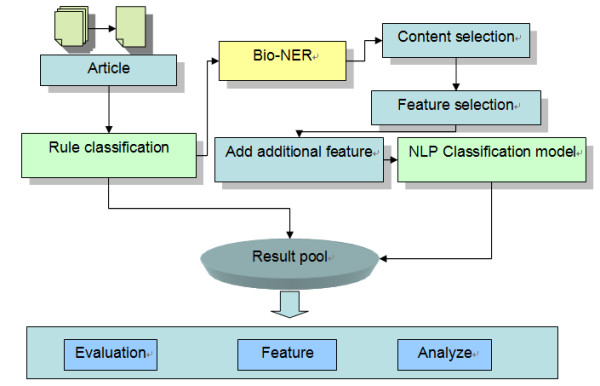
In recent years high throughput methods have led to a massive expansion in the free text literature on molecular biology. Automated text mining has developed as an application technology for formalizing this wealth of published results into structured database entries. However, database curation as a task is still largely done by hand, and although there have been many studies on automated approaches, problems remain in how to classify documents into top-level categories based on the type of organism being investigated. Here we present a comparative analysis of state of the art supervised models that are used to classify both abstracts and full text articles for three model organisms.
Ablation experiments were conducted on a large gold standard corpus of 10,000 abstracts and full papers containing data on three model organisms (fly, mouse and yeast). Among the eight learner models tested, the best model achieved an F-score of 97.1% for fly, 88.6% for mouse and 85.5% for yeast using a variety of features that included gene name, organism frequency, MeSH headings and term-species associations. We noted that term-species associations were particularly effective in improving classification performance. The benefit of using full text articles over abstracts was consistently observed across all three organisms.
By comparing various learner algorithms and features we presented an optimized system that automatically detects the major focus organism in full text articles for fly, mouse and yeast. We believe the method will be extensible to other organism types.
近年来,高通量方法使得分子生物学领域的自由文本文献大量增加。自动文本挖掘作为一种应用技术应运而生,旨在将大量已发表的研究成果整理成结构化的数据库条目。然而,数据库管理工作在很大程度上仍需人工完成,尽管已经有许多关于自动化方法的研究,但在如何根据所研究生物体的类型将文档分类到顶级类别方面仍然存在问题。在此,我们对用于对三种模式生物的摘要和全文进行分类的现有监督模型进行了比较分析。
我们在一个包含10000篇摘要和全文的大型金标准语料库上进行了消融实验,这些文献包含三种模式生物(果蝇、小鼠和酵母)的数据。在所测试的八个学习模型中,最佳模型使用包括基因名称、生物体频率、医学主题词(MeSH)和术语-物种关联等多种特征,对果蝇的F值达到97.1%,对小鼠为88.6%,对酵母为85.5%。我们注意到术语-物种关联在提高分类性能方面特别有效。在所有三种生物体中,始终观察到使用全文比使用摘要更具优势。
通过比较各种学习算法和特征,我们提出了一个优化系统,该系统能够自动检测果蝇、小鼠和酵母全文中的主要研究生物体。我们相信该方法将可扩展到其他生物体类型。