Obleser Jonas, Leaver Amber M, Vanmeter John, Rauschecker Josef P
Laboratory of Integrative Neuroscience and Cognition, Department of Physiology and Biophysics, Georgetown University Medical Center Washington, DC, USA.
Front Psychol. 2010 Dec 24;1:232. doi: 10.3389/fpsyg.2010.00232. eCollection 2010.
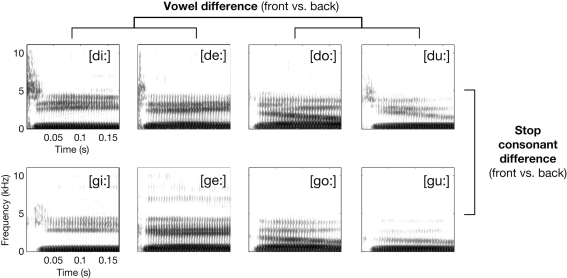
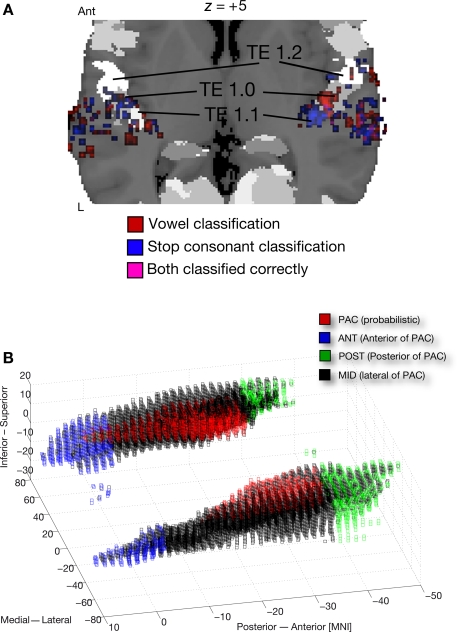
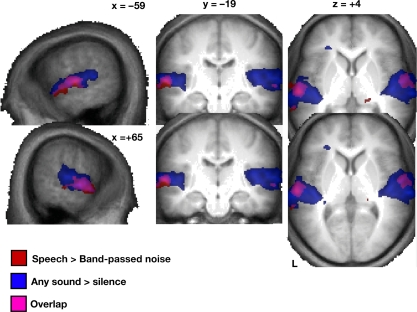
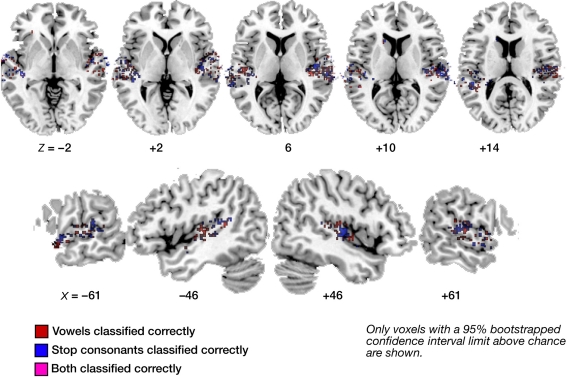
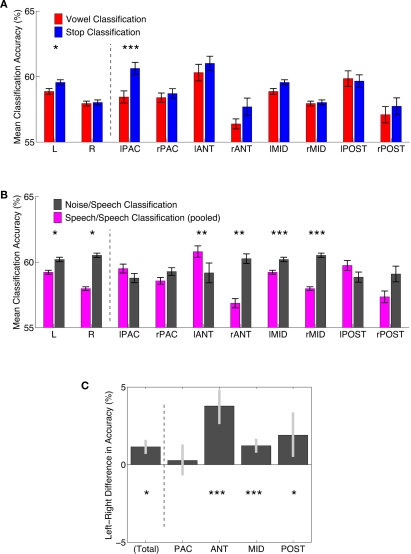
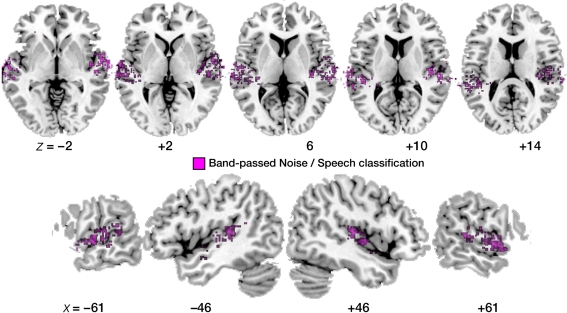
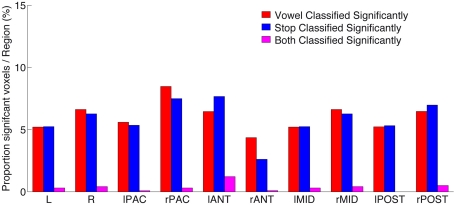
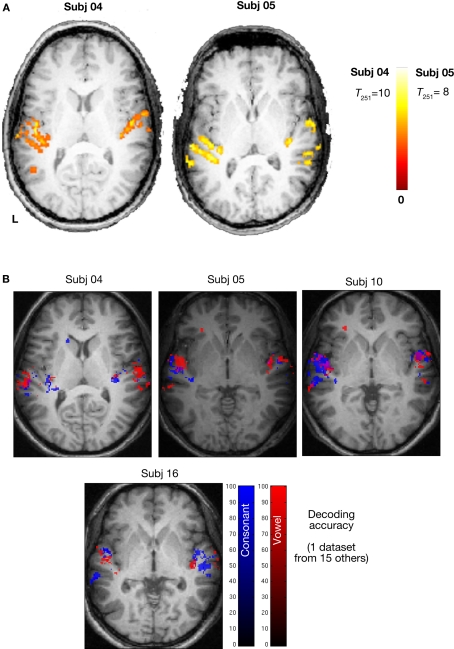
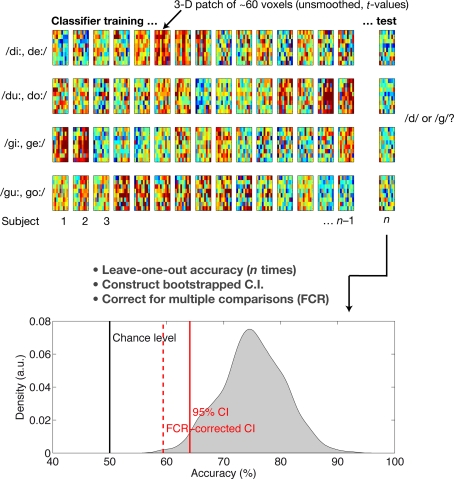
The speech signal consists of a continuous stream of consonants and vowels, which must be de- and encoded in human auditory cortex to ensure the robust recognition and categorization of speech sounds. We used small-voxel functional magnetic resonance imaging to study information encoded in local brain activation patterns elicited by consonant-vowel syllables, and by a control set of noise bursts. First, activation of anterior-lateral superior temporal cortex was seen when controlling for unspecific acoustic processing (syllables versus band-passed noises, in a "classic" subtraction-based design). Second, a classifier algorithm, which was trained and tested iteratively on data from all subjects to discriminate local brain activation patterns, yielded separations of cortical patches discriminative of vowel category versus patches discriminative of stop-consonant category across the entire superior temporal cortex, yet with regional differences in average classification accuracy. Overlap (voxels correctly classifying both speech sound categories) was surprisingly sparse. Third, lending further plausibility to the results, classification of speech-noise differences was generally superior to speech-speech classifications, with the no\ exception of a left anterior region, where speech-speech classification accuracies were significantly better. These data demonstrate that acoustic-phonetic features are encoded in complex yet sparsely overlapping local patterns of neural activity distributed hierarchically across different regions of the auditory cortex. The redundancy apparent in these multiple patterns may partly explain the robustness of phonemic representations.
语音信号由一连串连续的辅音和元音组成,这些辅音和元音必须在人类听觉皮层中进行解码和编码,以确保对语音的可靠识别和分类。我们使用小体素功能磁共振成像来研究由辅音 - 元音音节以及一组对照噪声脉冲所引发的局部脑激活模式中编码的信息。首先,在控制非特异性声学处理时(在基于“经典”减法设计中,音节与带通噪声对比),观察到前外侧颞上回的激活。其次,一种分类算法,该算法在所有受试者的数据上进行迭代训练和测试以区分局部脑激活模式,在整个颞上回中产生了区分元音类别与塞音类别皮质斑块的分离,但平均分类准确率存在区域差异。重叠部分(正确对两种语音类别进行分类的体素)出奇地稀疏。第三,为结果提供了进一步的可信度,语音 - 噪声差异的分类通常优于语音 - 语音分类,除了左前区域,在该区域语音 - 语音分类准确率明显更高。这些数据表明,声学语音特征在听觉皮层不同区域分层分布的复杂但稀疏重叠的局部神经活动模式中进行编码。这些多种模式中明显的冗余可能部分解释了音素表征的稳健性。