Computer Laboratory, University of Cambridge, 15 JJ Thomson Avenue, Cambridge CB30FD, UK.
BMC Bioinformatics. 2011 Mar 8;12:69. doi: 10.1186/1471-2105-12-69.
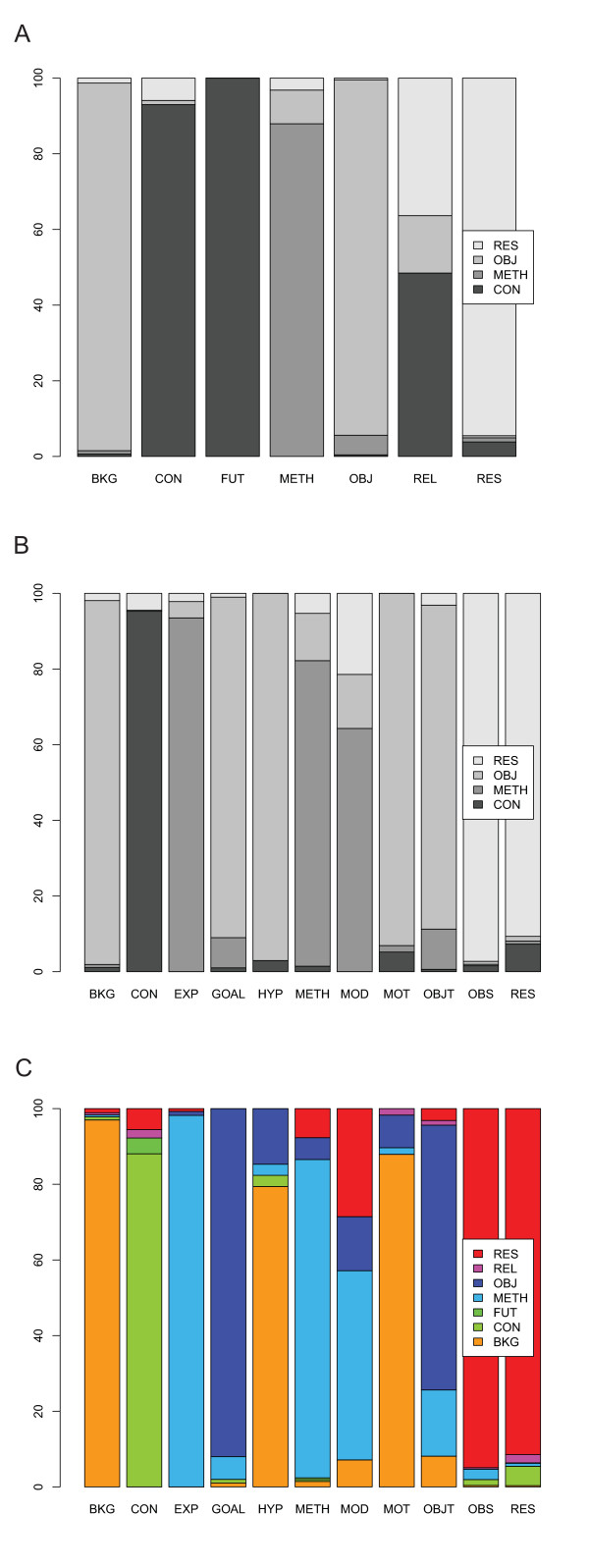
Many practical tasks in biomedicine require accessing specific types of information in scientific literature; e.g. information about the results or conclusions of the study in question. Several schemes have been developed to characterize such information in scientific journal articles. For example, a simple section-based scheme assigns individual sentences in abstracts under sections such as Objective, Methods, Results and Conclusions. Some schemes of textual information structure have proved useful for biomedical text mining (BIO-TM) tasks (e.g. automatic summarization). However, user-centered evaluation in the context of real-life tasks has been lacking.
We take three schemes of different type and granularity--those based on section names, Argumentative Zones (AZ) and Core Scientific Concepts (CoreSC)--and evaluate their usefulness for a real-life task which focuses on biomedical abstracts: Cancer Risk Assessment (CRA). We annotate a corpus of CRA abstracts according to each scheme, develop classifiers for automatic identification of the schemes in abstracts, and evaluate both the manual and automatic classifications directly as well as in the context of CRA.
Our results show that for each scheme, the majority of categories appear in abstracts, although two of the schemes (AZ and CoreSC) were developed originally for full journal articles. All the schemes can be identified in abstracts relatively reliably using machine learning. Moreover, when cancer risk assessors are presented with scheme annotated abstracts, they find relevant information significantly faster than when presented with unannotated abstracts, even when the annotations are produced using an automatic classifier. Interestingly, in this user-based evaluation the coarse-grained scheme based on section names proved nearly as useful for CRA as the finest-grained CoreSC scheme.
We have shown that existing schemes aimed at capturing information structure of scientific documents can be applied to biomedical abstracts and can be identified in them automatically with an accuracy which is high enough to benefit a real-life task in biomedicine.
许多生物医学领域的实际任务都需要在科学文献中获取特定类型的信息;例如,与所研究问题的结果或结论相关的信息。已经开发了几种方案来描述科学期刊文章中的此类信息。例如,一种简单的基于节的方案将摘要中属于目标、方法、结果和结论等节的句子单独分配。一些文本信息结构方案已被证明对生物医学文本挖掘(BIO-TM)任务(例如自动摘要)有用。然而,在现实任务的背景下,缺乏以用户为中心的评估。
我们采用了三种不同类型和粒度的方案 - 基于节名、论证区(AZ)和核心科学概念(CoreSC)的方案 - 并评估它们在一个专注于生物医学摘要的现实任务中的有用性:癌症风险评估(CRA)。我们根据每个方案对 CRA 摘要进行注释,为自动识别摘要中的方案开发分类器,并直接以及在 CRA 的背景下评估手动和自动分类。
我们的结果表明,对于每种方案,大多数类别都出现在摘要中,尽管其中两种方案(AZ 和 CoreSC)最初是为完整的期刊文章开发的。所有方案都可以使用机器学习相对可靠地在摘要中识别。此外,当癌症风险评估员被呈现带有方案注释的摘要时,他们比呈现未注释的摘要时能够更快地找到相关信息,即使注释是使用自动分类器生成的。有趣的是,在这种基于用户的评估中,基于节名的粗粒度方案对于 CRA 几乎与最细粒度的 CoreSC 方案一样有用。
我们已经表明,旨在捕获科学文档信息结构的现有方案可应用于生物医学摘要,并可使用足够高的精度自动识别它们,从而有益于生物医学中的现实任务。