McCormick Tyler H, Salganik Matthew J, Zheng Tian
Department of Statistics, Columbia University, New York, New York, 10027.
J Am Stat Assoc. 2010 Mar 1;105(489):59-70. doi: 10.1198/jasa.2009.ap08518.
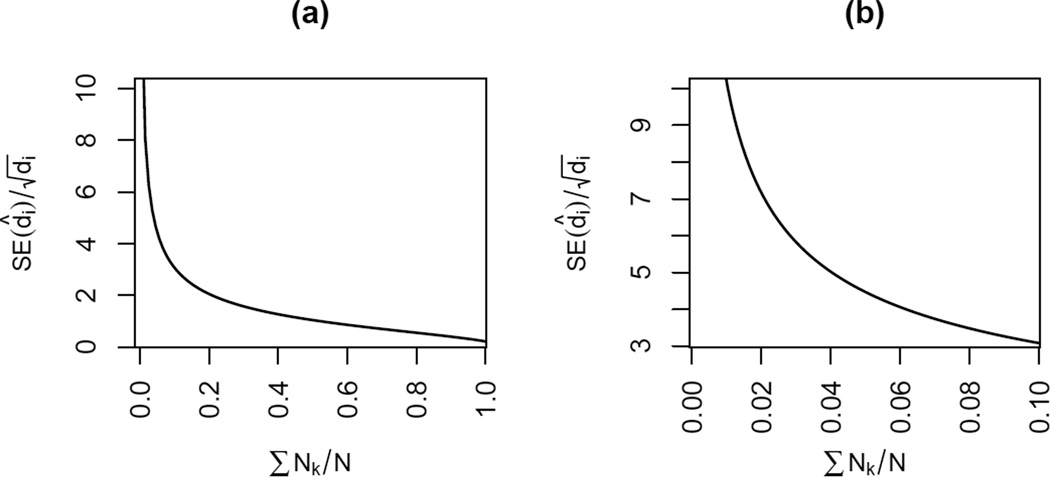
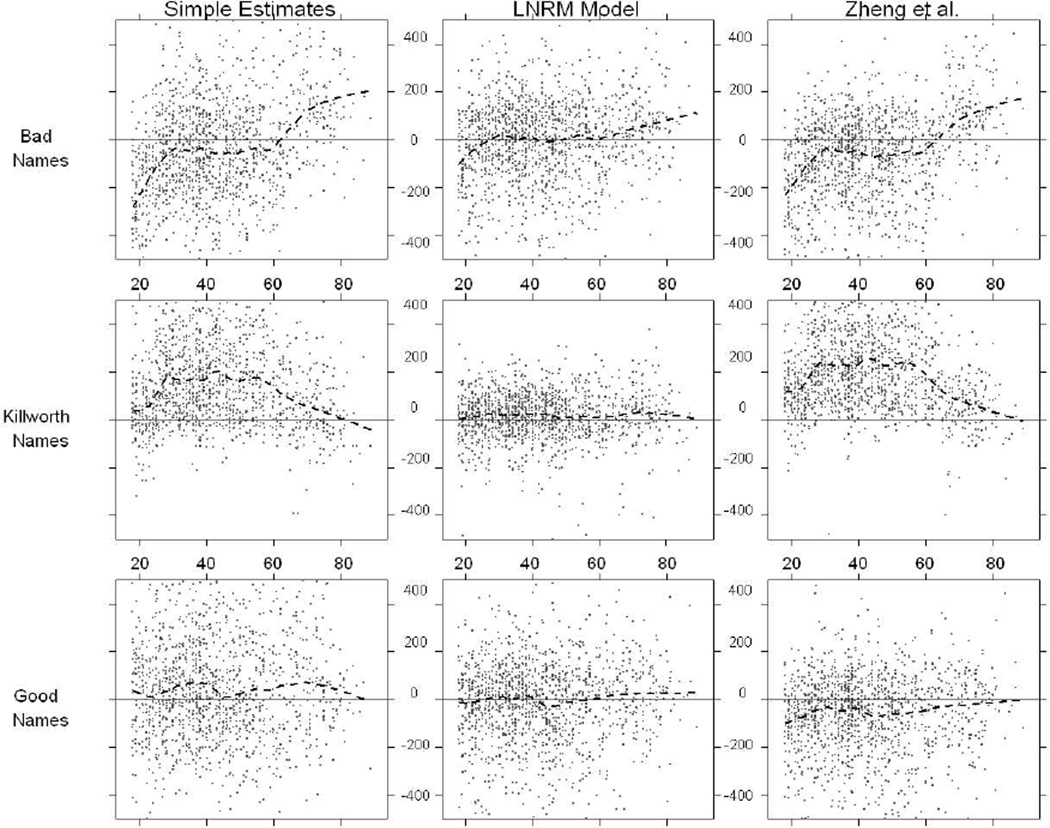
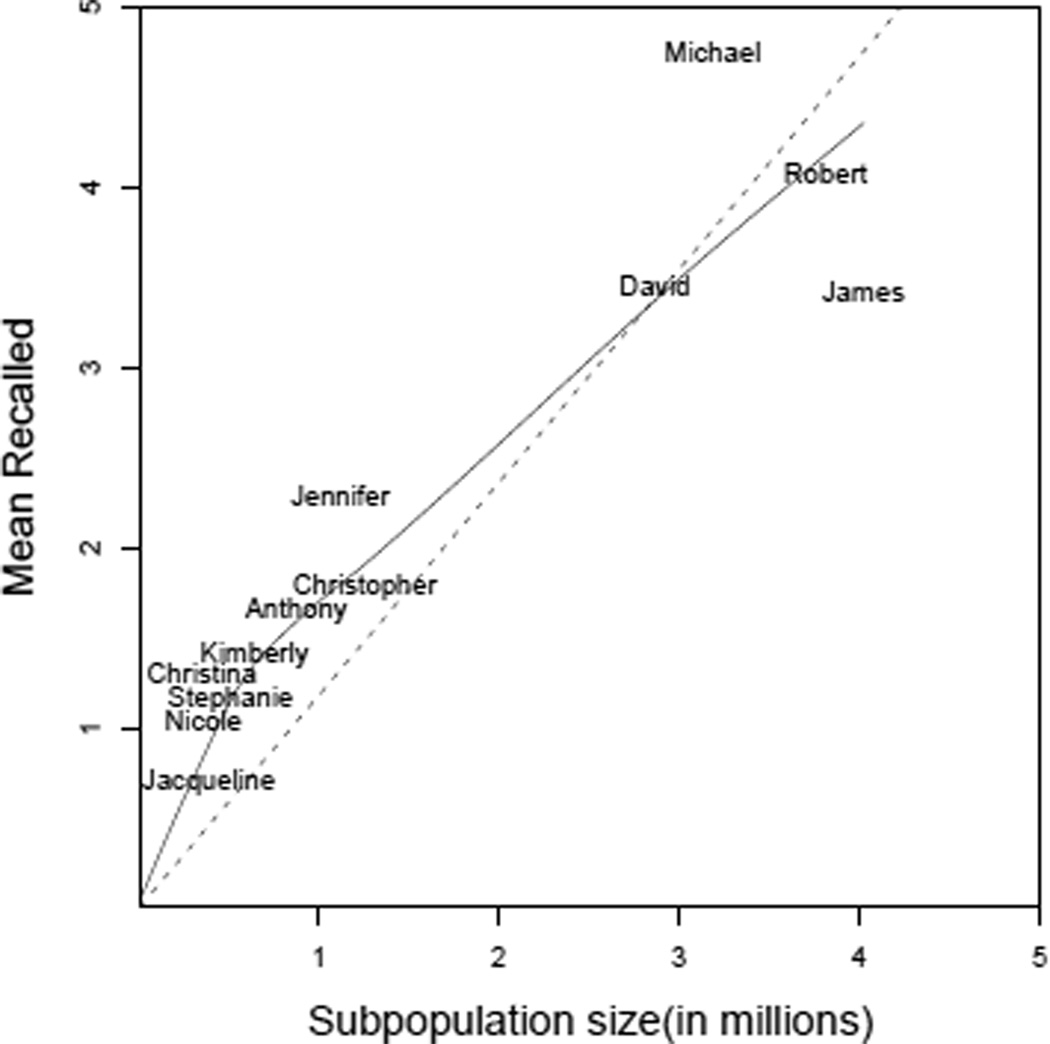
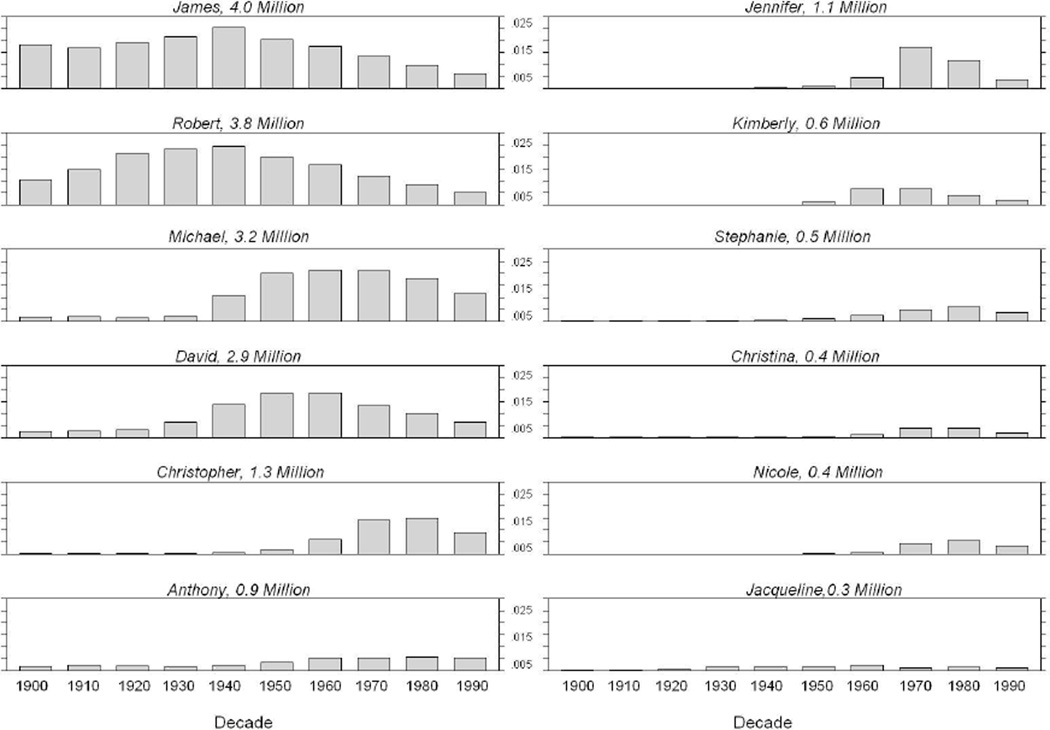
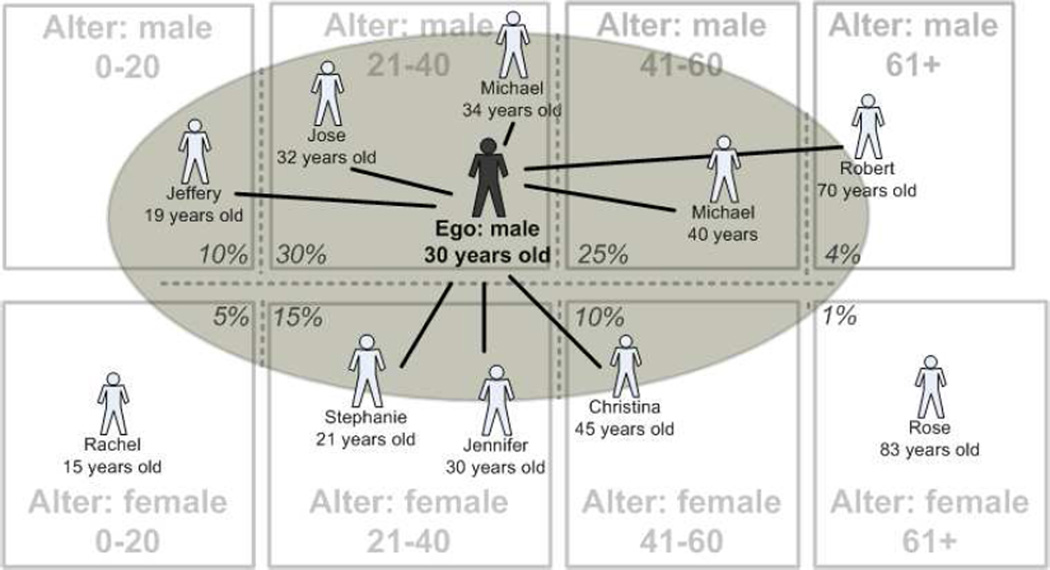
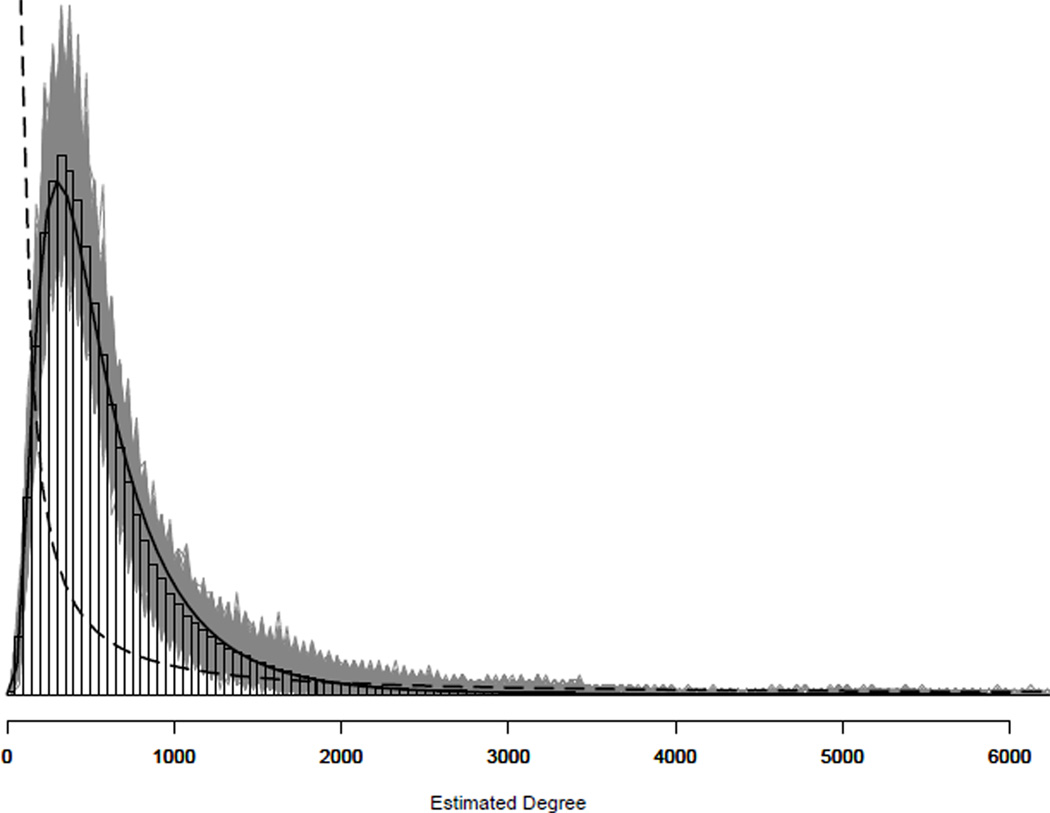
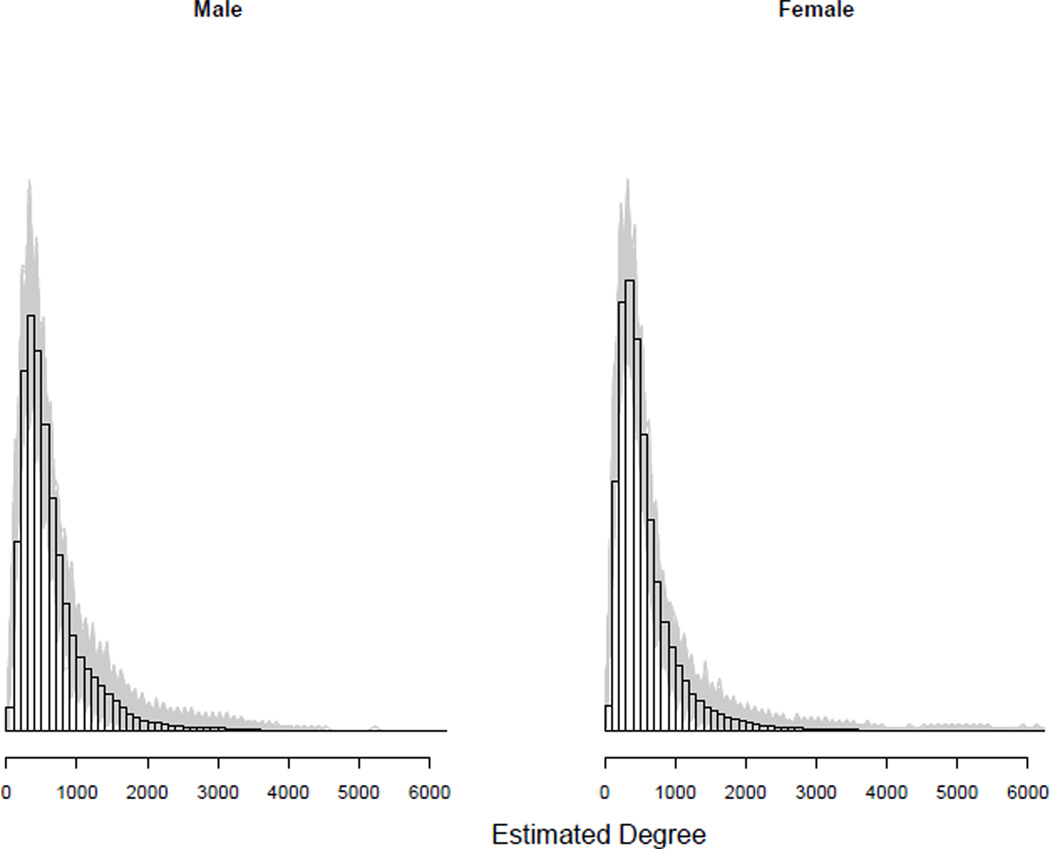
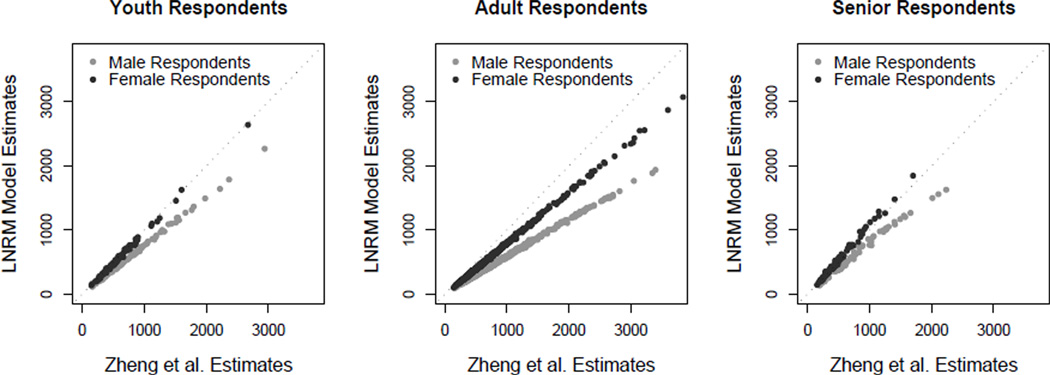
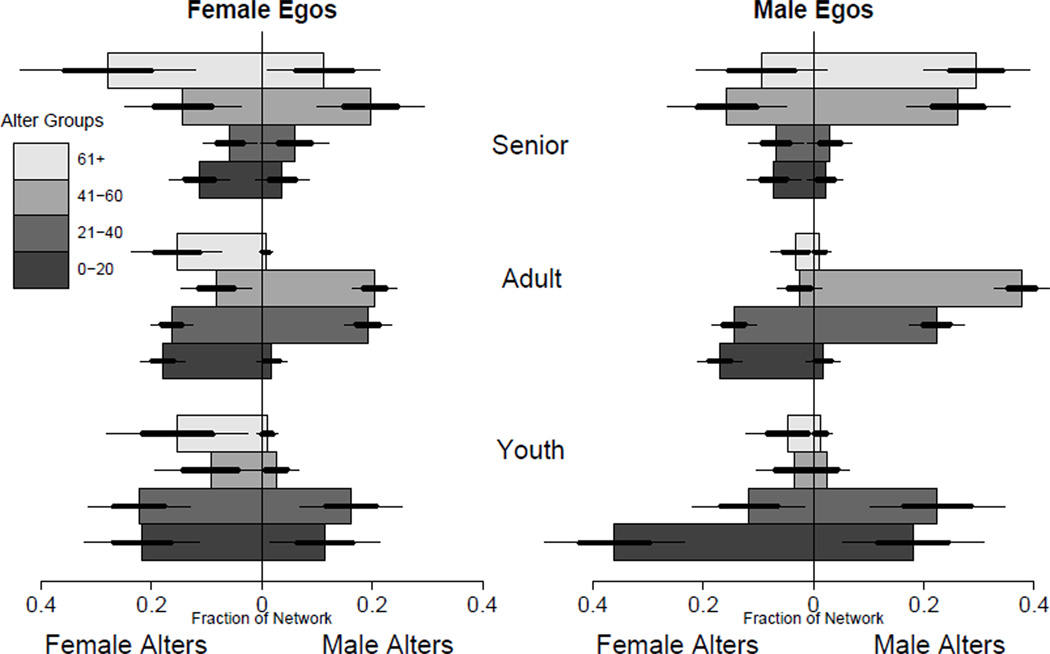
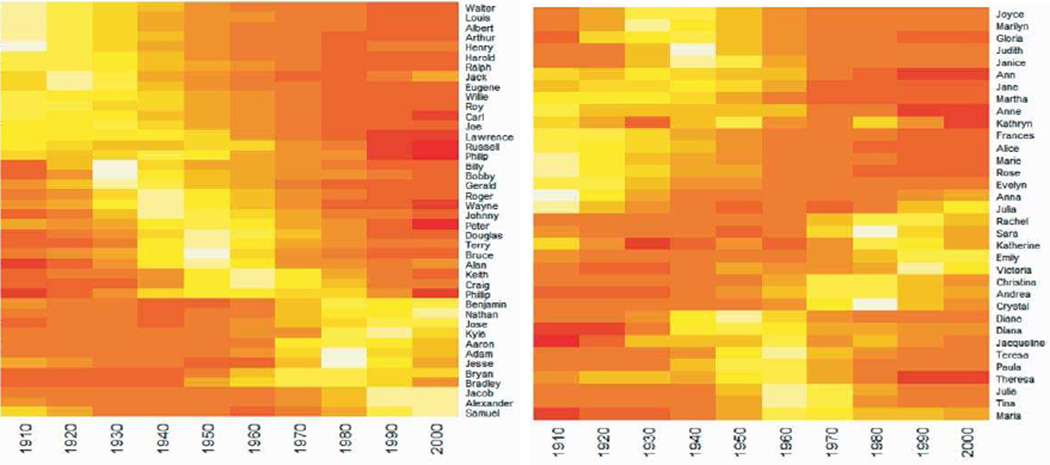
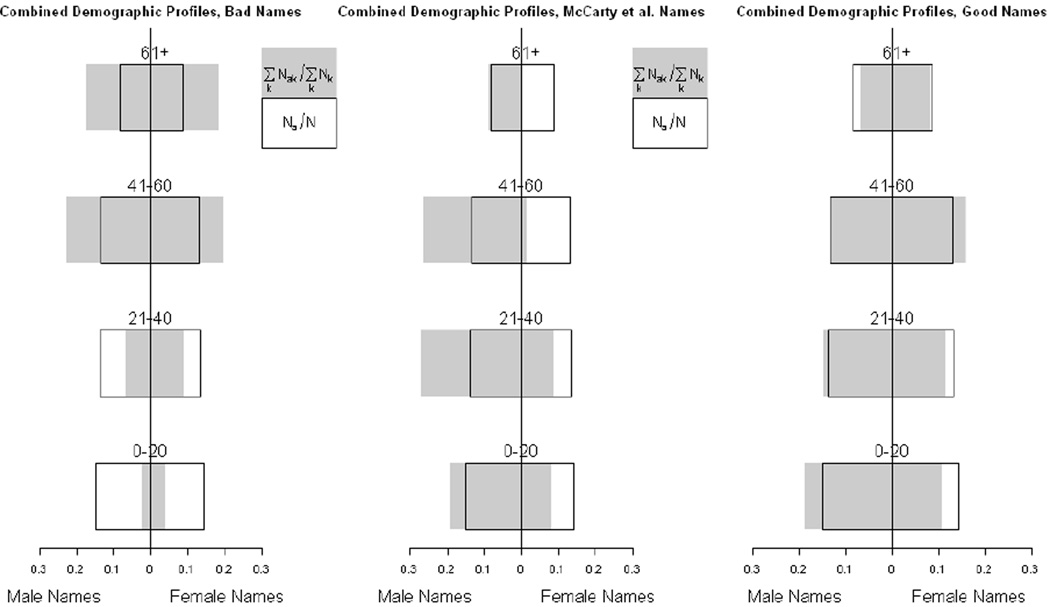
In this paper we develop a method to estimate both individual social network size (i.e., degree) and the distribution of network sizes in a population by asking respondents how many people they know in specific subpopulations (e.g., people named Michael). Building on the scale-up method of Killworth et al. (1998b) and other previous attempts to estimate individual network size, we propose a latent non-random mixing model which resolves three known problems with previous approaches. As a byproduct, our method also provides estimates of the rate of social mixing between population groups. We demonstrate the model using a sample of 1,370 adults originally collected by McCarty et al. (2001). Based on insights developed during the statistical modeling, we conclude by offering practical guidelines for the design of future surveys to estimate social network size. Most importantly, we show that if the first names to be asked about are chosen properly, the simple scale-up degree estimates can enjoy the same bias-reduction as that from the our more complex latent non-random mixing model.
在本文中,我们开发了一种方法,通过询问受访者他们在特定亚群体(例如叫迈克尔的人)中认识多少人,来估计个体社交网络规模(即度数)以及总体中网络规模的分布。基于基尔沃思等人(1998b)的放大法以及之前其他估计个体网络规模的尝试,我们提出了一种潜在非随机混合模型,该模型解决了先前方法存在的三个已知问题。作为副产品,我们的方法还提供了不同人群群体之间社交混合率的估计值。我们使用麦卡蒂等人(2001)最初收集的1370名成年人样本对该模型进行了演示。基于统计建模过程中获得的见解,我们最后为未来估计社交网络规模的调查设计提供了实用指南。最重要的是,我们表明,如果所询问的名字选择得当,简单的放大度数估计可以与我们更复杂的潜在非随机混合模型一样减少偏差。