Department of Computer Science and Engineering, University of Washington, Seattle, WA 98195-2350, USA.
Nucleic Acids Res. 2012 Dec;40(22):e171. doi: 10.1093/nar/gks754. Epub 2012 Aug 16.
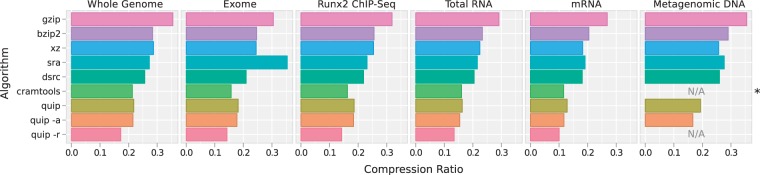
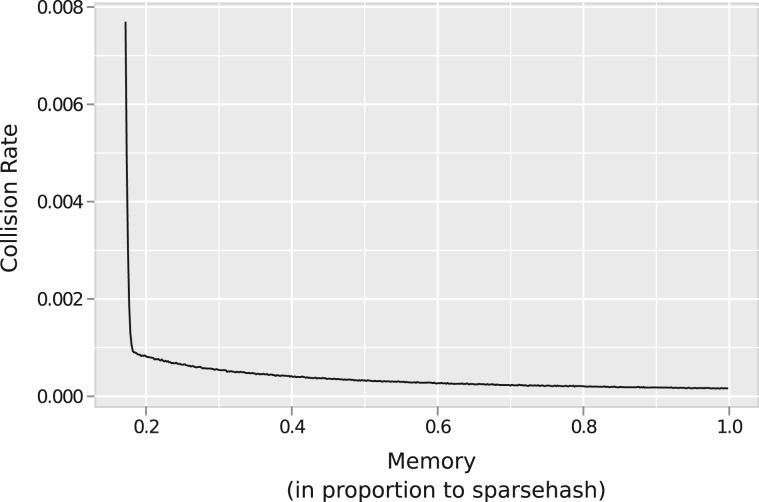
We present Quip, a lossless compression algorithm for next-generation sequencing data in the FASTQ and SAM/BAM formats. In addition to implementing reference-based compression, we have developed, to our knowledge, the first assembly-based compressor, using a novel de novo assembly algorithm. A probabilistic data structure is used to dramatically reduce the memory required by traditional de Bruijn graph assemblers, allowing millions of reads to be assembled very efficiently. Read sequences are then stored as positions within the assembled contigs. This is combined with statistical compression of read identifiers, quality scores, alignment information and sequences, effectively collapsing very large data sets to <15% of their original size with no loss of information.
Quip is freely available under the 3-clause BSD license from http://cs.washington.edu/homes/dcjones/quip.
我们提出了 Quip,这是一种用于 FASTQ 和 SAM/BAM 格式的下一代测序数据的无损压缩算法。除了实现基于参考的压缩外,我们还开发了(据我们所知)第一个基于组装的压缩器,使用了一种新颖的从头组装算法。我们使用一种概率数据结构极大地减少了传统 de Bruijn 图组装程序所需的内存,从而可以非常有效地组装数百万个读取。然后,将读取序列存储为已组装的连续统中的位置。这与读取标识符、质量分数、比对信息和序列的统计压缩相结合,有效地将非常大的数据集压缩到原始大小的 15%以下,而不会丢失任何信息。
Quip 可根据 3 条款 BSD 许可证从 http://cs.washington.edu/homes/dcjones/quip 免费获得。