Heath Allison P, Greenway Matthew, Powell Raymond, Spring Jonathan, Suarez Rafael, Hanley David, Bandlamudi Chai, McNerney Megan E, White Kevin P, Grossman Robert L
Institute for Genomics and Systems Biology, University of Chicago, Chicago, Illinois, USA.
Institute for Genomics and Systems Biology, University of Chicago, Chicago, Illinois, USA Department of Pathology, University of Chicago, Chicago, Illinois, USA.
J Am Med Inform Assoc. 2014 Nov-Dec;21(6):969-75. doi: 10.1136/amiajnl-2013-002155. Epub 2014 Jan 24.
As large genomics and phenotypic datasets are becoming more common, it is increasingly difficult for most researchers to access, manage, and analyze them. One possible approach is to provide the research community with several petabyte-scale cloud-based computing platforms containing these data, along with tools and resources to analyze it.
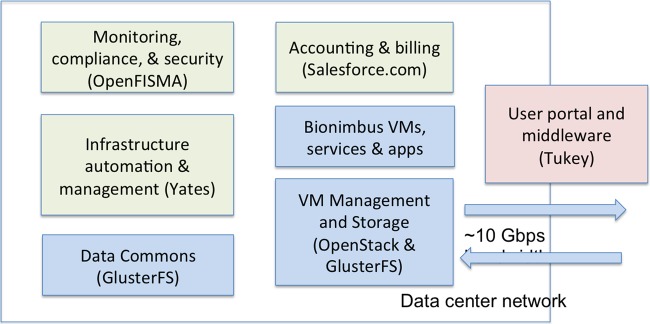
Bionimbus is an open source cloud-computing platform that is based primarily upon OpenStack, which manages on-demand virtual machines that provide the required computational resources, and GlusterFS, which is a high-performance clustered file system. Bionimbus also includes Tukey, which is a portal, and associated middleware that provides a single entry point and a single sign on for the various Bionimbus resources; and Yates, which automates the installation, configuration, and maintenance of the software infrastructure required.
Bionimbus is used by a variety of projects to process genomics and phenotypic data. For example, it is used by an acute myeloid leukemia resequencing project at the University of Chicago. The project requires several computational pipelines, including pipelines for quality control, alignment, variant calling, and annotation. For each sample, the alignment step requires eight CPUs for about 12 h. BAM file sizes ranged from 5 GB to 10 GB for each sample.
Most members of the research community have difficulty downloading large genomics datasets and obtaining sufficient storage and computer resources to manage and analyze the data. Cloud computing platforms, such as Bionimbus, with data commons that contain large genomics datasets, are one choice for broadening access to research data in genomics.
随着大型基因组学和表型数据集越来越普遍,大多数研究人员获取、管理和分析这些数据集变得越来越困难。一种可能的方法是为研究界提供几个包含这些数据的PB级基于云计算的平台,以及用于分析数据的工具和资源。
Bionimbus是一个开源云计算平台,主要基于OpenStack(管理按需提供所需计算资源的虚拟机)和GlusterFS(一种高性能集群文件系统)。Bionimbus还包括Tukey(一个门户)和相关的中间件,它为各种Bionimbus资源提供单一入口点和单点登录;以及Yates,它能自动安装、配置和维护所需的软件基础设施。
Bionimbus被多个项目用于处理基因组学和表型数据。例如,芝加哥大学的一个急性髓系白血病重测序项目使用了它。该项目需要几个计算流程,包括质量控制、比对、变异检测和注释流程。对于每个样本,比对步骤需要8个CPU运行约12小时。每个样本的BAM文件大小在5GB到10GB之间。
研究界的大多数成员在下载大型基因组学数据集以及获得足够的存储和计算机资源来管理和分析数据方面存在困难。像Bionimbus这样拥有包含大型基因组学数据集的数据共享库的云计算平台,是拓宽基因组学研究数据获取途径的一种选择。