Howard Hughes Medical Institute, New York University, New York, NY 10003, USA.
Neuron. 2011 Sep 8;71(5):926-40. doi: 10.1016/j.neuron.2011.06.032.
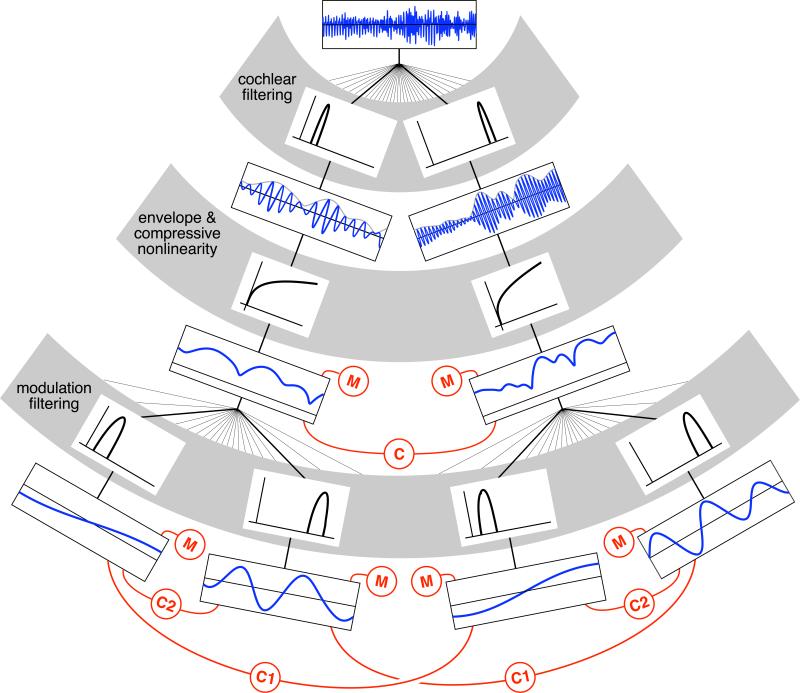
Rainstorms, insect swarms, and galloping horses produce "sound textures"--the collective result of many similar acoustic events. Sound textures are distinguished by temporal homogeneity, suggesting they could be recognized with time-averaged statistics. To test this hypothesis, we processed real-world textures with an auditory model containing filters tuned for sound frequencies and their modulations, and measured statistics of the resulting decomposition. We then assessed the realism and recognizability of novel sounds synthesized to have matching statistics. Statistics of individual frequency channels, capturing spectral power and sparsity, generally failed to produce compelling synthetic textures; however, combining them with correlations between channels produced identifiable and natural-sounding textures. Synthesis quality declined if statistics were computed from biologically implausible auditory models. The results suggest that sound texture perception is mediated by relatively simple statistics of early auditory representations, presumably computed by downstream neural populations. The synthesis methodology offers a powerful tool for their further investigation.
暴雨、虫群和奔腾的马群会产生“声音纹理”——许多相似声学事件的综合结果。声音纹理的时间均一性特征明显,这表明它们可以通过时间平均统计数据来识别。为了验证这一假设,我们使用包含针对声音频率及其调制进行调谐的滤波器的听觉模型来处理真实世界的纹理,并测量由此产生的分解的统计数据。然后,我们评估了为匹配统计数据而合成的新颖声音的逼真度和可识别度。单个频率通道的统计数据,捕捉频谱功率和稀疏性,通常无法产生引人入胜的合成纹理;然而,将它们与通道之间的相关性相结合,会产生可识别且听起来自然的纹理。如果统计数据是从生物上不可信的听觉模型中计算出来的,则合成质量会下降。结果表明,声音纹理感知是由早期听觉表示的相对简单的统计数据介导的,这些统计数据可能是由下游神经群体计算出来的。该合成方法为进一步研究提供了一个强大的工具。