Division of Human Genetics, School of Pathology, Faculty of Health Sciences, National Health Laboratory Service & University of the Witwatersrand, Johannesburg, 2000, South Africa.
Biol Direct. 2011 Jun 13;6:30. doi: 10.1186/1745-6150-6-30.
Several computational candidate gene selection and prioritization methods have recently been developed. These in silico selection and prioritization techniques are usually based on two central approaches--the examination of similarities to known disease genes and/or the evaluation of functional annotation of genes. Each of these approaches has its own caveats. Here we employ a previously described method of candidate gene prioritization based mainly on gene annotation, in accompaniment with a technique based on the evaluation of pertinent sequence motifs or signatures, in an attempt to refine the gene prioritization approach. We apply this approach to X-linked mental retardation (XLMR), a group of heterogeneous disorders for which some of the underlying genetics is known.
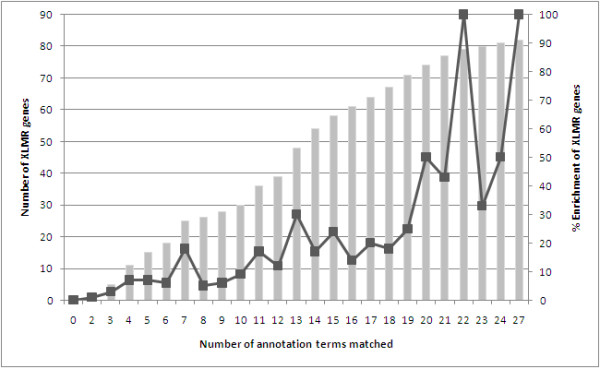
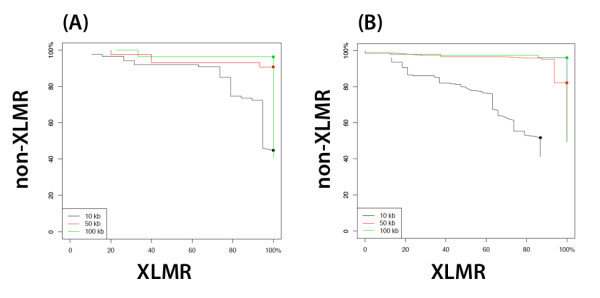
The gene annotation-based binary filtering method yielded a ranked list of putative XLMR candidate genes with good plausibility of being associated with the development of mental retardation. In parallel, a motif finding approach based on linear discriminatory analysis (LDA) was employed to identify short sequence patterns that may discriminate XLMR from non-XLMR genes. High rates (>80%) of correct classification was achieved, suggesting that the identification of these motifs effectively captures genomic signals associated with XLMR vs. non-XLMR genes. The computational tools developed for the motif-based LDA is integrated into the freely available genomic analysis portal Galaxy (http://main.g2.bx.psu.edu/). Nine genes (APLN, ZC4H2, MAGED4, MAGED4B, RAP2C, FAM156A, FAM156B, TBL1X, and UXT) were highlighted as highly-ranked XLMR methods.
The combination of gene annotation information and sequence motif-orientated computational candidate gene prediction methods highlight an added benefit in generating a list of plausible candidate genes, as has been demonstrated for XLMR.
最近已经开发出了几种计算候选基因选择和优先级排序方法。这些基于计算机的选择和优先级排序技术通常基于两种核心方法——检查与已知疾病基因的相似性和/或评估基因的功能注释。这些方法都有各自的注意事项。在这里,我们使用以前描述的主要基于基因注释的候选基因优先级排序方法,同时使用基于评估相关序列基序或特征的技术,试图改进基因优先级排序方法。我们将这种方法应用于 X 连锁智力低下(XLMR),这是一组异质性疾病,其中一些潜在的遗传学已经为人所知。
基于基因注释的二进制过滤方法生成了一份假定的 XLMR 候选基因的排名列表,这些基因具有与智力低下发育相关的良好可能性。同时,还采用了基于线性判别分析(LDA)的基序发现方法来识别可能区分 XLMR 与非 XLMR 基因的短序列模式。高的正确分类率(>80%)表明,这些基序的识别有效地捕获了与 XLMR 与非 XLMR 基因相关的基因组信号。为基于基序的 LDA 开发的计算工具已集成到免费提供的基因组分析门户 Galaxy(http://main.g2.bx.psu.edu/)中。九个基因(APLN、ZC4H2、MAGED4、MAGED4B、RAP2C、FAM156A、FAM156B、TBL1X 和 UXT)被突出显示为高排名的 XLMR 方法。
基因注释信息和序列基序导向的计算候选基因预测方法的结合在生成可能的候选基因列表方面具有额外的优势,正如在 XLMR 中所证明的那样。