Heselmans Annemie, Aertgeerts Bert, Donceel Peter, Van de Velde Stijn, Vanbrabant Peter, Ramaekers Dirk
School of Public Health and Primary Care, Katholieke Universiteit Leuven, Leuven, Belgium.
J Med Internet Res. 2013 Jan 17;15(1):e8. doi: 10.2196/jmir.2055.
Guideline developers use different consensus methods to develop evidence-based clinical practice guidelines. Previous research suggests that existing guideline development techniques are subject to methodological problems and are logistically demanding. Guideline developers welcome new methods that facilitate a methodologically sound decision-making process. Systems that aggregate knowledge while participants play a game are one class of human computation applications. Researchers have already proven that these games with a purpose are effective in building common sense knowledge databases.
We aimed to evaluate the feasibility of a new consensus method based on human computation techniques compared to an informal face-to-face consensus method.
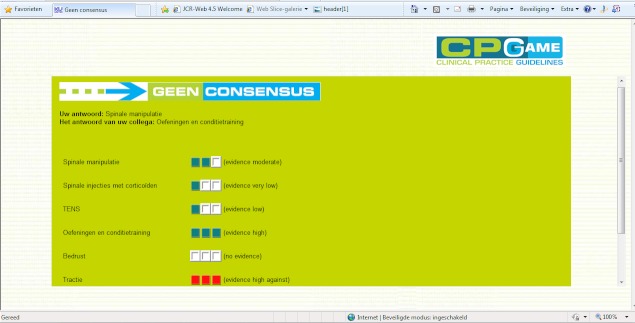
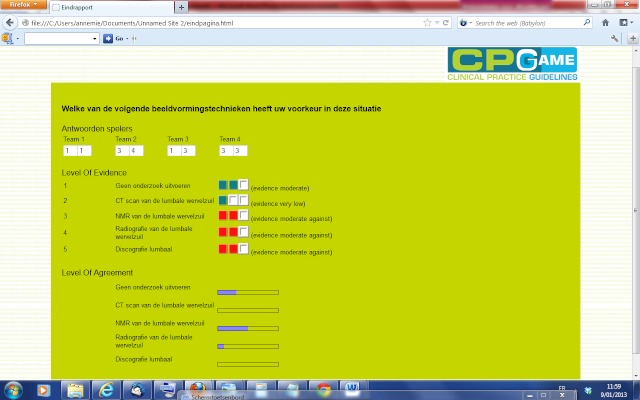
We set up a randomized design to study 2 different methods for guideline development within a group of advanced students completing a master of nursing and obstetrics. Students who participated in the trial were enrolled in an evidence-based health care course. We compared the Web-based method of human-based computation (HC) with an informal face-to-face consensus method (IC). We used 4 clinical scenarios of lower back pain as the subject of the consensus process. These scenarios concerned the following topics: (1) medical imaging, (2) therapeutic options, (3) drugs use, and (4) sick leave. Outcomes were expressed as the amount of group (dis)agreement and the concordance of answers with clinical evidence. We estimated within-group and between-group effect sizes by calculating Cohen's d. We calculated within-group effect sizes as the absolute difference between the outcome value at round 3 and the baseline outcome value, divided by the pooled standard deviation. We calculated between-group effect sizes as the absolute difference between the mean change in outcome value across rounds in HC and the mean change in outcome value across rounds in IC, divided by the pooled standard deviation. We analyzed statistical significance of within-group changes between round 1 and round 3 using the Wilcoxon signed rank test. We assessed the differences between the HC and IC groups using Mann-Whitney U tests. We used a Bonferroni adjusted alpha level of .025 in all statistical tests. We performed a thematic analysis to explore participants' arguments during group discussion. Participants completed a satisfaction survey at the end of the consensus process.
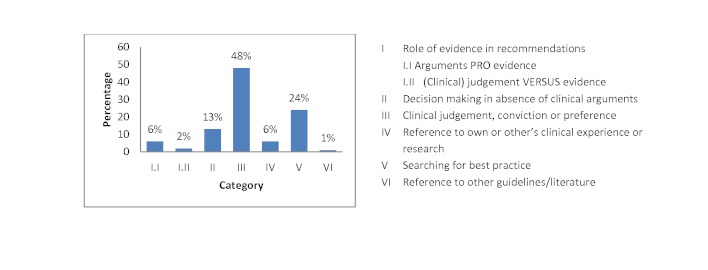
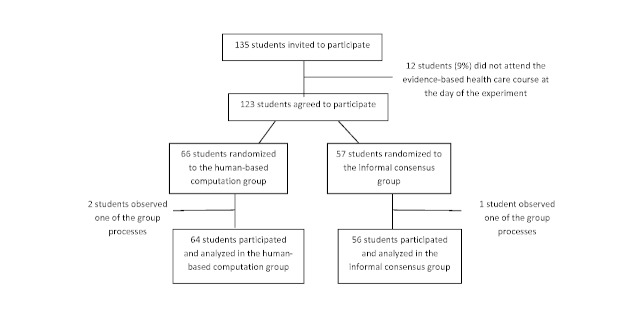
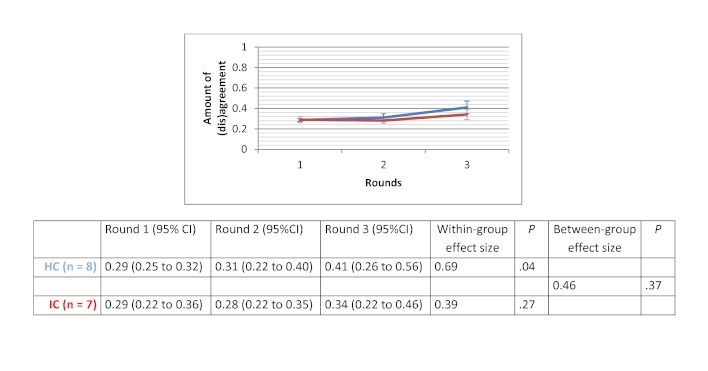
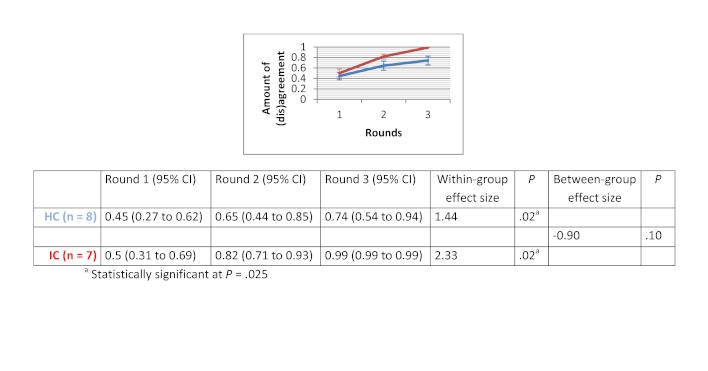
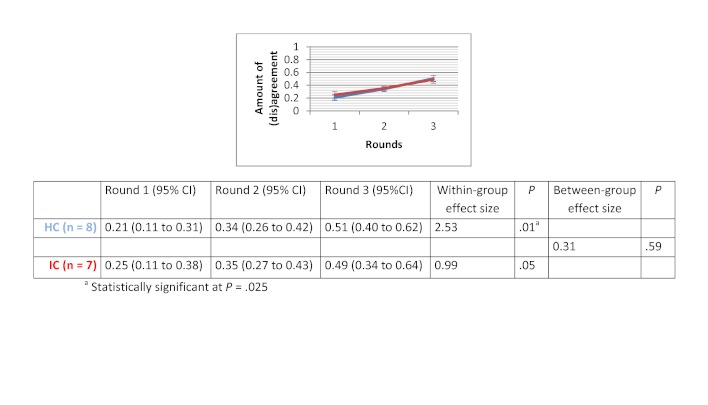
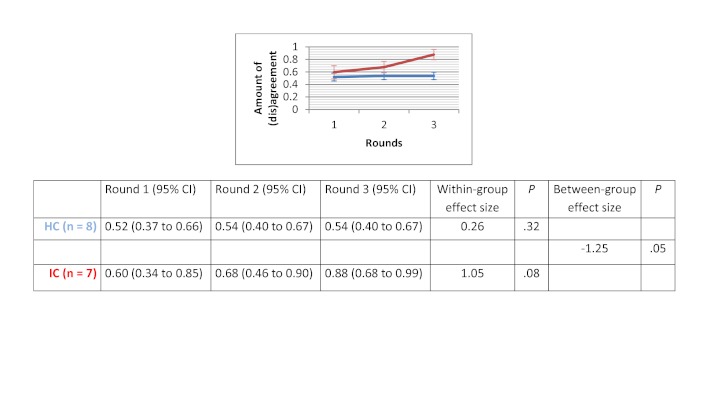
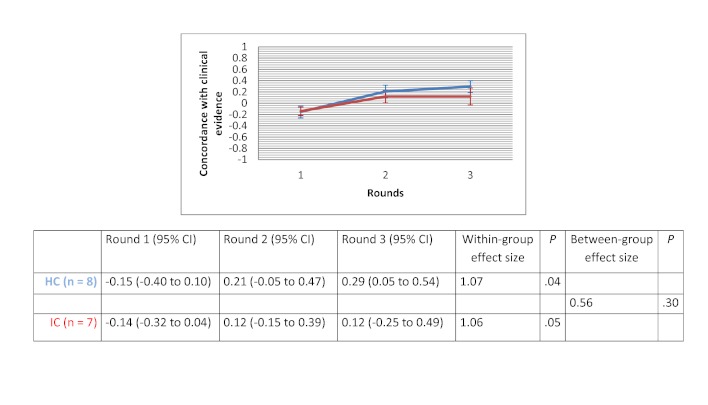
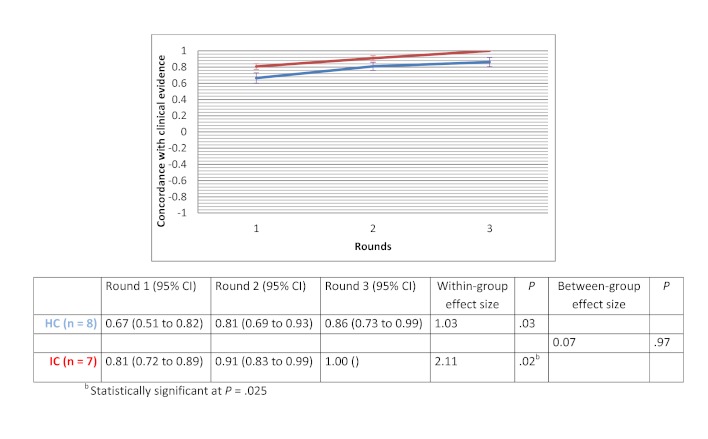
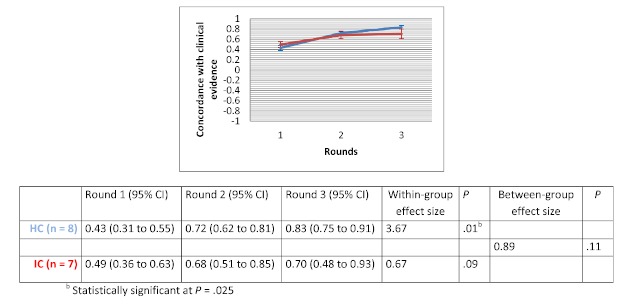
Of the 135 students completing a master of nursing and obstetrics, 120 participated in the experiment. We formed 8 HC groups (n=64) and 7 IC groups (n=56). The between-group comparison demonstrated that the human computation groups obtained a greater improvement in evidence scores compared to the IC groups, although the difference was not statistically significant. The between-group effect size was 0.56 (P=.30) for the medical imaging scenario, 0.07 (P=.97) for the therapeutic options scenario, and 0.89 (P=.11) for the drug use scenario. We found no significant differences in improvement in the degree of agreement between HC and IC groups. Between-group comparisons revealed that the HC groups showed greater improvement in degree of agreement for the medical imaging scenario (d=0.46, P=.37) and the drug use scenario (d=0.31, P=.59). Very few evidence arguments (6%) were quoted during informal group discussions.
Overall, the use of the IC method was appropriate as long as the evidence supported participants' beliefs or usual practice, or when the availability of the evidence was sparse. However, when some controversy about the evidence existed, the HC method outperformed the IC method. The findings of our study illustrate the importance of the choice of the consensus method in guideline development. Human computation could be an acceptable methodology for guideline development specifically for scenarios in which the evidence shows no resonance with participants' beliefs. Future research is needed to confirm the results of this study and to establish practical significance in a controlled setting of multidisciplinary guideline panels during real-life guideline development.
指南制定者使用不同的共识方法来制定基于证据的临床实践指南。先前的研究表明,现有的指南制定技术存在方法学问题,且在后勤方面要求较高。指南制定者欢迎有助于进行方法学上合理的决策过程的新方法。在参与者玩游戏时汇总知识的系统是一类人类计算应用程序。研究人员已经证明,这些有目的的游戏在构建常识知识库方面是有效的。
我们旨在评估一种基于人类计算技术的新共识方法与非正式面对面共识方法相比的可行性。
我们设置了一项随机设计,以研究在一组完成护理学与产科学硕士学位的高年级学生中用于指南制定的2种不同方法。参与试验的学生参加了一门基于证据的医疗保健课程。我们将基于网络的人类计算方法(HC)与非正式面对面共识方法(IC)进行了比较。我们使用4个下背痛的临床场景作为共识过程的主题。这些场景涉及以下主题:(1)医学成像,(2)治疗选择,(3)药物使用,以及(4)病假。结果以小组(不)一致的程度以及答案与临床证据的一致性来表示。我们通过计算科恩d值来估计组内和组间效应量。我们将组内效应量计算为第3轮结果值与基线结果值之间的绝对差值,除以合并标准差。我们将组间效应量计算为HC组各轮结果值平均变化与IC组各轮结果值平均变化之间的绝对差值,除以合并标准差。我们使用威尔科克森符号秩检验分析第1轮和第3轮之间组内变化的统计学显著性。我们使用曼-惠特尼U检验评估HC组和IC组之间的差异。在所有统计检验中,我们使用经邦费罗尼校正的α水平为0.025。我们进行了主题分析,以探讨小组讨论期间参与者的论点。参与者在共识过程结束时完成了一项满意度调查。
在135名完成护理学与产科学硕士学位的学生中,120名参与了实验。我们组建了8个HC组(n = 64)和7个IC组(n = 56)。组间比较表明,与IC组相比,人类计算组在证据得分方面有更大的提高,尽管差异无统计学意义。医学成像场景的组间效应量为0.56(P = 0.30),治疗选择场景为0.07(P = 0.97),药物使用场景为0.89(P = 0.11)。我们发现HC组和IC组在一致程度的提高方面没有显著差异。组间比较显示,HC组在医学成像场景(d = 0.46,P = 0.37)和药物使用场景(d = 0.31,P = 0.59)的一致程度上有更大的提高。在非正式小组讨论期间,很少引用证据性论据(6%)。
总体而言,只要证据支持参与者的信念或常规做法,或者证据的可得性较少,使用IC方法就是合适的。然而,当存在关于证据的一些争议时,HC方法优于IC方法。我们研究的结果说明了在指南制定中选择共识方法的重要性。人类计算可能是一种可接受的指南制定方法,特别是对于证据与参与者信念不相符的场景。需要未来的研究来证实本研究的结果,并在现实生活中的指南制定过程中在多学科指南小组的受控环境中确定其实际意义。