Mouse Genomics Resource Laboratory, National Institute of Genetics, Mishima, Shizuoka 411-8540, Japan.
BMC Genomics. 2013 Jul 8;14:455. doi: 10.1186/1471-2164-14-455.
Copy number variation (CNV), an important source of diversity in genomic structure, is frequently found in clusters called CNV regions (CNVRs). CNVRs are strongly associated with segmental duplications (SDs), but the composition of these complex repetitive structures remains unclear.
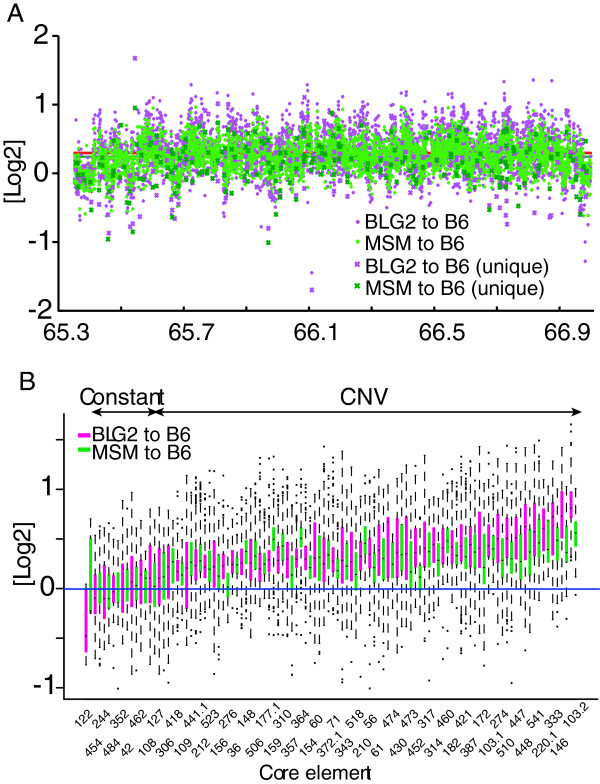
We conducted self-comparative-plot analysis of all mouse chromosomes using the high-speed and large-scale-homology search algorithm SHEAP. For eight chromosomes, we identified various types of large SD as tartan-checked patterns within the self-comparative plots. A complex arrangement of diagonal split lines in the self-comparative-plots indicated the presence of large homologous repetitive sequences. We focused on one SD on chromosome 13 (SD13M), and developed SHEPHERD, a stepwise ab initio method, to extract longer repetitive elements and to characterize repetitive structures in this region. Analysis using SHEPHERD showed the existence of 60 core elements, which were expected to be the basic units that form SDs within the repetitive structure of SD13M. The demonstration that sequences homologous to the core elements (>70% homology) covered approximately 90% of the SD13M region indicated that our method can characterize the repetitive structure of SD13M effectively. Core elements were composed largely of fragmented repeats of a previously identified type, such as long interspersed nuclear elements (LINEs), together with partial genic regions. Comparative genome hybridization array analysis showed that whereas 42 core elements were components of CNVR that varied among mouse strains, 8 did not vary among strains (constant type), and the status of the others could not be determined. The CNV-type core elements contained significantly larger proportions of long terminal repeat (LTR) types of retrotransposon than the constant-type core elements, which had no CNV. The higher divergence rates observed in the CNV-type core elements than in the constant type indicate that the CNV-type core elements have a longer evolutionary history than constant-type core elements in SD13M.
Our methodology for the identification of repetitive core sequences simplifies characterization of the structures of large SDs and detailed analysis of CNV. The results of detailed structural and quantitative analyses in this study might help to elucidate the biological role of one of the SDs on chromosome 13.
拷贝数变异(CNV)是基因组结构多样性的一个重要来源,经常以称为 CNV 区域(CNVR)的簇的形式出现。CNVR 与片段重复(SD)强烈相关,但这些复杂重复结构的组成仍不清楚。
我们使用高速、大规模同源搜索算法 SHEAP 对所有小鼠染色体进行了自我比较图谱分析。对于 8 条染色体,我们在自我比较图谱中发现了各种类型的大型 SD,呈现出格子状图案。自我比较图谱中对角线分裂线的复杂排列表明存在大型同源重复序列。我们关注的是 13 号染色体上的一个 SD(SD13M),并开发了 SHEPHERD,一种逐步从头开始的方法,用于提取更长的重复元件,并对该区域的重复结构进行特征描述。使用 SHEPHERD 进行的分析表明,存在 60 个核心元件,这些元件预计是形成 SD13M 重复结构内 SD 的基本单位。序列与核心元件(>70%同源性)的同源性覆盖了大约 90%的 SD13M 区域的事实表明,我们的方法可以有效地描述 SD13M 的重复结构。核心元件主要由先前确定的类型(如长散布核元件(LINEs))的碎片重复以及部分基因区域组成。比较基因组杂交微阵列分析表明,虽然 42 个核心元件是不同小鼠品系之间 CNVR 的组成部分,但 8 个核心元件在品系之间没有差异(恒定类型),其他核心元件的状态无法确定。CNV 型核心元件包含的长末端重复(LTR)反转录转座子类型比例明显高于无 CNV 的恒定型核心元件。在 CNV 型核心元件中观察到的更高的分歧率表明,CNV 型核心元件在 SD13M 中的进化历史比恒定型核心元件更长。
我们用于识别重复核心序列的方法简化了大型 SD 结构的特征描述和 CNV 的详细分析。本研究详细的结构和定量分析结果可能有助于阐明 13 号染色体上的一个 SD 的生物学作用。