Pharma Research and Early Development, Hoffmann-La Roche Inc., Nutley, NJ 07110, USA.
Bioinformatics. 2011 Oct 1;27(19):2769-71. doi: 10.1093/bioinformatics/btr455. Epub 2011 Aug 3.
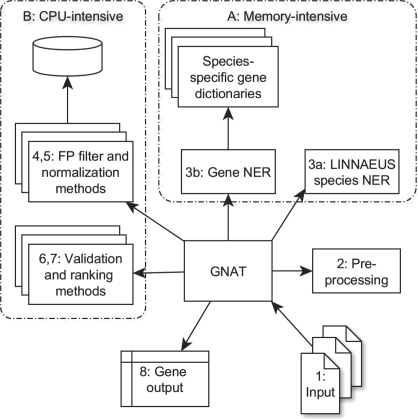
Identifying mentions of named entities, such as genes or diseases, and normalizing them to database identifiers have become an important step in many text and data mining pipelines. Despite this need, very few entity normalization systems are publicly available as source code or web services for biomedical text mining. Here we present the Gnat Java library for text retrieval, named entity recognition, and normalization of gene and protein mentions in biomedical text. The library can be used as a component to be integrated with other text-mining systems, as a framework to add user-specific extensions, and as an efficient stand-alone application for the identification of gene and protein names for data analysis. On the BioCreative III test data, the current version of Gnat achieves a Tap-20 score of 0.1987.
The library and web services are implemented in Java and the sources are available from http://gnat.sourceforge.net.
在许多文本和数据挖掘管道中,识别命名实体(如基因或疾病)并将其标准化为数据库标识符已成为一个重要步骤。尽管有这种需求,但很少有实体标准化系统以生物医学文本挖掘的源代码或 Web 服务的形式公开提供。在这里,我们介绍 Gnat Java 库,用于文本检索、命名实体识别以及生物医学文本中基因和蛋白质提及的标准化。该库可作为与其他文本挖掘系统集成的组件、作为添加用户特定扩展的框架,以及作为用于数据分析的基因和蛋白质名称识别的高效独立应用程序。在 BioCreative III 测试数据上,当前版本的 Gnat 的 Tap-20 得分为 0.1987。
该库和 Web 服务是用 Java 实现的,源代码可从 http://gnat.sourceforge.net 获得。