MRC Biostatistics Unit, Cambridge, UK.
Stat Med. 2012 May 20;31(11-12):1238-48. doi: 10.1002/sim.4356. Epub 2011 Sep 8.
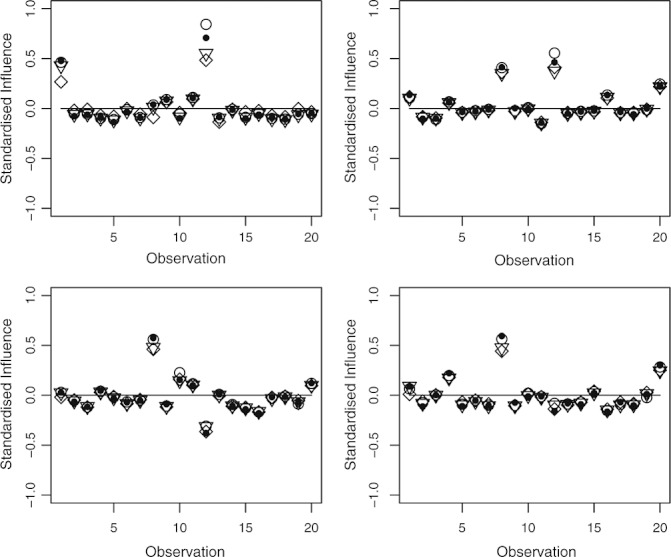
In statistical modelling, it is often important to know how much parameter estimates are influenced by particular observations. An attractive approach is to re-estimate the parameters with each observation deleted in turn, but this is computationally demanding when fitting models by using Markov chain Monte Carlo (MCMC), as obtaining complete sample estimates is often in itself a very time-consuming task. Here we propose two efficient ways to approximate the case-deleted estimates by using output from MCMC estimation. Our first proposal, which directly approximates the usual influence statistics in maximum likelihood analyses of generalised linear models (GLMs), is easy to implement and avoids any further evaluation of the likelihood. Hence, unlike the existing alternatives, it does not become more computationally intensive as the model complexity increases. Our second proposal, which utilises model perturbations, also has this advantage and does not require the form of the GLM to be specified. We show how our two proposed methods are related and evaluate them against the existing method of importance sampling and case deletion in a logistic regression analysis with missing covariates. We also provide practical advice for those implementing our procedures, so that they may be used in many situations where MCMC is used to fit statistical models.
在统计建模中,了解参数估计值受特定观测值影响的程度通常很重要。一种有吸引力的方法是依次删除每个观测值来重新估计参数,但当使用马尔可夫链蒙特卡罗 (MCMC) 拟合模型时,这在计算上是很繁琐的,因为获得完整的样本估计值本身往往是一项非常耗时的任务。在这里,我们提出了两种利用 MCMC 估计输出来近似删除案例估计值的有效方法。我们的第一个建议是直接近似广义线性模型 (GLM) 最大似然分析中常用的影响统计量,它易于实现,并且避免了对似然函数的任何进一步评估。因此,与现有替代方法不同,随着模型复杂性的增加,它不会变得更加计算密集。我们的第二个建议利用模型扰动,也具有这个优势,并且不需要指定 GLM 的形式。我们展示了我们提出的两种方法之间的关系,并在带有缺失协变量的逻辑回归分析中针对现有重要抽样和案例删除方法对它们进行了评估。我们还为那些实施我们的程序的人提供了实用建议,以便在使用 MCMC 拟合统计模型的许多情况下使用它们。