Center for Systems Biology, Soochow University, Suzhou, Jiangsu, China.
PLoS One. 2012;7(6):e39230. doi: 10.1371/journal.pone.0039230. Epub 2012 Jun 26.
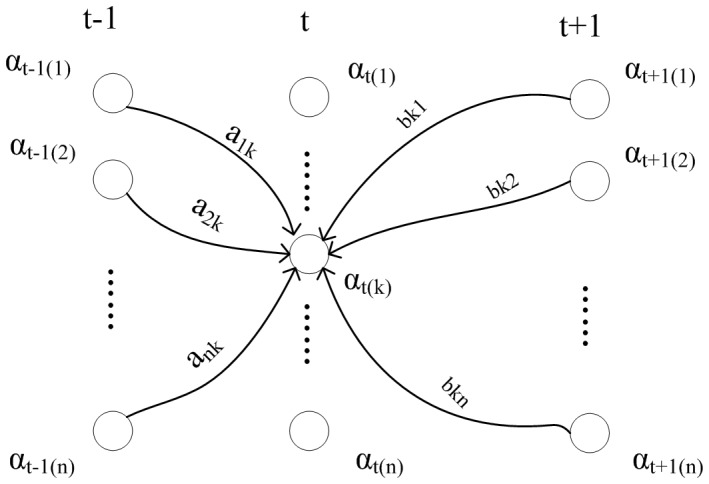
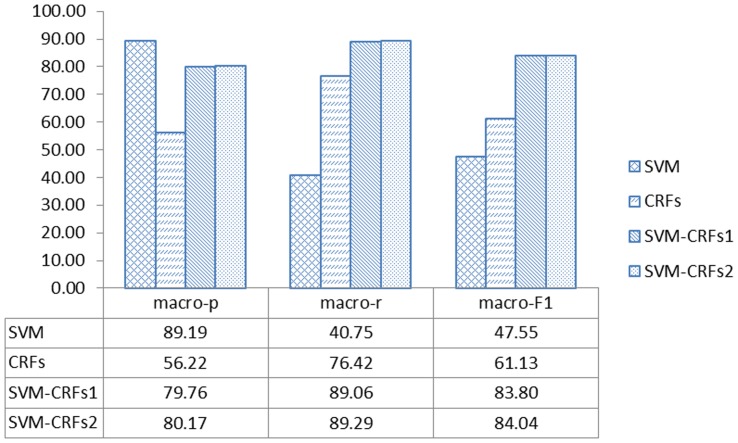
Biological named entity recognition, the identification of biological terms in text, is essential for biomedical information extraction. Machine learning-based approaches have been widely applied in this area. However, the recognition performance of current approaches could still be improved. Our novel approach is to combine support vector machines (SVMs) and conditional random fields (CRFs), which can complement and facilitate each other. During the hybrid process, we use SVM to separate biological terms from non-biological terms, before we use CRFs to determine the types of biological terms, which makes full use of the power of SVM as a binary-class classifier and the data-labeling capacity of CRFs. We then merge the results of SVM and CRFs. To remove any inconsistencies that might result from the merging, we develop a useful algorithm and apply two rules. To ensure biological terms with a maximum length are identified, we propose a maximal bidirectional squeezing approach that finds the longest term. We also add a positive gain to rare events to reinforce their probability and avoid bias. Our approach will also gradually extend the context so more contextual information can be included. We examined the performance of four approaches with GENIA corpus and JNLPBA04 data. The combination of SVM and CRFs improved performance. The macro-precision, macro-recall, and macro-F(1) of the SVM-CRFs hybrid approach surpassed conventional SVM and CRFs. After applying the new algorithms, the macro-F1 reached 91.67% with the GENIA corpus and 84.04% with the JNLPBA04 data.
生物命名实体识别,即文本中生物术语的识别,是生物医学信息提取的关键。基于机器学习的方法已广泛应用于该领域。然而,当前方法的识别性能仍有待提高。我们的新方法是结合支持向量机(SVM)和条件随机场(CRFs),它们可以相互补充和促进。在混合过程中,我们使用 SVM 将生物术语与非生物术语分开,然后使用 CRFs 确定生物术语的类型,这充分利用了 SVM 作为二分类器的功能和 CRFs 的数据标记能力。然后,我们合并 SVM 和 CRFs 的结果。为了消除合并可能导致的任何不一致,我们开发了一种有用的算法并应用了两条规则。为了确保识别出具有最大长度的生物术语,我们提出了一种最长双向挤压方法来找到最长的术语。我们还为稀有事件增加了正增益,以增强它们的概率并避免偏差。我们的方法还将逐步扩展上下文,以包含更多的上下文信息。我们使用 GENIA 语料库和 JNLPBA04 数据评估了四种方法的性能。SVM 和 CRFs 的组合提高了性能。SVM-CRFs 混合方法的宏精度、宏召回率和宏 F1 均优于传统的 SVM 和 CRFs。在应用新算法后,宏 F1 在 GENIA 语料库中达到 91.67%,在 JNLPBA04 数据中达到 84.04%。